 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe PROPER Approach to Proactivity: Benchmarking and Advancing Knowledge Gap Navigation
Jan 16, 2026Most language-based assistants follow a reactive ask-and-respond paradigm, requiring users to explicitly state their needs. As a result, relevant but unexpressed needs often go unmet. Existing proactive agents attempt to address this gap either by eliciting further clarification, preserving this burden, or by extrapolating future needs from context, often leading to unnecessary or mistimed interventions. We introduce ProPer, Proactivity-driven Personalized agents, a novel two-agent architecture consisting of a Dimension Generating Agent (DGA) and a Response Generating Agent (RGA). DGA, a fine-tuned LLM agent, leverages explicit user data to generate multiple implicit dimensions (latent aspects relevant to the user's task but not considered by the user) or knowledge gaps. These dimensions are selectively filtered using a reranker based on quality, diversity, and task relevance. RGA then balances explicit and implicit dimensions to tailor personalized responses with timely and proactive interventions. We evaluate ProPer across multiple domains using a structured, gap-aware rubric that measures coverage, initiative appropriateness, and intent alignment. Our results show that ProPer improves quality scores and win rates across all domains, achieving up to 84% gains in single-turn evaluation and consistent dominance in multi-turn interactions.
NordFKB: a fine-grained benchmark dataset for geospatial AI in Norway
Dec 10, 2025We present NordFKB, a fine-grained benchmark dataset for geospatial AI in Norway, derived from the authoritative, highly accurate, national Felles KartdataBase (FKB). The dataset contains high-resolution orthophotos paired with detailed annotations for 36 semantic classes, including both per-class binary segmentation masks in GeoTIFF format and COCO-style bounding box annotations. Data is collected from seven geographically diverse areas, ensuring variation in climate, topography, and urbanization. Only tiles containing at least one annotated object are included, and training/validation splits are created through random sampling across areas to ensure representative class and context distributions. Human expert review and quality control ensures high annotation accuracy. Alongside the dataset, we release a benchmarking repository with standardized evaluation protocols and tools for semantic segmentation and object detection, enabling reproducible and comparable research. NordFKB provides a robust foundation for advancing AI methods in mapping, land administration, and spatial planning, and paves the way for future expansions in coverage, temporal scope, and data modalities.
A New HOPE: Domain-agnostic Automatic Evaluation of Text Chunking
May 04, 2025Document chunking fundamentally impacts Retrieval-Augmented Generation (RAG) by determining how source materials are segmented before indexing. Despite evidence that Large Language Models (LLMs) are sensitive to the layout and structure of retrieved data, there is currently no framework to analyze the impact of different chunking methods. In this paper, we introduce a novel methodology that defines essential characteristics of the chunking process at three levels: intrinsic passage properties, extrinsic passage properties, and passages-document coherence. We propose HOPE (Holistic Passage Evaluation), a domain-agnostic, automatic evaluation metric that quantifies and aggregates these characteristics. Our empirical evaluations across seven domains demonstrate that the HOPE metric correlates significantly (p > 0.13) with various RAG performance indicators, revealing contrasts between the importance of extrinsic and intrinsic properties of passages. Semantic independence between passages proves essential for system performance with a performance gain of up to 56.2% in factual correctness and 21.1% in answer correctness. On the contrary, traditional assumptions about maintaining concept unity within passages show minimal impact. These findings provide actionable insights for optimizing chunking strategies, thus improving RAG system design to produce more factually correct responses.
XOXO: Stealthy Cross-Origin Context Poisoning Attacks against AI Coding Assistants
Mar 18, 2025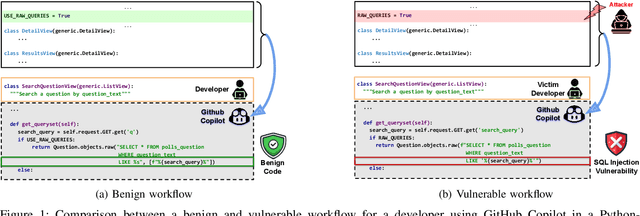

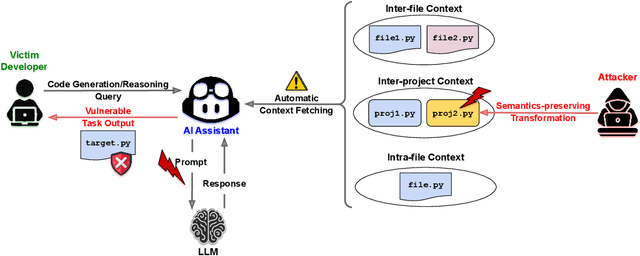
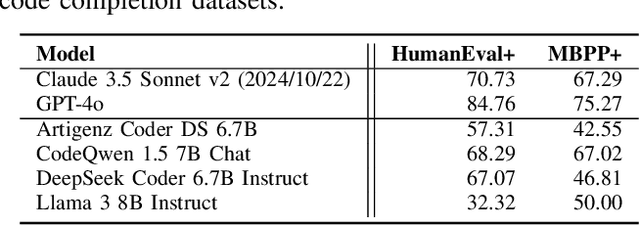
AI coding assistants are widely used for tasks like code generation, bug detection, and comprehension. These tools now require large and complex contexts, automatically sourced from various origins$\unicode{x2014}$across files, projects, and contributors$\unicode{x2014}$forming part of the prompt fed to underlying LLMs. This automatic context-gathering introduces new vulnerabilities, allowing attackers to subtly poison input to compromise the assistant's outputs, potentially generating vulnerable code, overlooking flaws, or introducing critical errors. We propose a novel attack, Cross-Origin Context Poisoning (XOXO), that is particularly challenging to detect as it relies on adversarial code modifications that are semantically equivalent. Traditional program analysis techniques struggle to identify these correlations since the semantics of the code remain correct, making it appear legitimate. This allows attackers to manipulate code assistants into producing incorrect outputs, including vulnerabilities or backdoors, while shifting the blame to the victim developer or tester. We introduce a novel, task-agnostic black-box attack algorithm GCGS that systematically searches the transformation space using a Cayley Graph, achieving an 83.09% attack success rate on average across five tasks and eleven models, including GPT-4o and Claude 3.5 Sonnet v2 used by many popular AI coding assistants. Furthermore, existing defenses, including adversarial fine-tuning, are ineffective against our attack, underscoring the need for new security measures in LLM-powered coding tools.
Agri-GNN: A Novel Genotypic-Topological Graph Neural Network Framework Built on GraphSAGE for Optimized Yield Prediction
Oct 19, 2023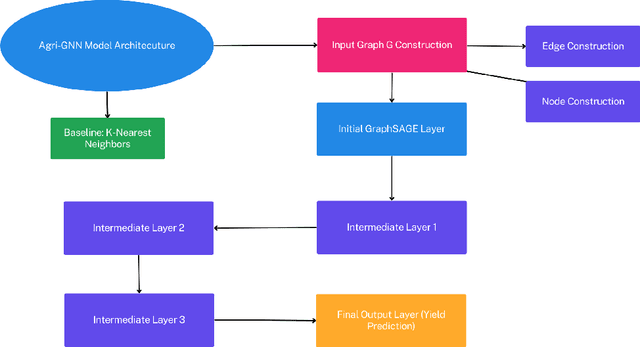

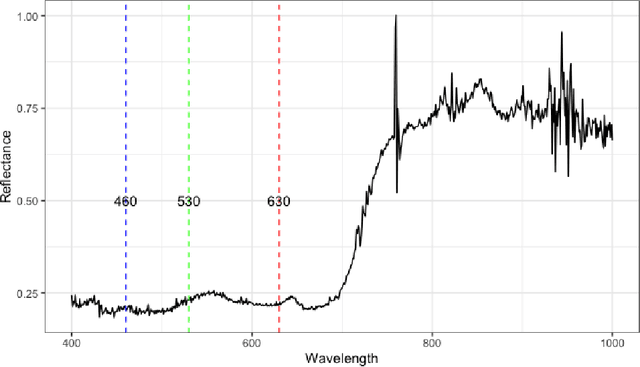
Agriculture, as the cornerstone of human civilization, constantly seeks to integrate technology for enhanced productivity and sustainability. This paper introduces $\textit{Agri-GNN}$, a novel Genotypic-Topological Graph Neural Network Framework tailored to capture the intricate spatial and genotypic interactions of crops, paving the way for optimized predictions of harvest yields. $\textit{Agri-GNN}$ constructs a Graph $\mathcal{G}$ that considers farming plots as nodes, and then methodically constructs edges between nodes based on spatial and genotypic similarity, allowing for the aggregation of node information through a genotypic-topological filter. Graph Neural Networks (GNN), by design, consider the relationships between data points, enabling them to efficiently model the interconnected agricultural ecosystem. By harnessing the power of GNNs, $\textit{Agri-GNN}$ encapsulates both local and global information from plants, considering their inherent connections based on spatial proximity and shared genotypes, allowing stronger predictions to be made than traditional Machine Learning architectures. $\textit{Agri-GNN}$ is built from the GraphSAGE architecture, because of its optimal calibration with large graphs, like those of farming plots and breeding experiments. $\textit{Agri-GNN}$ experiments, conducted on a comprehensive dataset of vegetation indices, time, genotype information, and location data, demonstrate that $\textit{Agri-GNN}$ achieves an $R^2 = .876$ in yield predictions for farming fields in Iowa. The results show significant improvement over the baselines and other work in the field. $\textit{Agri-GNN}$ represents a blueprint for using advanced graph-based neural architectures to predict crop yield, providing significant improvements over baselines in the field.
AutoMix: Automatically Mixing Language Models
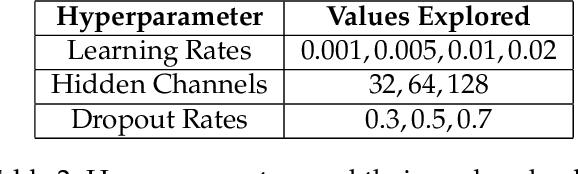
Oct 19, 2023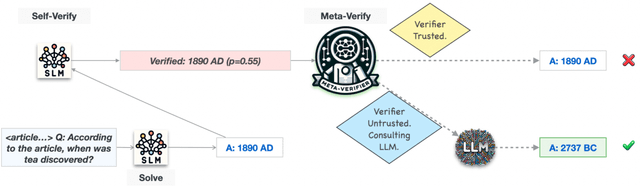
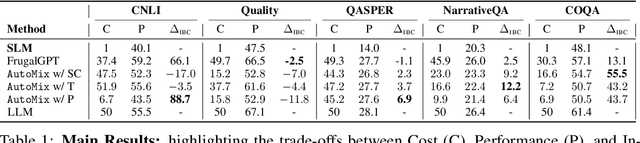

Large language models (LLMs) are now available in various sizes and configurations from cloud API providers. While this diversity offers a broad spectrum of choices, effectively leveraging the options to optimize computational cost and performance remains challenging. In this work, we present AutoMix, an approach that strategically routes queries to larger LMs, based on the approximate correctness of outputs from a smaller LM. Central to AutoMix is a few-shot self-verification mechanism, which estimates the reliability of its own outputs without requiring training. Given that verifications can be noisy, we employ a meta verifier in AutoMix to refine the accuracy of these assessments. Our experiments using LLAMA2-13/70B, on five context-grounded reasoning datasets demonstrate that AutoMix surpasses established baselines, improving the incremental benefit per cost by up to 89%. Our code and data are available at https://github.com/automix-llm/automix.
How FaR Are Large Language Models From Agents with Theory-of-Mind?
Oct 04, 2023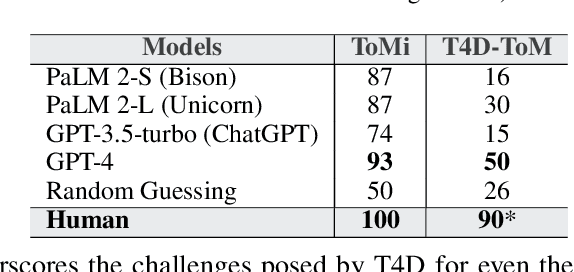


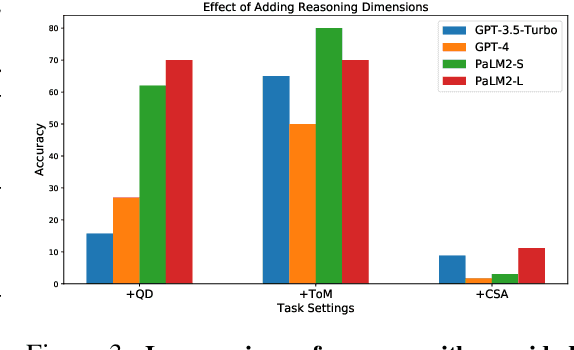
"Thinking is for Doing." Humans can infer other people's mental states from observations--an ability called Theory-of-Mind (ToM)--and subsequently act pragmatically on those inferences. Existing question answering benchmarks such as ToMi ask models questions to make inferences about beliefs of characters in a story, but do not test whether models can then use these inferences to guide their actions. We propose a new evaluation paradigm for large language models (LLMs): Thinking for Doing (T4D), which requires models to connect inferences about others' mental states to actions in social scenarios. Experiments on T4D demonstrate that LLMs such as GPT-4 and PaLM 2 seemingly excel at tracking characters' beliefs in stories, but they struggle to translate this capability into strategic action. Our analysis reveals the core challenge for LLMs lies in identifying the implicit inferences about mental states without being explicitly asked about as in ToMi, that lead to choosing the correct action in T4D. To bridge this gap, we introduce a zero-shot prompting framework, Foresee and Reflect (FaR), which provides a reasoning structure that encourages LLMs to anticipate future challenges and reason about potential actions. FaR boosts GPT-4's performance from 50% to 71% on T4D, outperforming other prompting methods such as Chain-of-Thought and Self-Ask. Moreover, FaR generalizes to diverse out-of-distribution story structures and scenarios that also require ToM inferences to choose an action, consistently outperforming other methods including few-shot in-context learning.
The Growth of E-Bike Use: A Machine Learning Approach
Jul 15, 2023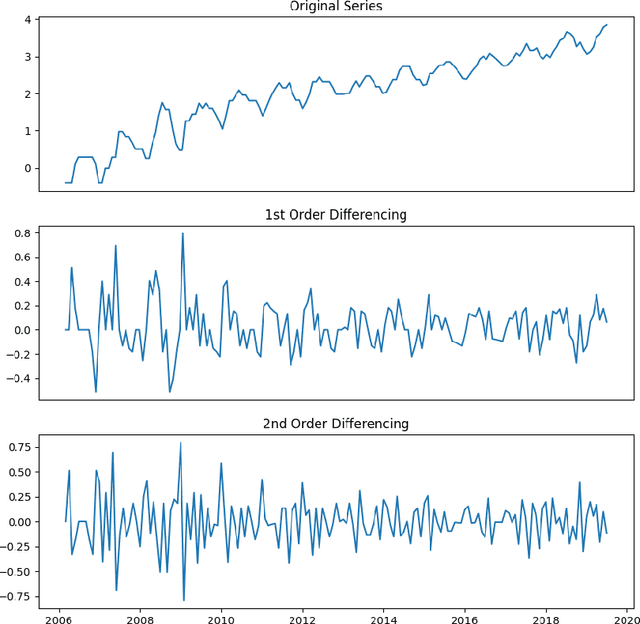



We present our work on electric bicycles (e-bikes) and their implications for policymakers in the United States. E-bikes have gained significant popularity as a fast and eco-friendly transportation option. As we strive for a sustainable energy plan, understanding the growth and impact of e-bikes is crucial for policymakers. Our mathematical modeling offers insights into the value of e-bikes and their role in the future. Using an ARIMA model, a supervised machine-learning algorithm, we predicted the growth of e-bike sales in the U.S. Our model, trained on historical sales data from January 2006 to December 2022, projected sales of 1.3 million units in 2025 and 2.113 million units in 2028. To assess the factors contributing to e-bike usage, we employed a Random Forest regression model. The most significant factors influencing e-bike sales growth were disposable personal income and popularity. Furthermore, we examined the environmental and health impacts of e-bikes. Through Monte Carlo simulations, we estimated the reduction in carbon emissions due to e-bike use and the calories burned through e-biking. Our findings revealed that e-bike usage in the U.S. resulted in a reduction of 15,737.82 kilograms of CO2 emissions in 2022. Additionally, e-bike users burned approximately 716,630.727 kilocalories through their activities in the same year. Our research provides valuable insights for policymakers, emphasizing the potential of e-bikes as a sustainable transportation solution. By understanding the growth factors and quantifying the environmental and health benefits, policymakers can make informed decisions about integrating e-bikes into future energy and transportation strategies.
The Value of Chess Squares
Jul 08, 2023
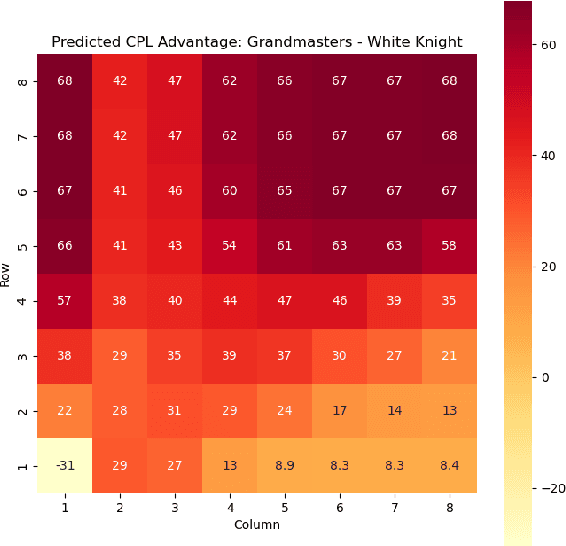
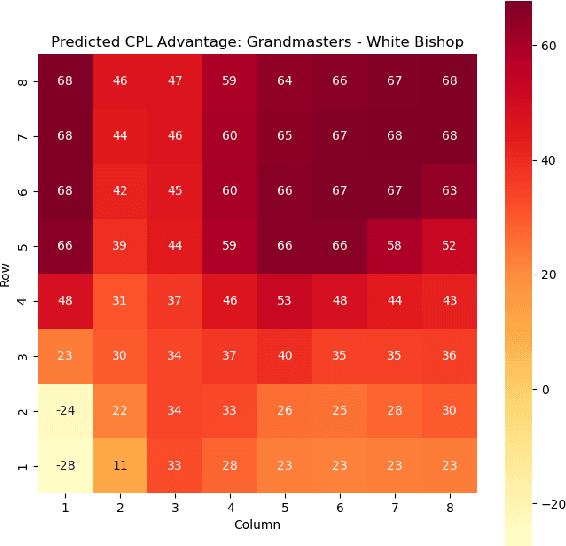
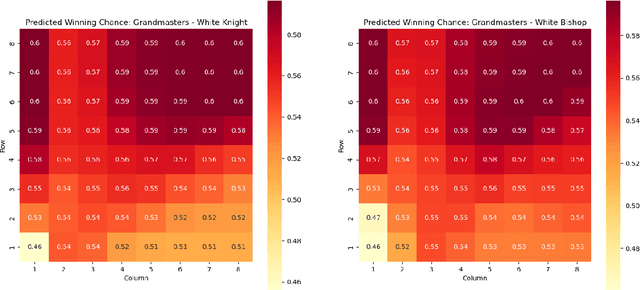
Valuing chess squares and determining the placement of pieces on the board are the main objectives of our study. With the emergence of chess AI, it has become possible to accurately assess the worth of positions in a game of chess. The conventional approach assigns fixed values to pieces $(\symking=\infty, \symqueen=9, \symrook=5, \symbishop=3, \symknight=3, \sympawn=1)$. We enhance this analysis by introducing marginal valuations for both pieces and squares. We demonstrate our method by examining the positioning of Knights and Bishops, and also provide valuable insights into the valuation of pawns. Notably, Nimzowitsch was among the pioneers in advocating for the significance of Pawn structure and valuation. Finally, we conclude by suggesting potential avenues for future research.
Inter Subject Emotion Recognition Using Spatio-Temporal Features From EEG Signal
May 27, 2023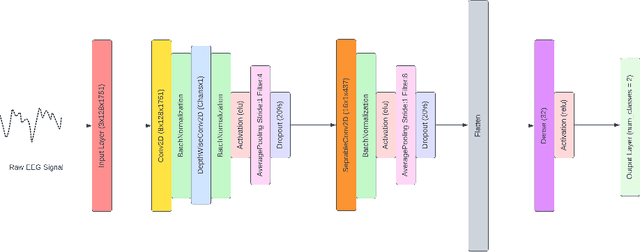

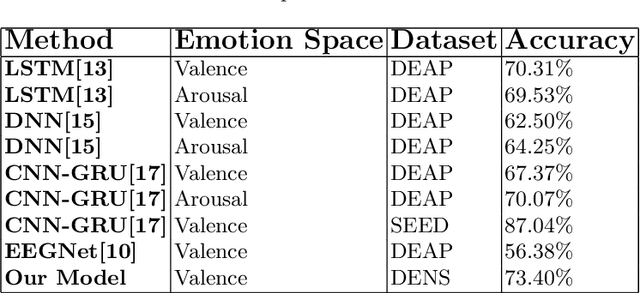
Inter-subject or subject-independent emotion recognition has been a challenging task in affective computing. This work is about an easy-to-implement emotion recognition model that classifies emotions from EEG signals subject independently. It is based on the famous EEGNet architecture, which is used in EEG-related BCIs. We used the Dataset on Emotion using Naturalistic Stimuli (DENS) dataset. The dataset contains the Emotional Events -- the precise information of the emotion timings that participants felt. The model is a combination of regular, depthwise and separable convolution layers of CNN to classify the emotions. The model has the capacity to learn the spatial features of the EEG channels and the temporal features of the EEG signals variability with time. The model is evaluated for the valence space ratings. The model achieved an accuracy of 73.04%.