 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSuperF: Neural Implicit Fields for Multi-Image Super-Resolution
Dec 09, 2025High-resolution imagery is often hindered by limitations in sensor technology, atmospheric conditions, and costs. Such challenges occur in satellite remote sensing, but also with handheld cameras, such as our smartphones. Hence, super-resolution aims to enhance the image resolution algorithmically. Since single-image super-resolution requires solving an inverse problem, such methods must exploit strong priors, e.g. learned from high-resolution training data, or be constrained by auxiliary data, e.g. by a high-resolution guide from another modality. While qualitatively pleasing, such approaches often lead to "hallucinated" structures that do not match reality. In contrast, multi-image super-resolution (MISR) aims to improve the (optical) resolution by constraining the super-resolution process with multiple views taken with sub-pixel shifts. Here, we propose SuperF, a test-time optimization approach for MISR that leverages coordinate-based neural networks, also called neural fields. Their ability to represent continuous signals with an implicit neural representation (INR) makes them an ideal fit for the MISR task. The key characteristic of our approach is to share an INR for multiple shifted low-resolution frames and to jointly optimize the frame alignment with the INR. Our approach advances related INR baselines, adopted from burst fusion for layer separation, by directly parameterizing the sub-pixel alignment as optimizable affine transformation parameters and by optimizing via a super-sampled coordinate grid that corresponds to the output resolution. Our experiments yield compelling results on simulated bursts of satellite imagery and ground-level images from handheld cameras, with upsampling factors of up to 8. A key advantage of SuperF is that this approach does not rely on any high-resolution training data.
Knowledge-Informed Automatic Feature Extraction via Collaborative Large Language Model Agents
Nov 19, 2025The performance of machine learning models on tabular data is critically dependent on high-quality feature engineering. While Large Language Models (LLMs) have shown promise in automating feature extraction (AutoFE), existing methods are often limited by monolithic LLM architectures, simplistic quantitative feedback, and a failure to systematically integrate external domain knowledge. This paper introduces Rogue One, a novel, LLM-based multi-agent framework for knowledge-informed automatic feature extraction. Rogue One operationalizes a decentralized system of three specialized agents-Scientist, Extractor, and Tester-that collaborate iteratively to discover, generate, and validate predictive features. Crucially, the framework moves beyond primitive accuracy scores by introducing a rich, qualitative feedback mechanism and a "flooding-pruning" strategy, allowing it to dynamically balance feature exploration and exploitation. By actively incorporating external knowledge via an integrated retrieval-augmented (RAG) system, Rogue One generates features that are not only statistically powerful but also semantically meaningful and interpretable. We demonstrate that Rogue One significantly outperforms state-of-the-art methods on a comprehensive suite of 19 classification and 9 regression datasets. Furthermore, we show qualitatively that the system surfaces novel, testable hypotheses, such as identifying a new potential biomarker in the myocardial dataset, underscoring its utility as a tool for scientific discovery.
A Comparative Study of Feature Selection in Tsetlin Machines
Aug 09, 2025Feature Selection (FS) is crucial for improving model interpretability, reducing complexity, and sometimes for enhancing accuracy. The recently introduced Tsetlin machine (TM) offers interpretable clause-based learning, but lacks established tools for estimating feature importance. In this paper, we adapt and evaluate a range of FS techniques for TMs, including classical filter and embedded methods as well as post-hoc explanation methods originally developed for neural networks (e.g., SHAP and LIME) and a novel family of embedded scorers derived from TM clause weights and Tsetlin automaton (TA) states. We benchmark all methods across 12 datasets, using evaluation protocols, like Remove and Retrain (ROAR) strategy and Remove and Debias (ROAD), to assess causal impact. Our results show that TM-internal scorers not only perform competitively but also exploit the interpretability of clauses to reveal interacting feature patterns. Simpler TM-specific scorers achieve similar accuracy retention at a fraction of the computational cost. This study establishes the first comprehensive baseline for FS in TM and paves the way for developing specialized TM-specific interpretability techniques.
A New HOPE: Domain-agnostic Automatic Evaluation of Text Chunking
May 04, 2025Document chunking fundamentally impacts Retrieval-Augmented Generation (RAG) by determining how source materials are segmented before indexing. Despite evidence that Large Language Models (LLMs) are sensitive to the layout and structure of retrieved data, there is currently no framework to analyze the impact of different chunking methods. In this paper, we introduce a novel methodology that defines essential characteristics of the chunking process at three levels: intrinsic passage properties, extrinsic passage properties, and passages-document coherence. We propose HOPE (Holistic Passage Evaluation), a domain-agnostic, automatic evaluation metric that quantifies and aggregates these characteristics. Our empirical evaluations across seven domains demonstrate that the HOPE metric correlates significantly (p > 0.13) with various RAG performance indicators, revealing contrasts between the importance of extrinsic and intrinsic properties of passages. Semantic independence between passages proves essential for system performance with a performance gain of up to 56.2% in factual correctness and 21.1% in answer correctness. On the contrary, traditional assumptions about maintaining concept unity within passages show minimal impact. These findings provide actionable insights for optimizing chunking strategies, thus improving RAG system design to produce more factually correct responses.
Exploring Effects of Hyperdimensional Vectors for Tsetlin Machines
Jun 04, 2024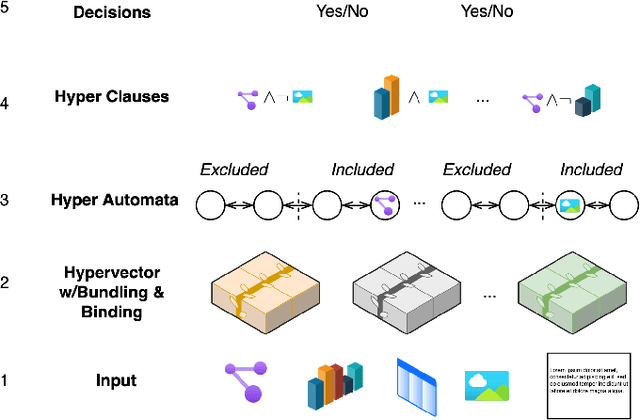
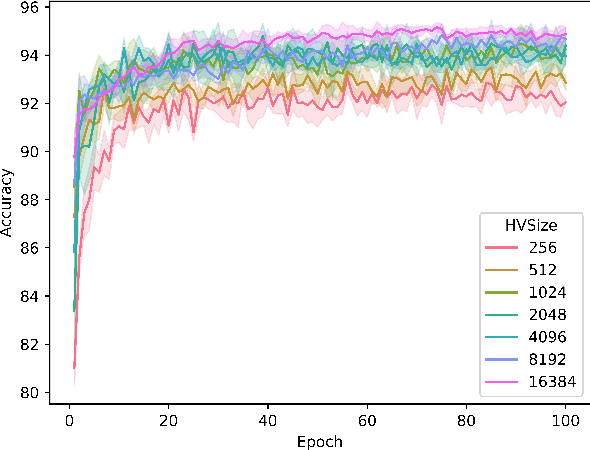
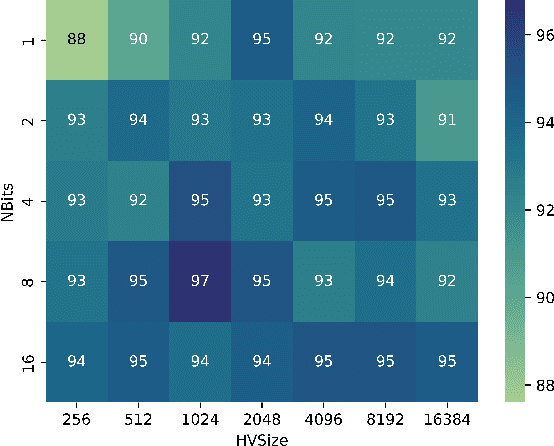
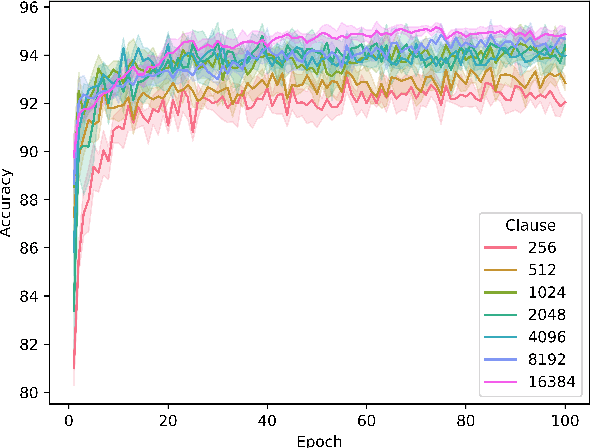
Tsetlin machines (TMs) have been successful in several application domains, operating with high efficiency on Boolean representations of the input data. However, Booleanizing complex data structures such as sequences, graphs, images, signal spectra, chemical compounds, and natural language is not trivial. In this paper, we propose a hypervector (HV) based method for expressing arbitrarily large sets of concepts associated with any input data. Using a hyperdimensional space to build vectors drastically expands the capacity and flexibility of the TM. We demonstrate how images, chemical compounds, and natural language text are encoded according to the proposed method, and how the resulting HV-powered TM can achieve significantly higher accuracy and faster learning on well-known benchmarks. Our results open up a new research direction for TMs, namely how to expand and exploit the benefits of operating in hyperspace, including new booleanization strategies, optimization of TM inference and learning, as well as new TM applications.
Contracting Tsetlin Machine with Absorbing Automata
Oct 17, 2023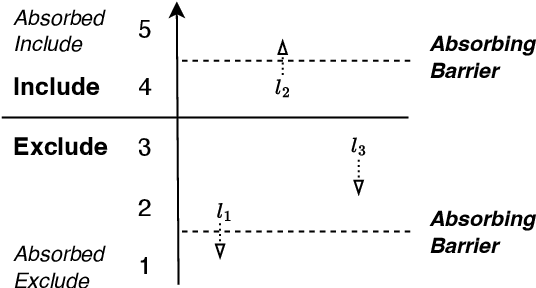
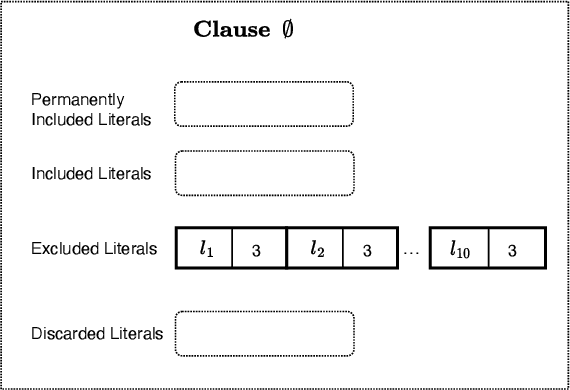
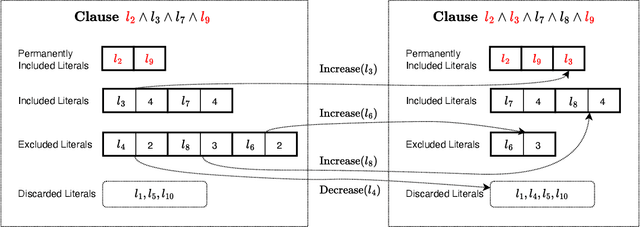
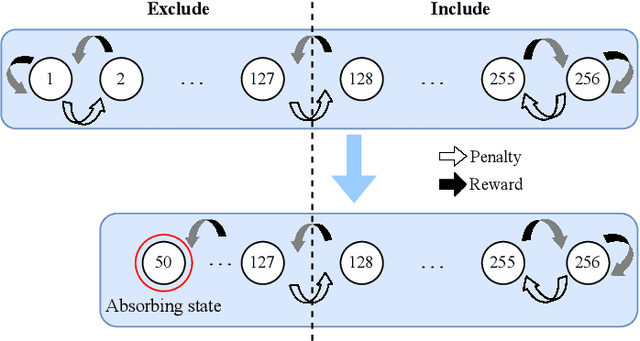
In this paper, we introduce a sparse Tsetlin Machine (TM) with absorbing Tsetlin Automata (TA) states. In brief, the TA of each clause literal has both an absorbing Exclude- and an absorbing Include state, making the learning scheme absorbing instead of ergodic. When a TA reaches an absorbing state, it will never leave that state again. If the absorbing state is an Exclude state, both the automaton and the literal can be removed from further consideration. The literal will as a result never participates in that clause. If the absorbing state is an Include state, on the other hand, the literal is stored as a permanent part of the clause while the TA is discarded. A novel sparse data structure supports these updates by means of three action lists: Absorbed Include, Include, and Exclude. By updating these lists, the TM gets smaller and smaller as the literals and their TA withdraw. In this manner, the computation accelerates during learning, leading to faster learning and less energy consumption.
Generalized Convergence Analysis of Tsetlin Machines: A Probabilistic Approach to Concept Learning
Oct 03, 2023
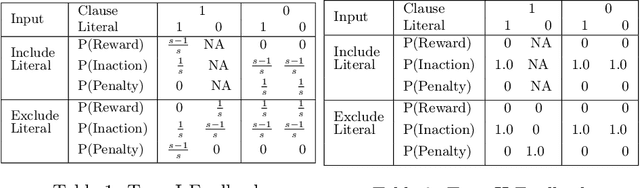
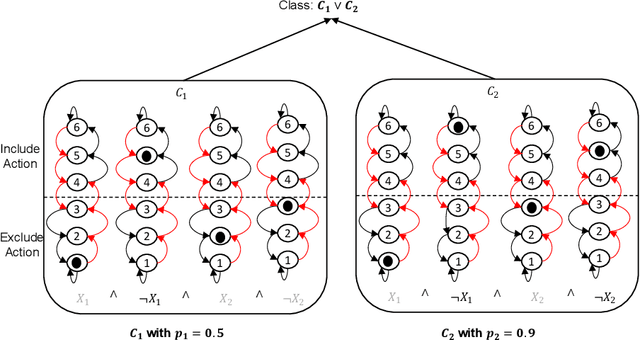
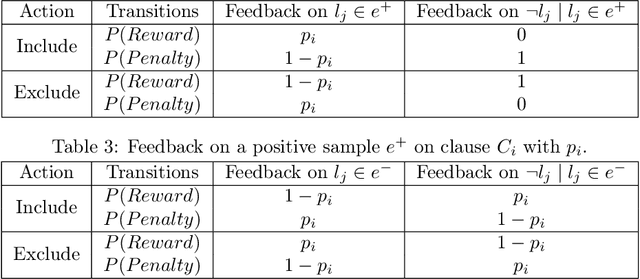
Tsetlin Machines (TMs) have garnered increasing interest for their ability to learn concepts via propositional formulas and their proven efficiency across various application domains. Despite this, the convergence proof for the TMs, particularly for the AND operator (\emph{conjunction} of literals), in the generalized case (inputs greater than two bits) remains an open problem. This paper aims to fill this gap by presenting a comprehensive convergence analysis of Tsetlin automaton-based Machine Learning algorithms. We introduce a novel framework, referred to as Probabilistic Concept Learning (PCL), which simplifies the TM structure while incorporating dedicated feedback mechanisms and dedicated inclusion/exclusion probabilities for literals. Given $n$ features, PCL aims to learn a set of conjunction clauses $C_i$ each associated with a distinct inclusion probability $p_i$. Most importantly, we establish a theoretical proof confirming that, for any clause $C_k$, PCL converges to a conjunction of literals when $0.5<p_k<1$. This result serves as a stepping stone for future research on the convergence properties of Tsetlin automaton-based learning algorithms. Our findings not only contribute to the theoretical understanding of Tsetlin Machines but also have implications for their practical application, potentially leading to more robust and interpretable machine learning models.
Learning Minimalistic Tsetlin Machine Clauses with Markov Boundary-Guided Pruning
Sep 12, 2023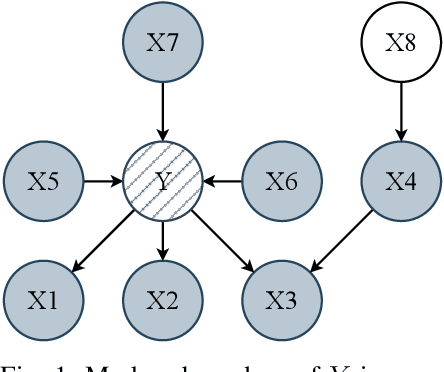


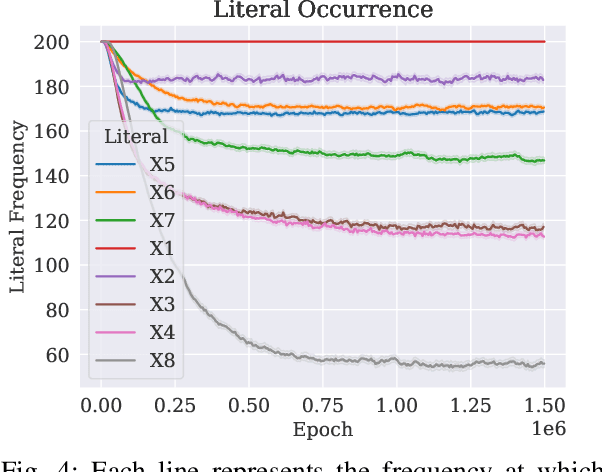
A set of variables is the Markov blanket of a random variable if it contains all the information needed for predicting the variable. If the blanket cannot be reduced without losing useful information, it is called a Markov boundary. Identifying the Markov boundary of a random variable is advantageous because all variables outside the boundary are superfluous. Hence, the Markov boundary provides an optimal feature set. However, learning the Markov boundary from data is challenging for two reasons. If one or more variables are removed from the Markov boundary, variables outside the boundary may start providing information. Conversely, variables within the boundary may stop providing information. The true role of each candidate variable is only manifesting when the Markov boundary has been identified. In this paper, we propose a new Tsetlin Machine (TM) feedback scheme that supplements Type I and Type II feedback. The scheme introduces a novel Finite State Automaton - a Context-Specific Independence Automaton. The automaton learns which features are outside the Markov boundary of the target, allowing them to be pruned from the TM during learning. We investigate the new scheme empirically, showing how it is capable of exploiting context-specific independence to find Markov boundaries. Further, we provide a theoretical analysis of convergence. Our approach thus connects the field of Bayesian networks (BN) with TMs, potentially opening up for synergies when it comes to inference and learning, including TM-produced Bayesian knowledge bases and TM-based Bayesian inference.
DeNISE: Deep Networks for Improved Segmentation Edges
Sep 05, 2023This paper presents Deep Networks for Improved Segmentation Edges (DeNISE), a novel data enhancement technique using edge detection and segmentation models to improve the boundary quality of segmentation masks. DeNISE utilizes the inherent differences in two sequential deep neural architectures to improve the accuracy of the predicted segmentation edge. DeNISE applies to all types of neural networks and is not trained end-to-end, allowing rapid experiments to discover which models complement each other. We test and apply DeNISE for building segmentation in aerial images. Aerial images are known for difficult conditions as they have a low resolution with optical noise, such as reflections, shadows, and visual obstructions. Overall the paper demonstrates the potential for DeNISE. Using the technique, we improve the baseline results with a building IoU of 78.9%.
Loss and Reward Weighing for increased learning in Distributed Reinforcement Learning
Apr 25, 2023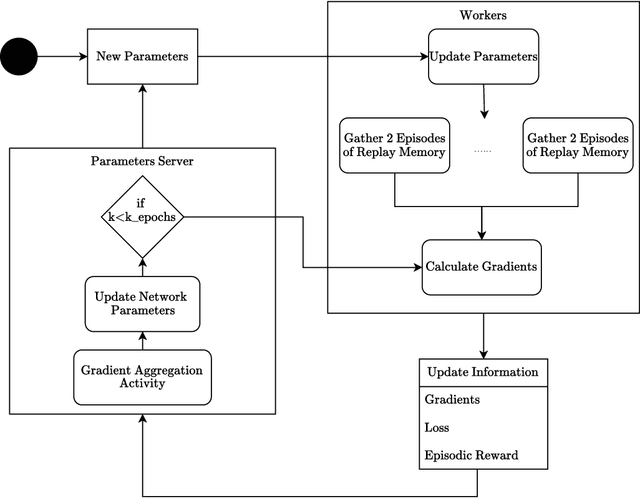



This paper introduces two learning schemes for distributed agents in Reinforcement Learning (RL) environments, namely Reward-Weighted (R-Weighted) and Loss-Weighted (L-Weighted) gradient merger. The R/L weighted methods replace standard practices for training multiple agents, such as summing or averaging the gradients. The core of our methods is to scale the gradient of each actor based on how high the reward (for R-Weighted) or the loss (for L-Weighted) is compared to the other actors. During training, each agent operates in differently initialized versions of the same environment, which gives different gradients from different actors. In essence, the R-Weights and L-Weights of each agent inform the other agents of its potential, which again reports which environment should be prioritized for learning. This approach of distributed learning is possible because environments that yield higher rewards, or low losses, have more critical information than environments that yield lower rewards or higher losses. We empirically demonstrate that the R-Weighted methods work superior to the state-of-the-art in multiple RL environments.