 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSuperF: Neural Implicit Fields for Multi-Image Super-Resolution
Dec 09, 2025High-resolution imagery is often hindered by limitations in sensor technology, atmospheric conditions, and costs. Such challenges occur in satellite remote sensing, but also with handheld cameras, such as our smartphones. Hence, super-resolution aims to enhance the image resolution algorithmically. Since single-image super-resolution requires solving an inverse problem, such methods must exploit strong priors, e.g. learned from high-resolution training data, or be constrained by auxiliary data, e.g. by a high-resolution guide from another modality. While qualitatively pleasing, such approaches often lead to "hallucinated" structures that do not match reality. In contrast, multi-image super-resolution (MISR) aims to improve the (optical) resolution by constraining the super-resolution process with multiple views taken with sub-pixel shifts. Here, we propose SuperF, a test-time optimization approach for MISR that leverages coordinate-based neural networks, also called neural fields. Their ability to represent continuous signals with an implicit neural representation (INR) makes them an ideal fit for the MISR task. The key characteristic of our approach is to share an INR for multiple shifted low-resolution frames and to jointly optimize the frame alignment with the INR. Our approach advances related INR baselines, adopted from burst fusion for layer separation, by directly parameterizing the sub-pixel alignment as optimizable affine transformation parameters and by optimizing via a super-sampled coordinate grid that corresponds to the output resolution. Our experiments yield compelling results on simulated bursts of satellite imagery and ground-level images from handheld cameras, with upsampling factors of up to 8. A key advantage of SuperF is that this approach does not rely on any high-resolution training data.
Knowledge-Informed Automatic Feature Extraction via Collaborative Large Language Model Agents
Nov 19, 2025The performance of machine learning models on tabular data is critically dependent on high-quality feature engineering. While Large Language Models (LLMs) have shown promise in automating feature extraction (AutoFE), existing methods are often limited by monolithic LLM architectures, simplistic quantitative feedback, and a failure to systematically integrate external domain knowledge. This paper introduces Rogue One, a novel, LLM-based multi-agent framework for knowledge-informed automatic feature extraction. Rogue One operationalizes a decentralized system of three specialized agents-Scientist, Extractor, and Tester-that collaborate iteratively to discover, generate, and validate predictive features. Crucially, the framework moves beyond primitive accuracy scores by introducing a rich, qualitative feedback mechanism and a "flooding-pruning" strategy, allowing it to dynamically balance feature exploration and exploitation. By actively incorporating external knowledge via an integrated retrieval-augmented (RAG) system, Rogue One generates features that are not only statistically powerful but also semantically meaningful and interpretable. We demonstrate that Rogue One significantly outperforms state-of-the-art methods on a comprehensive suite of 19 classification and 9 regression datasets. Furthermore, we show qualitatively that the system surfaces novel, testable hypotheses, such as identifying a new potential biomarker in the myocardial dataset, underscoring its utility as a tool for scientific discovery.
A New HOPE: Domain-agnostic Automatic Evaluation of Text Chunking
May 04, 2025Document chunking fundamentally impacts Retrieval-Augmented Generation (RAG) by determining how source materials are segmented before indexing. Despite evidence that Large Language Models (LLMs) are sensitive to the layout and structure of retrieved data, there is currently no framework to analyze the impact of different chunking methods. In this paper, we introduce a novel methodology that defines essential characteristics of the chunking process at three levels: intrinsic passage properties, extrinsic passage properties, and passages-document coherence. We propose HOPE (Holistic Passage Evaluation), a domain-agnostic, automatic evaluation metric that quantifies and aggregates these characteristics. Our empirical evaluations across seven domains demonstrate that the HOPE metric correlates significantly (p > 0.13) with various RAG performance indicators, revealing contrasts between the importance of extrinsic and intrinsic properties of passages. Semantic independence between passages proves essential for system performance with a performance gain of up to 56.2% in factual correctness and 21.1% in answer correctness. On the contrary, traditional assumptions about maintaining concept unity within passages show minimal impact. These findings provide actionable insights for optimizing chunking strategies, thus improving RAG system design to produce more factually correct responses.
Maximum Manifold Capacity Representations in State Representation Learning
May 22, 2024

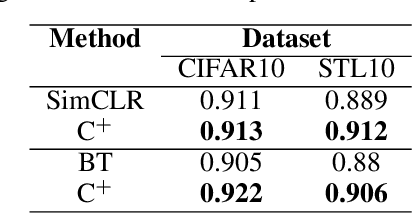
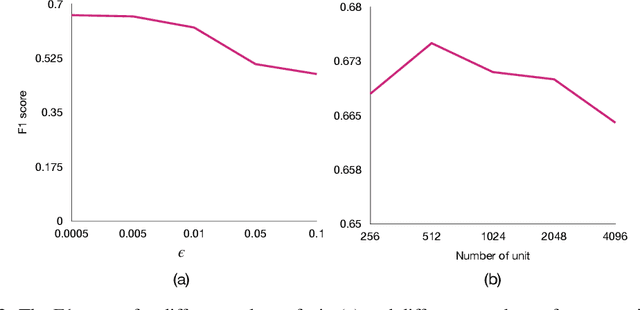
The expanding research on manifold-based self-supervised learning (SSL) builds on the manifold hypothesis, which suggests that the inherent complexity of high-dimensional data can be unraveled through lower-dimensional manifold embeddings. Capitalizing on this, DeepInfomax with an unbalanced atlas (DIM-UA) has emerged as a powerful tool and yielded impressive results for state representations in reinforcement learning. Meanwhile, Maximum Manifold Capacity Representation (MMCR) presents a new frontier for SSL by optimizing class separability via manifold compression. However, MMCR demands extensive input views, resulting in significant computational costs and protracted pre-training durations. Bridging this gap, we present an innovative integration of MMCR into existing SSL methods, incorporating a discerning regularization strategy that enhances the lower bound of mutual information. We also propose a novel state representation learning method extending DIM-UA, embedding a nuclear norm loss to enforce manifold consistency robustly. On experimentation with the Atari Annotated RAM Interface, our method improves DIM-UA significantly with the same number of target encoding dimensions. The mean F1 score averaged over categories is 78% compared to 75% of DIM-UA. There are also compelling gains when implementing SimCLR and Barlow Twins. This supports our SSL innovation as a paradigm shift, enabling more nuanced high-dimensional data representations.
A Manifold Representation of the Key in Vision Transformers
Feb 01, 2024Vision Transformers implement multi-head self-attention (MSA) via stacking multiple attention blocks. The query, key, and value are often intertwined and generated within those blocks via a single, shared linear transformation. This paper explores the concept of disentangling the key from the query and value, and adopting a manifold representation for the key. Our experiments reveal that decoupling and endowing the key with a manifold structure can enhance the model performance. Specifically, ViT-B exhibits a 0.87% increase in top-1 accuracy, while Swin-T sees a boost of 0.52% in top-1 accuracy on the ImageNet-1K dataset, with eight charts in the manifold key. Our approach also yields positive results in object detection and instance segmentation tasks on the COCO dataset. Through detailed ablation studies, we establish that these performance gains are not merely due to the simplicity of adding more parameters and computations. Future research may investigate strategies for cutting the budget of such representations and aim for further performance improvements based on our findings.
MapAI: Precision in Building Segmentation
Jan 09, 2024MapAI: Precision in Building Segmentation is a competition arranged with the Norwegian Artificial Intelligence Research Consortium (NORA) in collaboration with Centre for Artificial Intelligence Research at the University of Agder (CAIR), the Norwegian Mapping Authority, AI:Hub, Norkart, and the Danish Agency for Data Supply and Infrastructure. The competition will be held in the fall of 2022. It will be concluded at the Northern Lights Deep Learning conference focusing on the segmentation of buildings using aerial images and laser data. We propose two different tasks to segment buildings, where the first task can only utilize aerial images, while the second must use laser data (LiDAR) with or without aerial images. Furthermore, we use IoU and Boundary IoU to properly evaluate the precision of the models, with the latter being an IoU measure that evaluates the results' boundaries. We provide the participants with a training dataset and keep a test dataset for evaluation.
Harnessing Attention Mechanisms: Efficient Sequence Reduction using Attention-based Autoencoders
Oct 23, 2023

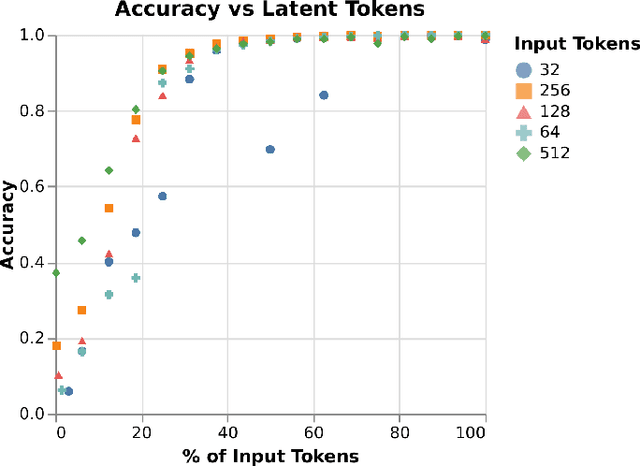
Many machine learning models use the manipulation of dimensions as a driving force to enable models to identify and learn important features in data. In the case of sequential data this manipulation usually happens on the token dimension level. Despite the fact that many tasks require a change in sequence length itself, the step of sequence length reduction usually happens out of necessity and in a single step. As far as we are aware, no model uses the sequence length reduction step as an additional opportunity to tune the models performance. In fact, sequence length manipulation as a whole seems to be an overlooked direction. In this study we introduce a novel attention-based method that allows for the direct manipulation of sequence lengths. To explore the method's capabilities, we employ it in an autoencoder model. The autoencoder reduces the input sequence to a smaller sequence in latent space. It then aims to reproduce the original sequence from this reduced form. In this setting, we explore the methods reduction performance for different input and latent sequence lengths. We are able to show that the autoencoder retains all the significant information when reducing the original sequence to half its original size. When reducing down to as low as a quarter of its original size, the autoencoder is still able to reproduce the original sequence with an accuracy of around 90%.
DeNISE: Deep Networks for Improved Segmentation Edges
Sep 05, 2023This paper presents Deep Networks for Improved Segmentation Edges (DeNISE), a novel data enhancement technique using edge detection and segmentation models to improve the boundary quality of segmentation masks. DeNISE utilizes the inherent differences in two sequential deep neural architectures to improve the accuracy of the predicted segmentation edge. DeNISE applies to all types of neural networks and is not trained end-to-end, allowing rapid experiments to discover which models complement each other. We test and apply DeNISE for building segmentation in aerial images. Aerial images are known for difficult conditions as they have a low resolution with optical noise, such as reflections, shadows, and visual obstructions. Overall the paper demonstrates the potential for DeNISE. Using the technique, we improve the baseline results with a building IoU of 78.9%.
CorrEmbed: Evaluating Pre-trained Model Image Similarity Efficacy with a Novel Metric
Aug 30, 2023Detecting visually similar images is a particularly useful attribute to look to when calculating product recommendations. Embedding similarity, which utilizes pre-trained computer vision models to extract high-level image features, has demonstrated remarkable efficacy in identifying images with similar compositions. However, there is a lack of methods for evaluating the embeddings generated by these models, as conventional loss and performance metrics do not adequately capture their performance in image similarity search tasks. In this paper, we evaluate the viability of the image embeddings from numerous pre-trained computer vision models using a novel approach named CorrEmbed. Our approach computes the correlation between distances in image embeddings and distances in human-generated tag vectors. We extensively evaluate numerous pre-trained Torchvision models using this metric, revealing an intuitive relationship of linear scaling between ImageNet1k accuracy scores and tag-correlation scores. Importantly, our method also identifies deviations from this pattern, providing insights into how different models capture high-level image features. By offering a robust performance evaluation of these pre-trained models, CorrEmbed serves as a valuable tool for researchers and practitioners seeking to develop effective, data-driven approaches to similar item recommendations in fashion retail.
State Representation Learning Using an Unbalanced Atlas
May 17, 2023The manifold hypothesis posits that high-dimensional data often lies on a lower-dimensional manifold and that utilizing this manifold as the target space yields more efficient representations. While numerous traditional manifold-based techniques exist for dimensionality reduction, their application in self-supervised learning has witnessed slow progress. The recent MSIMCLR method combines manifold encoding with SimCLR but requires extremely low target encoding dimensions to outperform SimCLR, limiting its applicability. This paper introduces a novel learning paradigm using an unbalanced atlas (UA), capable of surpassing state-of-the-art self-supervised learning approaches. We meticulously investigated and engineered the DeepInfomax with an unbalanced atlas (DIM-UA) method by systematically adapting the Spatiotemporal DeepInfomax (ST-DIM) framework to align with our proposed UA paradigm, employing rigorous scientific methodologies throughout the process. The efficacy of DIM-UA is demonstrated through training and evaluation on the Atari Annotated RAM Interface (AtariARI) benchmark, a modified version of the Atari 2600 framework that produces annotated image samples for representation learning. The UA paradigm improves the existing algorithm significantly when the number of target encoding dimensions grows. For instance, the mean F1 score averaged over categories of DIM-UA is ~75% compared to ~70% of ST-DIM when using 16384 hidden units.