 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep and Probabilistic Solar Irradiance Forecast at the Arctic Circle
Oct 10, 2024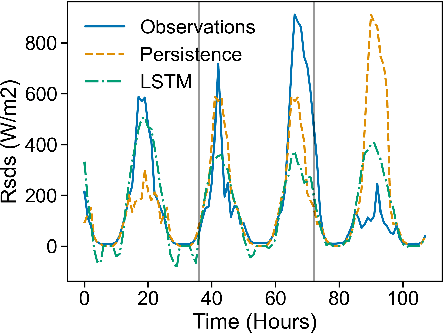
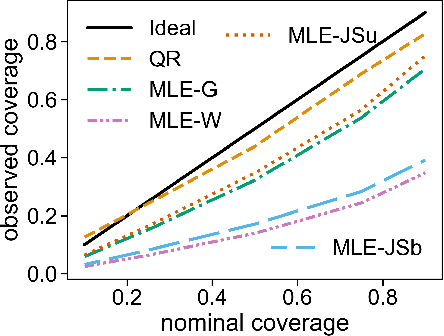

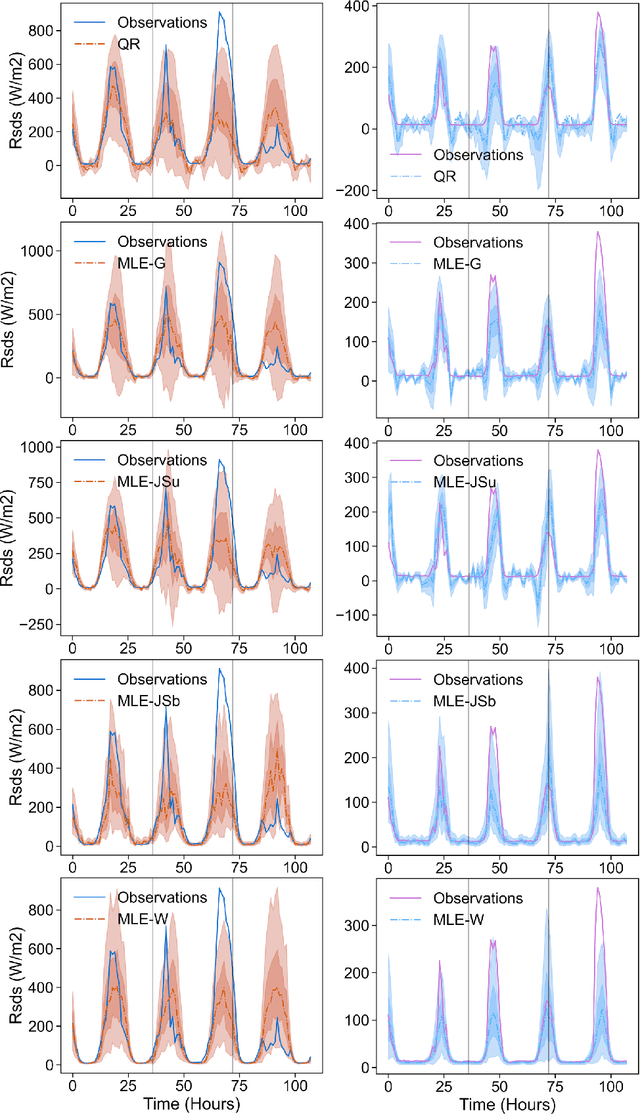
Solar irradiance forecasts can be dynamic and unreliable due to changing weather conditions. Near the Arctic circle, this also translates into a distinct set of further challenges. This work is forecasting solar irradiance with Norwegian data using variations of Long-Short-Term Memory units (LSTMs). In order to gain more trustworthiness of results, the probabilistic approaches Quantile Regression (QR) and Maximum Likelihood (MLE) are optimized on top of the LSTMs, providing measures of uncertainty for the results. MLE is further extended by using a Johnson's SU distribution, a Johnson's SB distribution, and a Weibull distribution in addition to a normal Gaussian to model parameters. Contrary to a Gaussian, Weibull, Johnson's SU and Johnson's SB can return skewed distributions, enabling it to fit the non-normal solar irradiance distribution more optimally. The LSTMs are compared against each other, a simple Multi-layer Perceptron (MLP), and a smart-persistence estimator. The proposed LSTMs are found to be more accurate than smart persistence and the MLP for a multi-horizon, day-ahead (36 hours) forecast. The deterministic LSTM showed better root mean squared error (RMSE), but worse mean absolute error (MAE) than a MLE with Johnson's SB distribution. Probabilistic uncertainty estimation is shown to fit relatively well across the distribution of observed irradiance. While QR shows better uncertainty estimation calibration, MLE with Johnson's SB, Johnson's SU, or Gaussian show better performance in the other metrics employed. Optimizing and comparing the models against each other reveals a seemingly inherent trade-off between point-prediction and uncertainty estimation calibration.
Maximum Manifold Capacity Representations in State Representation Learning
May 22, 2024

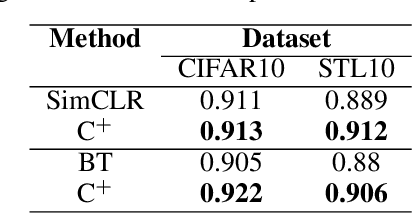
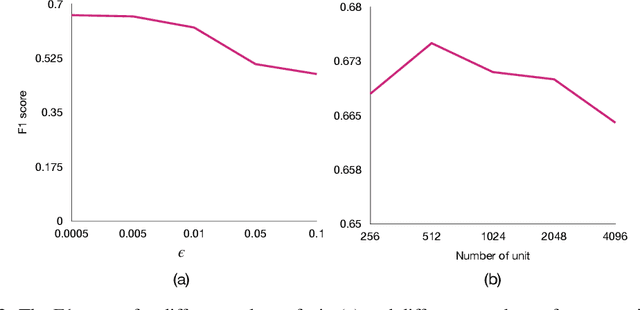
The expanding research on manifold-based self-supervised learning (SSL) builds on the manifold hypothesis, which suggests that the inherent complexity of high-dimensional data can be unraveled through lower-dimensional manifold embeddings. Capitalizing on this, DeepInfomax with an unbalanced atlas (DIM-UA) has emerged as a powerful tool and yielded impressive results for state representations in reinforcement learning. Meanwhile, Maximum Manifold Capacity Representation (MMCR) presents a new frontier for SSL by optimizing class separability via manifold compression. However, MMCR demands extensive input views, resulting in significant computational costs and protracted pre-training durations. Bridging this gap, we present an innovative integration of MMCR into existing SSL methods, incorporating a discerning regularization strategy that enhances the lower bound of mutual information. We also propose a novel state representation learning method extending DIM-UA, embedding a nuclear norm loss to enforce manifold consistency robustly. On experimentation with the Atari Annotated RAM Interface, our method improves DIM-UA significantly with the same number of target encoding dimensions. The mean F1 score averaged over categories is 78% compared to 75% of DIM-UA. There are also compelling gains when implementing SimCLR and Barlow Twins. This supports our SSL innovation as a paradigm shift, enabling more nuanced high-dimensional data representations.
A Manifold Representation of the Key in Vision Transformers
Feb 01, 2024Vision Transformers implement multi-head self-attention (MSA) via stacking multiple attention blocks. The query, key, and value are often intertwined and generated within those blocks via a single, shared linear transformation. This paper explores the concept of disentangling the key from the query and value, and adopting a manifold representation for the key. Our experiments reveal that decoupling and endowing the key with a manifold structure can enhance the model performance. Specifically, ViT-B exhibits a 0.87% increase in top-1 accuracy, while Swin-T sees a boost of 0.52% in top-1 accuracy on the ImageNet-1K dataset, with eight charts in the manifold key. Our approach also yields positive results in object detection and instance segmentation tasks on the COCO dataset. Through detailed ablation studies, we establish that these performance gains are not merely due to the simplicity of adding more parameters and computations. Future research may investigate strategies for cutting the budget of such representations and aim for further performance improvements based on our findings.
State Representation Learning Using an Unbalanced Atlas
May 17, 2023The manifold hypothesis posits that high-dimensional data often lies on a lower-dimensional manifold and that utilizing this manifold as the target space yields more efficient representations. While numerous traditional manifold-based techniques exist for dimensionality reduction, their application in self-supervised learning has witnessed slow progress. The recent MSIMCLR method combines manifold encoding with SimCLR but requires extremely low target encoding dimensions to outperform SimCLR, limiting its applicability. This paper introduces a novel learning paradigm using an unbalanced atlas (UA), capable of surpassing state-of-the-art self-supervised learning approaches. We meticulously investigated and engineered the DeepInfomax with an unbalanced atlas (DIM-UA) method by systematically adapting the Spatiotemporal DeepInfomax (ST-DIM) framework to align with our proposed UA paradigm, employing rigorous scientific methodologies throughout the process. The efficacy of DIM-UA is demonstrated through training and evaluation on the Atari Annotated RAM Interface (AtariARI) benchmark, a modified version of the Atari 2600 framework that produces annotated image samples for representation learning. The UA paradigm improves the existing algorithm significantly when the number of target encoding dimensions grows. For instance, the mean F1 score averaged over categories of DIM-UA is ~75% compared to ~70% of ST-DIM when using 16384 hidden units.
It is all Connected: A New Graph Formulation for Spatio-Temporal Forecasting
Mar 23, 2023With an ever-increasing number of sensors in modern society, spatio-temporal time series forecasting has become a de facto tool to make informed decisions about the future. Most spatio-temporal forecasting models typically comprise distinct components that learn spatial and temporal dependencies. A common methodology employs some Graph Neural Network (GNN) to capture relations between spatial locations, while another network, such as a recurrent neural network (RNN), learns temporal correlations. By representing every recorded sample as its own node in a graph, rather than all measurements for a particular location as a single node, temporal and spatial information is encoded in a similar manner. In this setting, GNNs can now directly learn both temporal and spatial dependencies, jointly, while also alleviating the need for additional temporal networks. Furthermore, the framework does not require aligned measurements along the temporal dimension, meaning that it also naturally facilitates irregular time series, different sampling frequencies or missing data, without the need for data imputation. To evaluate the proposed methodology, we consider wind speed forecasting as a case study, where our proposed framework outperformed other spatio-temporal models using GNNs with either Transformer or LSTM networks as temporal update functions.
Unsupervised Representation Learning in Partially Observable Atari Games
Mar 13, 2023State representation learning aims to capture latent factors of an environment. Contrastive methods have performed better than generative models in previous state representation learning research. Although some researchers realize the connections between masked image modeling and contrastive representation learning, the effort is focused on using masks as an augmentation technique to represent the latent generative factors better. Partially observable environments in reinforcement learning have not yet been carefully studied using unsupervised state representation learning methods. In this article, we create an unsupervised state representation learning scheme for partially observable states. We conducted our experiment on a previous Atari 2600 framework designed to evaluate representation learning models. A contrastive method called Spatiotemporal DeepInfomax (ST-DIM) has shown state-of-the-art performance on this benchmark but remains inferior to its supervised counterpart. Our approach improves ST-DIM when the environment is not fully observable and achieves higher F1 scores and accuracy scores than the supervised learning counterpart. The mean accuracy score averaged over categories of our approach is ~66%, compared to ~38% of supervised learning. The mean F1 score is ~64% to ~33%.
Spatio-Temporal Wind Speed Forecasting using Graph Networks and Novel Transformer Architectures
Aug 29, 2022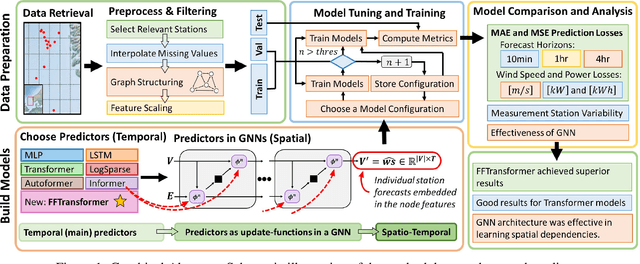
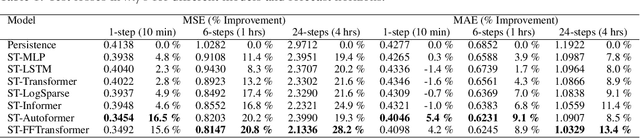
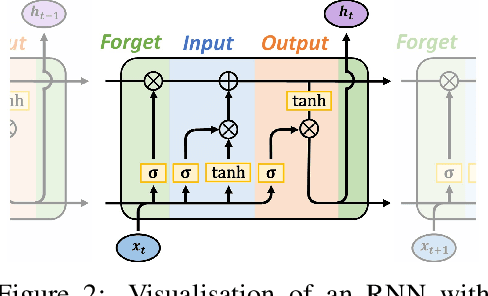
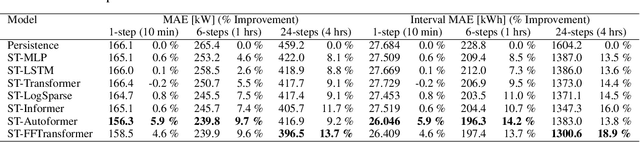
To improve the security and reliability of wind energy production, short-term forecasting has become of utmost importance. This study focuses on multi-step spatio-temporal wind speed forecasting for the Norwegian continental shelf. A graph neural network (GNN) architecture was used to extract spatial dependencies, with different update functions to learn temporal correlations. These update functions were implemented using different neural network architectures. One such architecture, the Transformer, has become increasingly popular for sequence modelling in recent years. Various alterations of the original architecture have been proposed to better facilitate time-series forecasting, of which this study focused on the Informer, LogSparse Transformer and Autoformer. This is the first time the LogSparse Transformer and Autoformer have been applied to wind forecasting and the first time any of these or the Informer have been formulated in a spatio-temporal setting for wind forecasting. By comparing against spatio-temporal Long Short-Term Memory (LSTM) and Multi-Layer Perceptron (MLP) models, the study showed that the models using the altered Transformer architectures as update functions in GNNs were able to outperform these. Furthermore, we propose the Fast Fourier Transformer (FFTransformer), which is a novel Transformer architecture based on signal decomposition and consists of two separate streams that analyse trend and periodic components separately. The FFTransformer and Autoformer were found to achieve superior results for the 10-minute and 1-hour ahead forecasts, with the FFTransformer significantly outperforming all other models for the 4-hour ahead forecasts. Finally, by varying the degree of connectivity for the graph representations, the study explicitly demonstrates how all models were able to leverage spatial dependencies to improve local short-term wind speed forecasting.
Deep Reinforcement Learning with Swin Transformer
Jun 30, 2022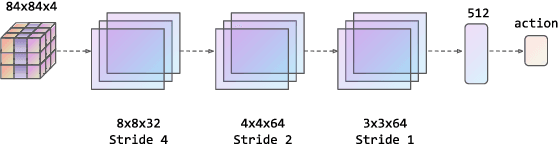
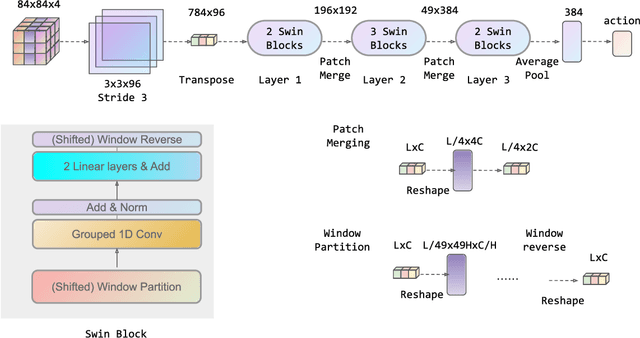
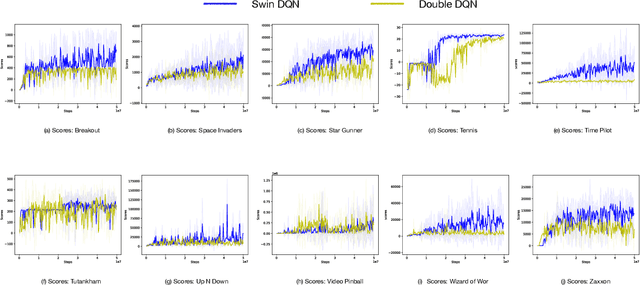
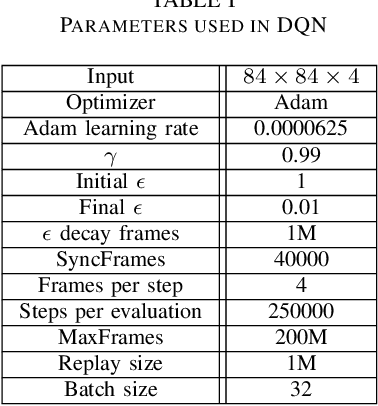
Transformers are neural network models that utilize multiple layers of self-attention heads. Attention is implemented in transformers as the contextual embeddings of the 'key' and 'query'. Transformers allow the re-combination of attention information from different layers and the processing of all inputs at once, which are more convenient than recurrent neural networks when dealt with a large number of data. Transformers have exhibited great performances on natural language processing tasks in recent years. Meanwhile, there have been tremendous efforts to adapt transformers into other fields of machine learning, such as Swin Transformer and Decision Transformer. Swin Transformer is a promising neural network architecture that splits image pixels into small patches and applies local self-attention operations inside the (shifted) windows of fixed sizes. Decision Transformer has successfully applied transformers to off-line reinforcement learning and showed that random-walk samples from Atari games are sufficient to let an agent learn optimized behaviors. However, it is considerably more challenging to combine online reinforcement learning with transformers. In this article, we further explore the possibility of not modifying the reinforcement learning policy, but only replacing the convolutional neural network architecture with the self-attention architecture from Swin Transformer. Namely, we target at changing how an agent views the world, but not how an agent plans about the world. We conduct our experiment on 49 games in Arcade Learning Environment. The results show that using Swin Transformer in reinforcement learning achieves significantly higher evaluation scores across the majority of games in Arcade Learning Environment. Thus, we conclude that online reinforcement learning can benefit from exploiting self-attentions with spatial token embeddings.
Improving the Diversity of Bootstrapped DQN via Noisy Priors
Mar 02, 2022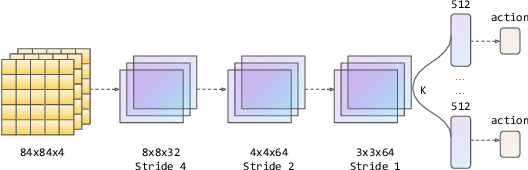
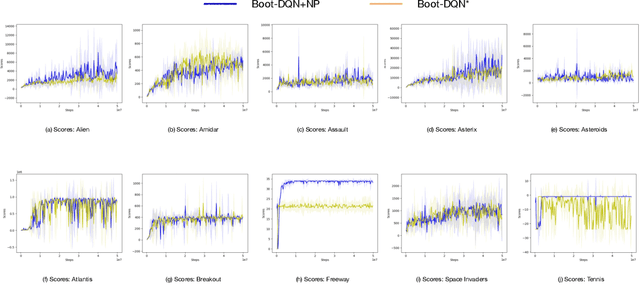
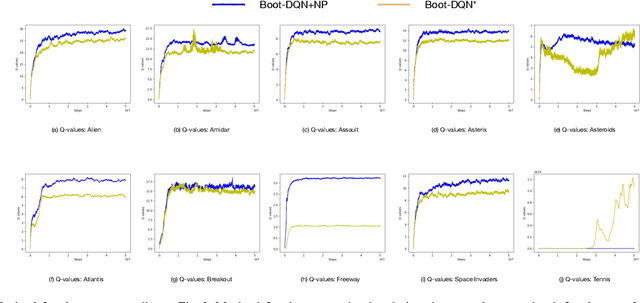

Q-learning is one of the most well-known Reinforcement Learning algorithms. There have been tremendous efforts to develop this algorithm using neural networks. Bootstrapped Deep Q-Learning Network is amongst one of them. It utilizes multiple neural network heads to introduce diversity into Q-learning. Diversity can sometimes be viewed as the amount of reasonable moves an agent can take at a given state, analogous to the definition of the exploration ratio in RL. Thus, the performance of Bootstrapped Deep Q-Learning Network is deeply connected with the level of diversity within the algorithm. In the original research, it was pointed out that a random prior could improve the performance of the model. In this article, we further explore the possibility of treating priors as a special type of noise and sample priors from a Gaussian distribution to introduce more diversity into this algorithm. We conduct our experiment on the Atari benchmark and compare our algorithm to both the original and other related algorithms. The results show that our modification of the Bootstrapped Deep Q-Learning algorithm achieves significantly higher evaluation scores across different types of Atari games. Thus, we conclude that noisy priors can improve Bootstrapped Deep Q-Learning's performance by ensuring the integrity of diversities.
Wind Park Power Prediction: Attention-Based Graph Networks and Deep Learning to Capture Wake Losses
Jan 10, 2022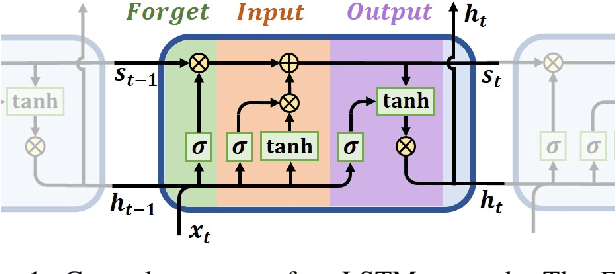
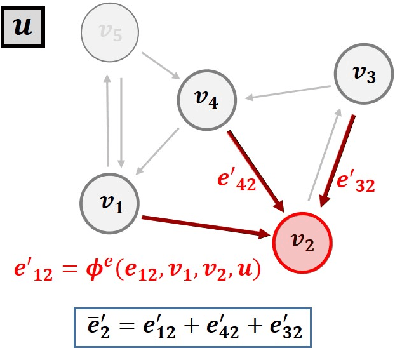
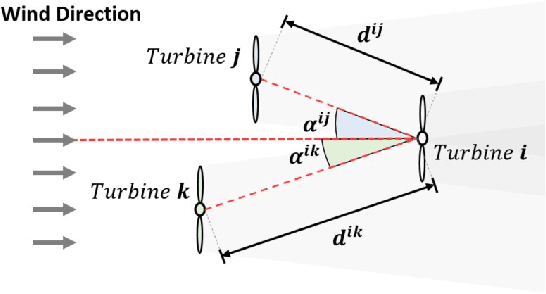
With the increased penetration of wind energy into the power grid, it has become increasingly important to be able to predict the expected power production for larger wind farms. Deep learning (DL) models can learn complex patterns in the data and have found wide success in predicting wake losses and expected power production. This paper proposes a modular framework for attention-based graph neural networks (GNN), where attention can be applied to any desired component of a graph block. The results show that the model significantly outperforms a multilayer perceptron (MLP) and a bidirectional LSTM (BLSTM) model, while delivering performance on-par with a vanilla GNN model. Moreover, we argue that the proposed graph attention architecture can easily adapt to different applications by offering flexibility into the desired attention operations to be used, which might depend on the specific application. Through analysis of the attention weights, it was showed that employing attention-based GNNs can provide insights into what the models learn. In particular, the attention networks seemed to realise turbine dependencies that aligned with some physical intuition about wake losses.