 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving the Diversity of Bootstrapped DQN via Noisy Priors
Paper and Code
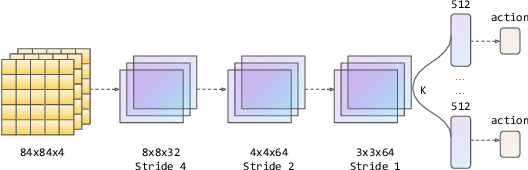
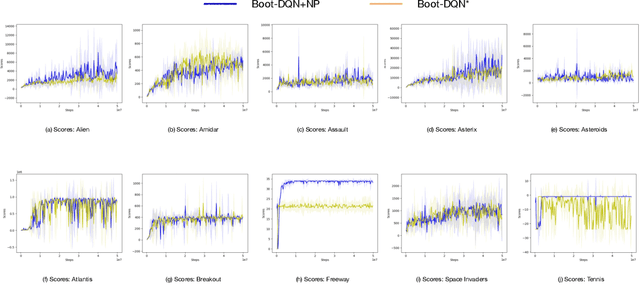
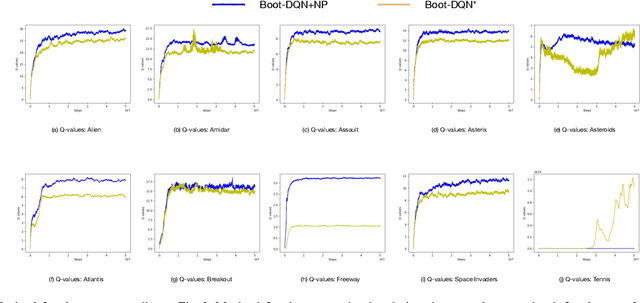

Q-learning is one of the most well-known Reinforcement Learning algorithms. There have been tremendous efforts to develop this algorithm using neural networks. Bootstrapped Deep Q-Learning Network is amongst one of them. It utilizes multiple neural network heads to introduce diversity into Q-learning. Diversity can sometimes be viewed as the amount of reasonable moves an agent can take at a given state, analogous to the definition of the exploration ratio in RL. Thus, the performance of Bootstrapped Deep Q-Learning Network is deeply connected with the level of diversity within the algorithm. In the original research, it was pointed out that a random prior could improve the performance of the model. In this article, we further explore the possibility of treating priors as a special type of noise and sample priors from a Gaussian distribution to introduce more diversity into this algorithm. We conduct our experiment on the Atari benchmark and compare our algorithm to both the original and other related algorithms. The results show that our modification of the Bootstrapped Deep Q-Learning algorithm achieves significantly higher evaluation scores across different types of Atari games. Thus, we conclude that noisy priors can improve Bootstrapped Deep Q-Learning's performance by ensuring the integrity of diversities.