 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplainability of Complex AI Models with Correlation Impact Ratio
Jan 10, 2026Complex AI systems make better predictions but often lack transparency, limiting trustworthiness, interpretability, and safe deployment. Common post hoc AI explainers, such as LIME, SHAP, HSIC, and SAGE, are model agnostic but are too restricted in one significant regard: they tend to misrank correlated features and require costly perturbations, which do not scale to high dimensional data. We introduce ExCIR (Explainability through Correlation Impact Ratio), a theoretically grounded, simple, and reliable metric for explaining the contribution of input features to model outputs, which remains stable and consistent under noise and sampling variations. We demonstrate that ExCIR captures dependencies arising from correlated features through a lightweight single pass formulation. Experimental evaluations on diverse datasets, including EEG, synthetic vehicular data, Digits, and Cats-Dogs, validate the effectiveness and stability of ExCIR across domains, achieving more interpretable feature explanations than existing methods while remaining computationally efficient. To this end, we further extend ExCIR with an information theoretic foundation that unifies the correlation ratio with Canonical Correlation Analysis under mutual information bounds, enabling multi output and class conditioned explainability at scale.
BiSparse-AAS: Bilinear Sparse Attention and Adaptive Spans Framework for Scalable and Efficient Text Summarization
Oct 31, 2025Transformer-based architectures have advanced text summarization, yet their quadratic complexity limits scalability on long documents. This paper introduces BiSparse-AAS (Bilinear Sparse Attention with Adaptive Spans), a novel framework that combines sparse attention, adaptive spans, and bilinear attention to address these limitations. Sparse attention reduces computational costs by focusing on the most relevant parts of the input, while adaptive spans dynamically adjust the attention ranges. Bilinear attention complements both by modeling complex token interactions within this refined context. BiSparse-AAS consistently outperforms state-of-the-art baselines in both extractive and abstractive summarization tasks, achieving average ROUGE improvements of about 68.1% on CNN/DailyMail and 52.6% on XSum, while maintaining strong performance on OpenWebText and Gigaword datasets. By addressing efficiency, scalability, and long-sequence modeling, BiSparse-AAS provides a unified, practical solution for real-world text summarization applications.
Learning Graph Representation of Agent Diffusers
May 15, 2025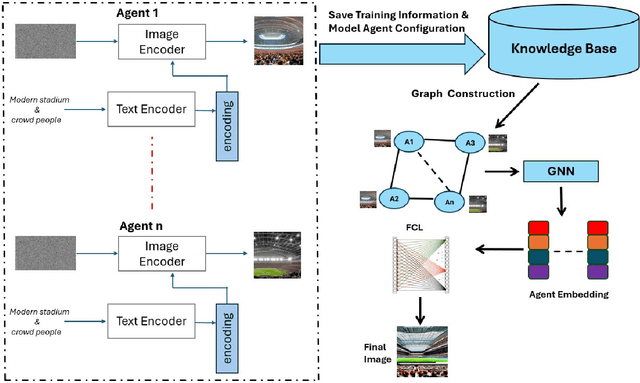

Diffusion-based generative models have significantly advanced text-to-image synthesis, demonstrating impressive text comprehension and zero-shot generalization. These models refine images from random noise based on textual prompts, with initial reliance on text input shifting towards enhanced visual fidelity over time. This transition suggests that static model parameters might not optimally address the distinct phases of generation. We introduce LGR-AD (Learning Graph Representation of Agent Diffusers), a novel multi-agent system designed to improve adaptability in dynamic computer vision tasks. LGR-AD models the generation process as a distributed system of interacting agents, each representing an expert sub-model. These agents dynamically adapt to varying conditions and collaborate through a graph neural network that encodes their relationships and performance metrics. Our approach employs a coordination mechanism based on top-$k$ maximum spanning trees, optimizing the generation process. Each agent's decision-making is guided by a meta-model that minimizes a novel loss function, balancing accuracy and diversity. Theoretical analysis and extensive empirical evaluations show that LGR-AD outperforms traditional diffusion models across various benchmarks, highlighting its potential for scalable and flexible solutions in complex image generation tasks. Code is available at: https://github.com/YousIA/LGR_AD
Modeling Eye Gaze Velocity Trajectories using GANs with Spectral Loss for Enhanced Fidelity
Dec 05, 2024Accurate modeling of eye gaze dynamics is essential for advancement in human-computer interaction, neurological diagnostics, and cognitive research. Traditional generative models like Markov models often fail to capture the complex temporal dependencies and distributional nuance inherent in eye gaze trajectories data. This study introduces a GAN framework employing LSTM and CNN generators and discriminators to generate high-fidelity synthetic eye gaze velocity trajectories. We conducted a comprehensive evaluation of four GAN architectures: CNN-CNN, LSTM-CNN, CNN-LSTM, and LSTM-LSTM trained under two conditions: using only adversarial loss and using a weighted combination of adversarial and spectral losses. Our findings reveal that the LSTM-CNN architecture trained with this new loss function exhibits the closest alignment to the real data distribution, effectively capturing both the distribution tails and the intricate temporal dependencies. The inclusion of spectral regularization significantly enhances the GANs ability to replicate the spectral characteristics of eye gaze movements, leading to a more stable learning process and improved data fidelity. Comparative analysis with an HMM optimized to four hidden states further highlights the advantages of the LSTM-CNN GAN. Statistical metrics show that the HMM-generated data significantly diverges from the real data in terms of mean, standard deviation, skewness, and kurtosis. In contrast, the LSTM-CNN model closely matches the real data across these statistics, affirming its capacity to model the complexity of eye gaze dynamics effectively. These results position the spectrally regularized LSTM-CNN GAN as a robust tool for generating synthetic eye gaze velocity data with high fidelity.
DREAMS: A python framework to train deep learning models with model card reporting for medical and health applications
Sep 26, 2024



Electroencephalography (EEG) data provides a non-invasive method for researchers and clinicians to observe brain activity in real time. The integration of deep learning techniques with EEG data has significantly improved the ability to identify meaningful patterns, leading to valuable insights for both clinical and research purposes. However, most of the frameworks so far, designed for EEG data analysis, are either too focused on pre-processing or in deep learning methods per, making their use for both clinician and developer communities problematic. Moreover, critical issues such as ethical considerations, biases, uncertainties, and the limitations inherent in AI models for EEG data analysis are frequently overlooked, posing challenges to the responsible implementation of these technologies. In this paper, we introduce a comprehensive deep learning framework tailored for EEG data processing, model training and report generation. While constructed in way to be adapted and developed further by AI developers, it enables to report, through model cards, the outcome and specific information of use for both developers and clinicians. In this way, we discuss how this framework can, in the future, provide clinical researchers and developers with the tools needed to create transparent and accountable AI models for EEG data analysis and diagnosis.
Maximum Manifold Capacity Representations in State Representation Learning
May 22, 2024

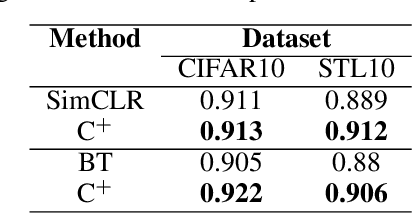
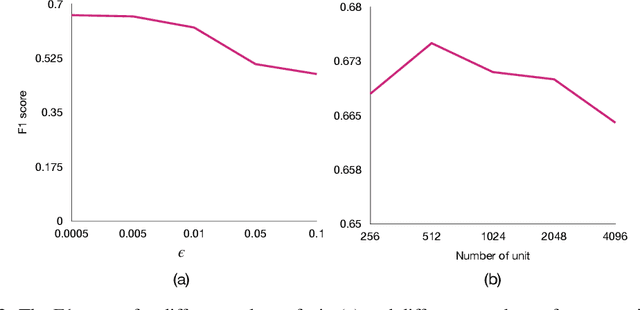
The expanding research on manifold-based self-supervised learning (SSL) builds on the manifold hypothesis, which suggests that the inherent complexity of high-dimensional data can be unraveled through lower-dimensional manifold embeddings. Capitalizing on this, DeepInfomax with an unbalanced atlas (DIM-UA) has emerged as a powerful tool and yielded impressive results for state representations in reinforcement learning. Meanwhile, Maximum Manifold Capacity Representation (MMCR) presents a new frontier for SSL by optimizing class separability via manifold compression. However, MMCR demands extensive input views, resulting in significant computational costs and protracted pre-training durations. Bridging this gap, we present an innovative integration of MMCR into existing SSL methods, incorporating a discerning regularization strategy that enhances the lower bound of mutual information. We also propose a novel state representation learning method extending DIM-UA, embedding a nuclear norm loss to enforce manifold consistency robustly. On experimentation with the Atari Annotated RAM Interface, our method improves DIM-UA significantly with the same number of target encoding dimensions. The mean F1 score averaged over categories is 78% compared to 75% of DIM-UA. There are also compelling gains when implementing SimCLR and Barlow Twins. This supports our SSL innovation as a paradigm shift, enabling more nuanced high-dimensional data representations.
A Manifold Representation of the Key in Vision Transformers
Feb 01, 2024Vision Transformers implement multi-head self-attention (MSA) via stacking multiple attention blocks. The query, key, and value are often intertwined and generated within those blocks via a single, shared linear transformation. This paper explores the concept of disentangling the key from the query and value, and adopting a manifold representation for the key. Our experiments reveal that decoupling and endowing the key with a manifold structure can enhance the model performance. Specifically, ViT-B exhibits a 0.87% increase in top-1 accuracy, while Swin-T sees a boost of 0.52% in top-1 accuracy on the ImageNet-1K dataset, with eight charts in the manifold key. Our approach also yields positive results in object detection and instance segmentation tasks on the COCO dataset. Through detailed ablation studies, we establish that these performance gains are not merely due to the simplicity of adding more parameters and computations. Future research may investigate strategies for cutting the budget of such representations and aim for further performance improvements based on our findings.
Generalized Convergence Analysis of Tsetlin Machines: A Probabilistic Approach to Concept Learning
Oct 03, 2023
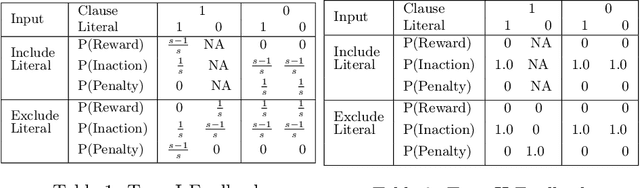
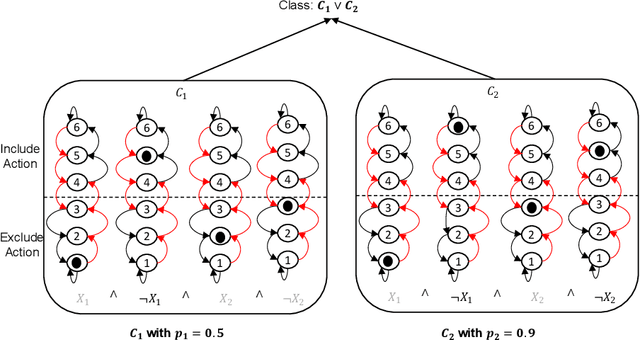
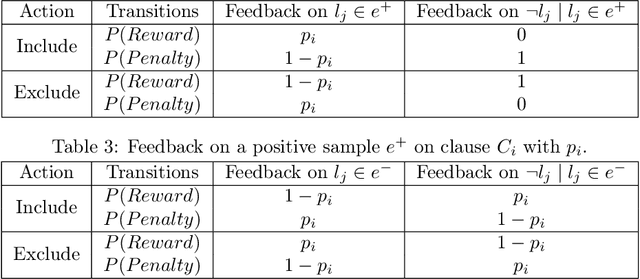
Tsetlin Machines (TMs) have garnered increasing interest for their ability to learn concepts via propositional formulas and their proven efficiency across various application domains. Despite this, the convergence proof for the TMs, particularly for the AND operator (\emph{conjunction} of literals), in the generalized case (inputs greater than two bits) remains an open problem. This paper aims to fill this gap by presenting a comprehensive convergence analysis of Tsetlin automaton-based Machine Learning algorithms. We introduce a novel framework, referred to as Probabilistic Concept Learning (PCL), which simplifies the TM structure while incorporating dedicated feedback mechanisms and dedicated inclusion/exclusion probabilities for literals. Given $n$ features, PCL aims to learn a set of conjunction clauses $C_i$ each associated with a distinct inclusion probability $p_i$. Most importantly, we establish a theoretical proof confirming that, for any clause $C_k$, PCL converges to a conjunction of literals when $0.5<p_k<1$. This result serves as a stepping stone for future research on the convergence properties of Tsetlin automaton-based learning algorithms. Our findings not only contribute to the theoretical understanding of Tsetlin Machines but also have implications for their practical application, potentially leading to more robust and interpretable machine learning models.
State Representation Learning Using an Unbalanced Atlas
May 17, 2023The manifold hypothesis posits that high-dimensional data often lies on a lower-dimensional manifold and that utilizing this manifold as the target space yields more efficient representations. While numerous traditional manifold-based techniques exist for dimensionality reduction, their application in self-supervised learning has witnessed slow progress. The recent MSIMCLR method combines manifold encoding with SimCLR but requires extremely low target encoding dimensions to outperform SimCLR, limiting its applicability. This paper introduces a novel learning paradigm using an unbalanced atlas (UA), capable of surpassing state-of-the-art self-supervised learning approaches. We meticulously investigated and engineered the DeepInfomax with an unbalanced atlas (DIM-UA) method by systematically adapting the Spatiotemporal DeepInfomax (ST-DIM) framework to align with our proposed UA paradigm, employing rigorous scientific methodologies throughout the process. The efficacy of DIM-UA is demonstrated through training and evaluation on the Atari Annotated RAM Interface (AtariARI) benchmark, a modified version of the Atari 2600 framework that produces annotated image samples for representation learning. The UA paradigm improves the existing algorithm significantly when the number of target encoding dimensions grows. For instance, the mean F1 score averaged over categories of DIM-UA is ~75% compared to ~70% of ST-DIM when using 16384 hidden units.
Ensuring Trustworthy Medical Artificial Intelligence through Ethical and Philosophical Principles
Apr 29, 2023Artificial intelligence (AI) methods have great potential to revolutionize numerous medical care by enhancing the experience of medical experts and patients. AI based computer-assisted diagnosis tools can have a tremendous benefit if they can outperform or perform similarly to the level of a clinical expert. As a result, advanced healthcare services can be affordable in developing nations, and the problem of a lack of expert medical practitioners can be addressed. AI based tools can save time, resources, and overall cost for patient treatment. Furthermore, in contrast to humans, AI can uncover complex relations in the data from a large set of inputs and even lead to new evidence-based knowledge in medicine. However, integrating AI in healthcare raises several ethical and philosophical concerns, such as bias, transparency, autonomy, responsibility and accountability, which must be addressed before integrating such tools into clinical settings. In this article, we emphasize recent advances in AI-assisted medical image analysis, existing standards, and the significance of comprehending ethical issues and best practices for the applications of AI in clinical settings. We cover the technical and ethical challenges of AI and the implications of deploying AI in hospitals and public organizations. We also discuss promising key measures and techniques to address the ethical challenges, data scarcity, racial bias, lack of transparency, and algorithmic bias. Finally, we provide our recommendation and future directions for addressing the ethical challenges associated with AI in healthcare applications, with the goal of deploying AI into the clinical settings to make the workflow more efficient, accurate, accessible, transparent, and reliable for the patient worldwide.