 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Graph Representation of Agent Diffusers
May 15, 2025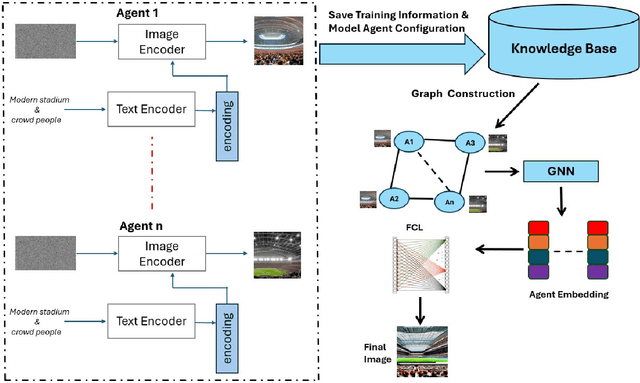

Diffusion-based generative models have significantly advanced text-to-image synthesis, demonstrating impressive text comprehension and zero-shot generalization. These models refine images from random noise based on textual prompts, with initial reliance on text input shifting towards enhanced visual fidelity over time. This transition suggests that static model parameters might not optimally address the distinct phases of generation. We introduce LGR-AD (Learning Graph Representation of Agent Diffusers), a novel multi-agent system designed to improve adaptability in dynamic computer vision tasks. LGR-AD models the generation process as a distributed system of interacting agents, each representing an expert sub-model. These agents dynamically adapt to varying conditions and collaborate through a graph neural network that encodes their relationships and performance metrics. Our approach employs a coordination mechanism based on top-$k$ maximum spanning trees, optimizing the generation process. Each agent's decision-making is guided by a meta-model that minimizes a novel loss function, balancing accuracy and diversity. Theoretical analysis and extensive empirical evaluations show that LGR-AD outperforms traditional diffusion models across various benchmarks, highlighting its potential for scalable and flexible solutions in complex image generation tasks. Code is available at: https://github.com/YousIA/LGR_AD
Efficient Model-Stealing Attacks Against Inductive Graph Neural Networks
May 20, 2024Graph Neural Networks (GNNs) are recognized as potent tools for processing real-world data organized in graph structures. Especially inductive GNNs, which enable the processing of graph-structured data without relying on predefined graph structures, are gaining importance in an increasingly wide variety of applications. As these networks demonstrate proficiency across a range of tasks, they become lucrative targets for model-stealing attacks where an adversary seeks to replicate the functionality of the targeted network. A large effort has been made to develop model-stealing attacks that focus on models trained with images and texts. However, little attention has been paid to GNNs trained on graph data. This paper introduces a novel method for unsupervised model-stealing attacks against inductive GNNs, based on graph contrasting learning and spectral graph augmentations to efficiently extract information from the target model. The proposed attack is thoroughly evaluated on six datasets. The results show that this approach demonstrates a higher level of efficiency compared to existing stealing attacks. More concretely, our attack outperforms the baseline on all benchmarks achieving higher fidelity and downstream accuracy of the stolen model while requiring fewer queries sent to the target model.
Multiagent Model-based Credit Assignment for Continuous Control
Dec 27, 2021
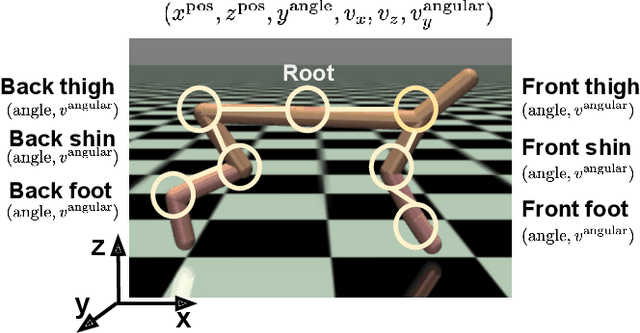
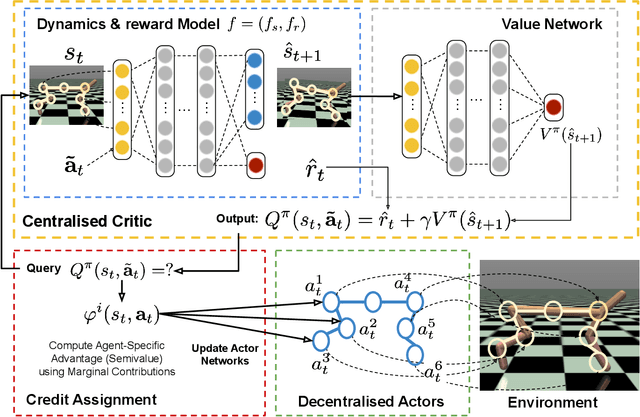
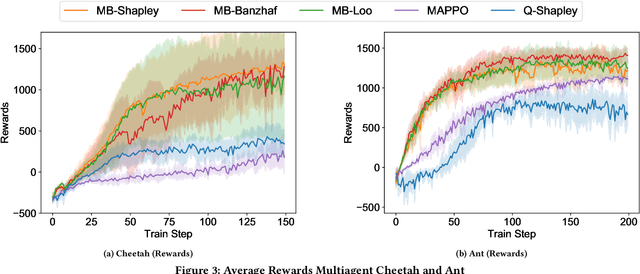
Deep reinforcement learning (RL) has recently shown great promise in robotic continuous control tasks. Nevertheless, prior research in this vein center around the centralized learning setting that largely relies on the communication availability among all the components of a robot. However, agents in the real world often operate in a decentralised fashion without communication due to latency requirements, limited power budgets and safety concerns. By formulating robotic components as a system of decentralised agents, this work presents a decentralised multiagent reinforcement learning framework for continuous control. To this end, we first develop a cooperative multiagent PPO framework that allows for centralized optimisation during training and decentralised operation during execution. However, the system only receives a global reward signal which is not attributed towards each agent. To address this challenge, we further propose a generic game-theoretic credit assignment framework which computes agent-specific reward signals. Last but not least, we also incorporate a model-based RL module into our credit assignment framework, which leads to significant improvement in sample efficiency. We demonstrate the effectiveness of our framework on experimental results on Mujoco locomotion control tasks. For a demo video please visit: https://youtu.be/gFyVPm4svEY.