 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSERUM: Simple, Efficient, Robust, and Unifying Marking for Diffusion-based Image Generation
Mar 11, 2026We propose SERUM: an intriguingly simple yet highly effective method for marking images generated by diffusion models (DMs). We only add a unique watermark noise to the initial diffusion generation noise and train a lightweight detector to identify watermarked images, simplifying and unifying the strengths of prior approaches. SERUM provides robustness against any image augmentations or watermark removal attacks and is extremely efficient, all while maintaining negligible impact on image quality. In contrast to prior approaches, which are often only resilient to limited perturbations and incur significant training, injection, and detection costs, our SERUM achieves remarkable performance, with the highest true positive rate (TPR) at a 1% false positive rate (FPR) in most scenarios, along with fast injection and detection and low detector training overhead. Its decoupled architecture also seamlessly supports multiple users by embedding individualized watermarks with little interference between the marks. Overall, our method provides a practical solution to mark outputs from DMs and to reliably distinguish generated from natural images.
Conditioned Activation Transport for T2I Safety Steering
Mar 03, 2026Despite their impressive capabilities, current Text-to-Image (T2I) models remain prone to generating unsafe and toxic content. While activation steering offers a promising inference-time intervention, we observe that linear activation steering frequently degrades image quality when applied to benign prompts. To address this trade-off, we first construct SafeSteerDataset, a contrastive dataset containing 2300 safe and unsafe prompt pairs with high cosine similarity. Leveraging this data, we propose Conditioned Activation Transport (CAT), a framework that employs a geometry-based conditioning mechanism and nonlinear transport maps. By conditioning transport maps to activate only within unsafe activation regions, we minimize interference with benign queries. We validate our approach on two state-of-the-art architectures: Z-Image and Infinity. Experiments demonstrate that CAT generalizes effectively across these backbones, significantly reducing Attack Success Rate while maintaining image fidelity compared to unsteered generations. Warning: This paper contains potentially offensive text and images.
Curation Leaks: Membership Inference Attacks against Data Curation for Machine Learning
Feb 28, 2026In machine learning, curation is used to select the most valuable data for improving both model accuracy and computational efficiency. Recently, curation has also been explored as a solution for private machine learning: rather than training directly on sensitive data, which is known to leak information through model predictions, the private data is used only to guide the selection of useful public data. The resulting model is then trained solely on curated public data. It is tempting to assume that such a model is privacy-preserving because it has never seen the private data. Yet, we show that without further protection, curation pipelines can still leak private information. Specifically, we introduce novel attacks against popular curation methods, targeting every major step: the computation of curation scores, the selection of the curated subset, and the final trained model. We demonstrate that each stage reveals information about the private dataset and that even models trained exclusively on curated public data leak membership information about the private data that guided curation. These findings highlight the previously overlooked inherent privacy risks of data curation and show that privacy assessment must extend beyond the training procedure to include the data selection process. Our differentially private adaptations of curation methods effectively mitigate leakage, indicating that formal privacy guarantees for curation are a promising direction.
On Stealing Graph Neural Network Models
Nov 13, 2025Current graph neural network (GNN) model-stealing methods rely heavily on queries to the victim model, assuming no hard query limits. However, in reality, the number of allowed queries can be severely limited. In this paper, we demonstrate how an adversary can extract a GNN with very limited interactions with the model. Our approach first enables the adversary to obtain the model backbone without making direct queries to the victim model and then to strategically utilize a fixed query limit to extract the most informative data. The experiments on eight real-world datasets demonstrate the effectiveness of the attack, even under a very restricted query limit and under defense against model extraction in place. Our findings underscore the need for robust defenses against GNN model extraction threats.
Memorization in Graph Neural Networks
Aug 26, 2025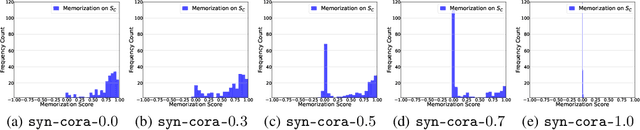

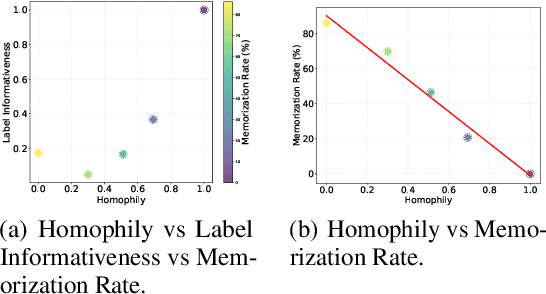
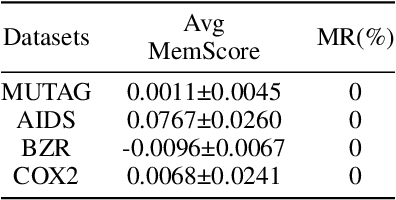
Deep neural networks (DNNs) have been shown to memorize their training data, yet similar analyses for graph neural networks (GNNs) remain largely under-explored. We introduce NCMemo (Node Classification Memorization), the first framework to quantify label memorization in semi-supervised node classification. We first establish an inverse relationship between memorization and graph homophily, i.e., the property that connected nodes share similar labels/features. We find that lower homophily significantly increases memorization, indicating that GNNs rely on memorization to learn less homophilic graphs. Secondly, we analyze GNN training dynamics. We find that the increased memorization in low homophily graphs is tightly coupled to the GNNs' implicit bias on using graph structure during learning. In low homophily regimes, this structure is less informative, hence inducing memorization of the node labels to minimize training loss. Finally, we show that nodes with higher label inconsistency in their feature-space neighborhood are significantly more prone to memorization. Building on our insights into the link between graph homophily and memorization, we investigate graph rewiring as a means to mitigate memorization. Our results demonstrate that this approach effectively reduces memorization without compromising model performance. Moreover, we show that it lowers the privacy risk for previously memorized data points in practice. Thus, our work not only advances understanding of GNN learning but also supports more privacy-preserving GNN deployment.
Adversarial Attacks and Defenses on Graph-aware Large Language Models (LLMs)
Aug 06, 2025Large Language Models (LLMs) are increasingly integrated with graph-structured data for tasks like node classification, a domain traditionally dominated by Graph Neural Networks (GNNs). While this integration leverages rich relational information to improve task performance, their robustness against adversarial attacks remains unexplored. We take the first step to explore the vulnerabilities of graph-aware LLMs by leveraging existing adversarial attack methods tailored for graph-based models, including those for poisoning (training-time attacks) and evasion (test-time attacks), on two representative models, LLAGA (Chen et al. 2024) and GRAPHPROMPTER (Liu et al. 2024). Additionally, we discover a new attack surface for LLAGA where an attacker can inject malicious nodes as placeholders into the node sequence template to severely degrade its performance. Our systematic analysis reveals that certain design choices in graph encoding can enhance attack success, with specific findings that: (1) the node sequence template in LLAGA increases its vulnerability; (2) the GNN encoder used in GRAPHPROMPTER demonstrates greater robustness; and (3) both approaches remain susceptible to imperceptible feature perturbation attacks. Finally, we propose an end-to-end defense framework GALGUARD, that combines an LLM-based feature correction module to mitigate feature-level perturbations and adapted GNN defenses to protect against structural attacks.
Finding Dori: Memorization in Text-to-Image Diffusion Models Is Less Local Than Assumed
Jul 22, 2025Text-to-image diffusion models (DMs) have achieved remarkable success in image generation. However, concerns about data privacy and intellectual property remain due to their potential to inadvertently memorize and replicate training data. Recent mitigation efforts have focused on identifying and pruning weights responsible for triggering replication, based on the assumption that memorization can be localized. Our research assesses the robustness of these pruning-based approaches. We demonstrate that even after pruning, minor adjustments to text embeddings of input prompts are sufficient to re-trigger data replication, highlighting the fragility of these defenses. Furthermore, we challenge the fundamental assumption of memorization locality, by showing that replication can be triggered from diverse locations within the text embedding space, and follows different paths in the model. Our findings indicate that existing mitigation strategies are insufficient and underscore the need for methods that truly remove memorized content, rather than attempting to suppress its retrieval. As a first step in this direction, we introduce a novel adversarial fine-tuning method that iteratively searches for replication triggers and updates the model to increase robustness. Through our research, we provide fresh insights into the nature of memorization in text-to-image DMs and a foundation for building more trustworthy and compliant generative AI.
Implementing Adaptations for Vision AutoRegressive Model
Jul 15, 2025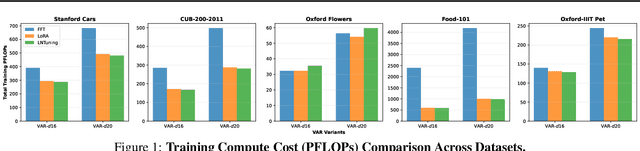

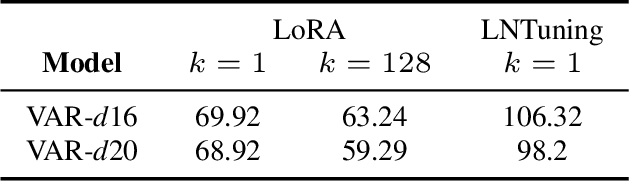
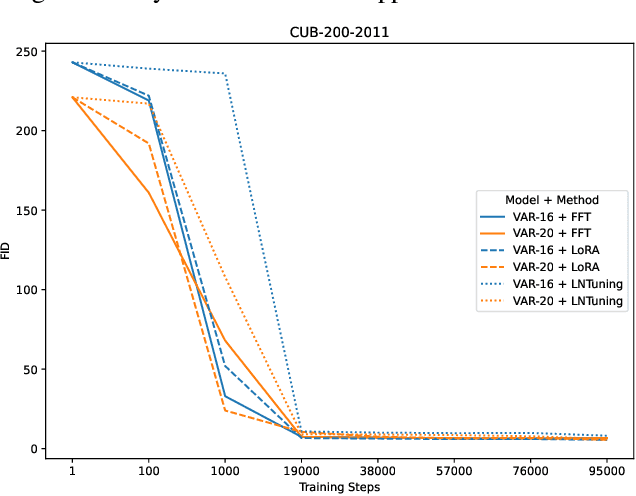
Vision AutoRegressive model (VAR) was recently introduced as an alternative to Diffusion Models (DMs) in image generation domain. In this work we focus on its adaptations, which aim to fine-tune pre-trained models to perform specific downstream tasks, like medical data generation. While for DMs there exist many techniques, adaptations for VAR remain underexplored. Similarly, differentially private (DP) adaptations-ones that aim to preserve privacy of the adaptation data-have been extensively studied for DMs, while VAR lacks such solutions. In our work, we implement and benchmark many strategies for VAR, and compare them to state-of-the-art DM adaptation strategies. We observe that VAR outperforms DMs for non-DP adaptations, however, the performance of DP suffers, which necessitates further research in private adaptations for VAR. Code is available at https://github.com/sprintml/finetuning_var_dp.
Unlocking Post-hoc Dataset Inference with Synthetic Data
Jun 18, 2025The remarkable capabilities of Large Language Models (LLMs) can be mainly attributed to their massive training datasets, which are often scraped from the internet without respecting data owners' intellectual property rights. Dataset Inference (DI) offers a potential remedy by identifying whether a suspect dataset was used in training, thereby enabling data owners to verify unauthorized use. However, existing DI methods require a private set-known to be absent from training-that closely matches the compromised dataset's distribution. Such in-distribution, held-out data is rarely available in practice, severely limiting the applicability of DI. In this work, we address this challenge by synthetically generating the required held-out set. Our approach tackles two key obstacles: (1) creating high-quality, diverse synthetic data that accurately reflects the original distribution, which we achieve via a data generator trained on a carefully designed suffix-based completion task, and (2) bridging likelihood gaps between real and synthetic data, which is realized through post-hoc calibration. Extensive experiments on diverse text datasets show that using our generated data as a held-out set enables DI to detect the original training sets with high confidence, while maintaining a low false positive rate. This result empowers copyright owners to make legitimate claims on data usage and demonstrates our method's reliability for real-world litigations. Our code is available at https://github.com/sprintml/PostHocDatasetInference.
Strong Membership Inference Attacks on Massive Datasets and (Moderately) Large Language Models
May 24, 2025State-of-the-art membership inference attacks (MIAs) typically require training many reference models, making it difficult to scale these attacks to large pre-trained language models (LLMs). As a result, prior research has either relied on weaker attacks that avoid training reference models (e.g., fine-tuning attacks), or on stronger attacks applied to small-scale models and datasets. However, weaker attacks have been shown to be brittle - achieving close-to-arbitrary success - and insights from strong attacks in simplified settings do not translate to today's LLMs. These challenges have prompted an important question: are the limitations observed in prior work due to attack design choices, or are MIAs fundamentally ineffective on LLMs? We address this question by scaling LiRA - one of the strongest MIAs - to GPT-2 architectures ranging from 10M to 1B parameters, training reference models on over 20B tokens from the C4 dataset. Our results advance the understanding of MIAs on LLMs in three key ways: (1) strong MIAs can succeed on pre-trained LLMs; (2) their effectiveness, however, remains limited (e.g., AUC<0.7) in practical settings; and, (3) the relationship between MIA success and related privacy metrics is not as straightforward as prior work has suggested.