 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLocalizing and Correcting Errors for LLM-based Planners
Jan 30, 2026Large language models (LLMs) have demonstrated strong reasoning capabilities on math and coding, but frequently fail on symbolic classical planning tasks. Our studies, as well as prior work, show that LLM-generated plans routinely violate domain constraints given in their instructions (e.g., walking through walls). To address this failure, we propose iteratively augmenting instructions with Localized In-Context Learning (L-ICL) demonstrations: targeted corrections for specific failing steps. Specifically, L-ICL identifies the first constraint violation in a trace and injects a minimal input-output example giving the correct behavior for the failing step. Our proposed technique of L-ICL is much effective than explicit instructions or traditional ICL, which adds complete problem-solving trajectories, and many other baselines. For example, on an 8x8 gridworld, L-ICL produces valid plans 89% of the time with only 60 training examples, compared to 59% for the best baseline, an increase of 30%. L-ICL also shows dramatic improvements in other domains (gridworld navigation, mazes, Sokoban, and BlocksWorld), and on several LLM architectures.
Learning temporal embeddings from electronic health records of chronic kidney disease patients
Jan 26, 2026We investigate whether temporal embedding models trained on longitudinal electronic health records can learn clinically meaningful representations without compromising predictive performance, and how architectural choices affect embedding quality. Model-guided medicine requires representations that capture disease dynamics while remaining transparent and task agnostic, whereas most clinical prediction models are optimised for a single task. Representation learning facilitates learning embeddings that generalise across downstream tasks, and recurrent architectures are well-suited for modelling temporal structure in observational clinical data. Using the MIMIC-IV dataset, we study patients with chronic kidney disease (CKD) and compare three recurrent architectures: a vanilla LSTM, an attention-augmented LSTM, and a time-aware LSTM (T-LSTM). All models are trained both as embedding models and as direct end-to-end predictors. Embedding quality is evaluated via CKD stage clustering and in-ICU mortality prediction. The T-LSTM produces more structured embeddings, achieving a lower Davies-Bouldin Index (DBI = 9.91) and higher CKD stage classification accuracy (0.74) than the vanilla LSTM (DBI = 15.85, accuracy = 0.63) and attention-augmented LSTM (DBI = 20.72, accuracy = 0.67). For in-ICU mortality prediction, embedding models consistently outperform end-to-end predictors, improving accuracy from 0.72-0.75 to 0.82-0.83, which indicates that learning embeddings as an intermediate step is more effective than direct end-to-end learning.
Temporal Fusion Nexus: A task-agnostic multi-modal embedding model for clinical narratives and irregular time series in post-kidney transplant care
Jan 13, 2026We introduce Temporal Fusion Nexus (TFN), a multi-modal and task-agnostic embedding model to integrate irregular time series and unstructured clinical narratives. We analysed TFN in post-kidney transplant (KTx) care, with a retrospective cohort of 3382 patients, on three key outcomes: graft loss, graft rejection, and mortality. Compared to state-of-the-art model in post KTx care, TFN achieved higher performance for graft loss (AUC 0.96 vs. 0.94) and graft rejection (AUC 0.84 vs. 0.74). In mortality prediction, TFN yielded an AUC of 0.86. TFN outperformed unimodal baselines (approx 10% AUC improvement over time series only baseline, approx 5% AUC improvement over time series with static patient data). Integrating clinical text improved performance across all tasks. Disentanglement metrics confirmed robust and interpretable latent factors in the embedding space, and SHAP-based attributions confirmed alignment with clinical reasoning. TFN has potential application in clinical tasks beyond KTx, where heterogeneous data sources, irregular longitudinal data, and rich narrative documentation are available.
A Roadmap for Applying Graph Neural Networks to Numerical Data: Insights from Cementitious Materials
Dec 16, 2025Machine learning (ML) has been increasingly applied in concrete research to optimize performance and mixture design. However, one major challenge in applying ML to cementitious materials is the limited size and diversity of available databases. A promising solution is the development of multi-modal databases that integrate both numerical and graphical data. Conventional ML frameworks in cement research are typically restricted to a single data modality. Graph neural network (GNN) represents a new generation of neural architectures capable of learning from data structured as graphs, capturing relationships through irregular or topology-dependent connections rather than fixed spatial coordinates. While GNN is inherently designed for graphical data, they can be adapted to extract correlations from numerical datasets and potentially embed physical laws directly into their architecture, enabling explainable and physics-informed predictions. This work is among the first few studies to implement GNNs to design concrete, with a particular emphasis on establishing a clear and reproducible pathway for converting tabular data into graph representations using the k-nearest neighbor (K-NN) approach. Model hyperparameters and feature selection are systematically optimized to enhance prediction performance. The GNN shows performance comparable to the benchmark random forest, which has been demonstrated by many studies to yield reliable predictions for cementitious materials. Overall, this study provides a foundational roadmap for transitioning from traditional ML to advanced AI architectures. The proposed framework establishes a strong foundation for future multi-modal and physics-informed GNN models capable of capturing complex material behaviors and accelerating the design and optimization of cementitious materials.
Kornia-rs: A Low-Level 3D Computer Vision Library In Rust
May 18, 2025We present \textit{kornia-rs}, a high-performance 3D computer vision library written entirely in native Rust, designed for safety-critical and real-time applications. Unlike C++-based libraries like OpenCV or wrapper-based solutions like OpenCV-Rust, \textit{kornia-rs} is built from the ground up to leverage Rust's ownership model and type system for memory and thread safety. \textit{kornia-rs} adopts a statically-typed tensor system and a modular set of crates, providing efficient image I/O, image processing and 3D operations. To aid cross-platform compatibility, \textit{kornia-rs} offers Python bindings, enabling seamless and efficient integration with Rust code. Empirical results show that \textit{kornia-rs} achieves a 3~ 5 times speedup in image transformation tasks over native Rust alternatives, while offering comparable performance to C++ wrapper-based libraries. In addition to 2D vision capabilities, \textit{kornia-rs} addresses a significant gap in the Rust ecosystem by providing a set of 3D computer vision operators. This paper presents the architecture and performance characteristics of \textit{kornia-rs}, demonstrating its effectiveness in real-world computer vision applications.
Building Machine Learning Challenges for Anomaly Detection in Science
Mar 03, 2025



Scientific discoveries are often made by finding a pattern or object that was not predicted by the known rules of science. Oftentimes, these anomalous events or objects that do not conform to the norms are an indication that the rules of science governing the data are incomplete, and something new needs to be present to explain these unexpected outliers. The challenge of finding anomalies can be confounding since it requires codifying a complete knowledge of the known scientific behaviors and then projecting these known behaviors on the data to look for deviations. When utilizing machine learning, this presents a particular challenge since we require that the model not only understands scientific data perfectly but also recognizes when the data is inconsistent and out of the scope of its trained behavior. In this paper, we present three datasets aimed at developing machine learning-based anomaly detection for disparate scientific domains covering astrophysics, genomics, and polar science. We present the different datasets along with a scheme to make machine learning challenges around the three datasets findable, accessible, interoperable, and reusable (FAIR). Furthermore, we present an approach that generalizes to future machine learning challenges, enabling the possibility of large, more compute-intensive challenges that can ultimately lead to scientific discovery.
Med-gte-hybrid: A contextual embedding transformer model for extracting actionable information from clinical texts
Feb 21, 2025We introduce a novel contextual embedding model med-gte-hybrid that was derived from the gte-large sentence transformer to extract information from unstructured clinical narratives. Our model tuning strategy for med-gte-hybrid combines contrastive learning and a denoising autoencoder. To evaluate the performance of med-gte-hybrid, we investigate several clinical prediction tasks in large patient cohorts extracted from the MIMIC-IV dataset, including Chronic Kidney Disease (CKD) patient prognosis, estimated glomerular filtration rate (eGFR) prediction, and patient mortality prediction. Furthermore, we demonstrate that the med-gte-hybrid model improves patient stratification, clustering, and text retrieval, thus outperforms current state-of-the-art models on the Massive Text Embedding Benchmark (MTEB). While some of our evaluations focus on CKD, our hybrid tuning of sentence transformers could be transferred to other medical domains and has the potential to improve clinical decision-making and personalised treatment pathways in various healthcare applications.
Beautiful Images, Toxic Words: Understanding and Addressing Offensive Text in Generated Images
Feb 10, 2025State-of-the-art visual generation models, such as Diffusion Models (DMs) and Vision Auto-Regressive Models (VARs), produce highly realistic images. While prior work has successfully mitigated Not Safe For Work (NSFW) content in the visual domain, we identify a novel threat: the generation of NSFW text embedded within images. This includes offensive language, such as insults, racial slurs, and sexually explicit terms, posing significant risks to users. We show that all state-of-the-art DMs (e.g., SD3, Flux, DeepFloyd IF) and VARs (e.g., Infinity) are vulnerable to this issue. Through extensive experiments, we demonstrate that existing mitigation techniques, effective for visual content, fail to prevent harmful text generation while substantially degrading benign text generation. As an initial step toward addressing this threat, we explore safety fine-tuning of the text encoder underlying major DM architectures using a customized dataset. Thereby, we suppress NSFW generation while preserving overall image and text generation quality. Finally, to advance research in this area, we introduce ToxicBench, an open-source benchmark for evaluating NSFW text generation in images. ToxicBench provides a curated dataset of harmful prompts, new metrics, and an evaluation pipeline assessing both NSFW-ness and generation quality. Our benchmark aims to guide future efforts in mitigating NSFW text generation in text-to-image models.
Neural Computing
Jul 06, 2021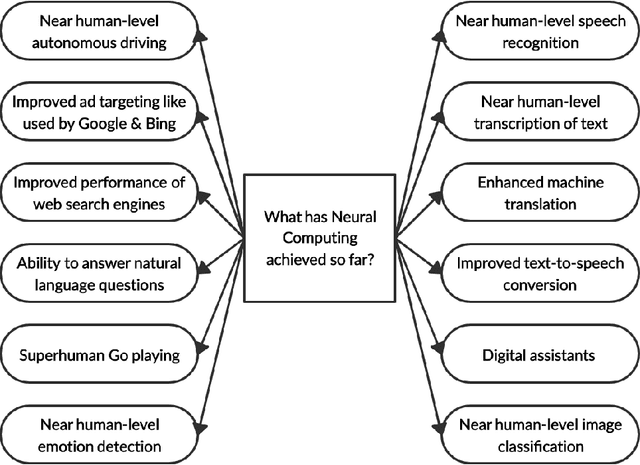
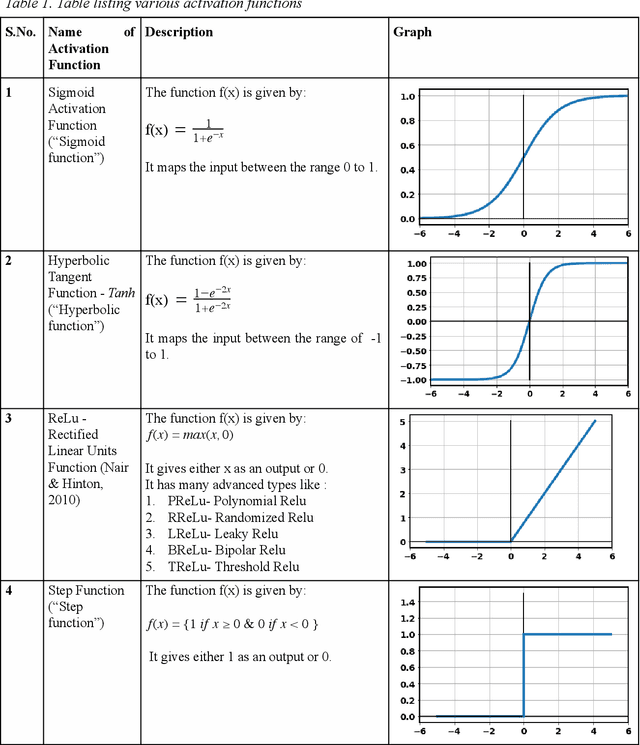
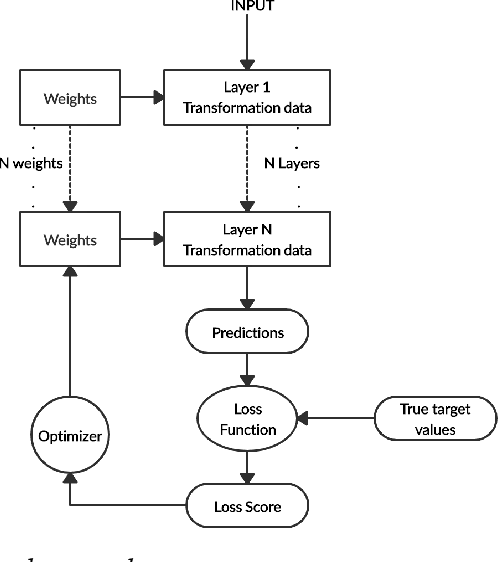

This chapter aims to provide next-level understanding of the problems of the world and the solutions available to those problems, which lie very well within the domain of neural computing, and at the same time are intelligent in their approach, to invoke a sense of innovation among the educationalists, researchers, academic professionals, students and people concerned, by highlighting the work done by major researchers and innovators in this field and thus, encouraging the readers to develop newer and more advanced techniques for the same. By means of this chapter, the societal problems are discussed and various solutions are also given by means of the theories presented and researches done so far. Different types of neural networks discovered so far and applications of some of those neural networks are focused on, apart from their theoretical understanding, the working and core concepts involved in the applications.