 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKornia-rs: A Low-Level 3D Computer Vision Library In Rust
May 18, 2025We present \textit{kornia-rs}, a high-performance 3D computer vision library written entirely in native Rust, designed for safety-critical and real-time applications. Unlike C++-based libraries like OpenCV or wrapper-based solutions like OpenCV-Rust, \textit{kornia-rs} is built from the ground up to leverage Rust's ownership model and type system for memory and thread safety. \textit{kornia-rs} adopts a statically-typed tensor system and a modular set of crates, providing efficient image I/O, image processing and 3D operations. To aid cross-platform compatibility, \textit{kornia-rs} offers Python bindings, enabling seamless and efficient integration with Rust code. Empirical results show that \textit{kornia-rs} achieves a 3~ 5 times speedup in image transformation tasks over native Rust alternatives, while offering comparable performance to C++ wrapper-based libraries. In addition to 2D vision capabilities, \textit{kornia-rs} addresses a significant gap in the Rust ecosystem by providing a set of 3D computer vision operators. This paper presents the architecture and performance characteristics of \textit{kornia-rs}, demonstrating its effectiveness in real-world computer vision applications.
Characterizing Out-of-Distribution Error via Optimal Transport
May 25, 2023Out-of-distribution (OOD) data poses serious challenges in deployed machine learning models, so methods of predicting a model's performance on OOD data without labels are important for machine learning safety. While a number of methods have been proposed by prior work, they often underestimate the actual error, sometimes by a large margin, which greatly impacts their applicability to real tasks. In this work, we identify pseudo-label shift, or the difference between the predicted and true OOD label distributions, as a key indicator to this underestimation. Based on this observation, we introduce a novel method for estimating model performance by leveraging optimal transport theory, Confidence Optimal Transport (COT), and show that it provably provides more robust error estimates in the presence of pseudo-label shift. Additionally, we introduce an empirically-motivated variant of COT, Confidence Optimal Transport with Thresholding (COTT), which applies thresholding to the individual transport costs and further improves the accuracy of COT's error estimates. We evaluate COT and COTT on a variety of standard benchmarks that induce various types of distribution shift -- synthetic, novel subpopulation, and natural -- and show that our approaches significantly outperform existing state-of-the-art methods with an up to 3x lower prediction error.
SMODICE: Versatile Offline Imitation Learning via State Occupancy Matching
Feb 04, 2022


We propose State Matching Offline DIstribution Correction Estimation (SMODICE), a novel and versatile algorithm for offline imitation learning (IL) via state-occupancy matching. We show that the SMODICE objective admits a simple optimization procedure through an application of Fenchel duality and an analytic solution in tabular MDPs. Without requiring access to expert actions, SMODICE can be effectively applied to three offline IL settings: (i) imitation from observations (IfO), (ii) IfO with dynamics or morphologically mismatched expert, and (iii) example-based reinforcement learning, which we show can be formulated as a state-occupancy matching problem. We extensively evaluate SMODICE on both gridworld environments as well as on high-dimensional offline benchmarks. Our results demonstrate that SMODICE is effective for all three problem settings and significantly outperforms prior state-of-art.
Conservative and Adaptive Penalty for Model-Based Safe Reinforcement Learning
Dec 14, 2021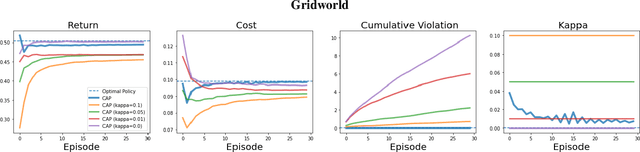


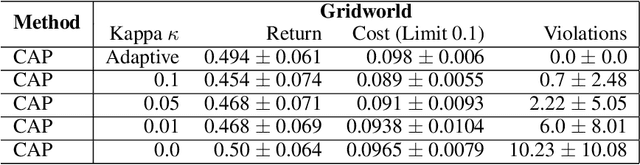
Reinforcement Learning (RL) agents in the real world must satisfy safety constraints in addition to maximizing a reward objective. Model-based RL algorithms hold promise for reducing unsafe real-world actions: they may synthesize policies that obey all constraints using simulated samples from a learned model. However, imperfect models can result in real-world constraint violations even for actions that are predicted to satisfy all constraints. We propose Conservative and Adaptive Penalty (CAP), a model-based safe RL framework that accounts for potential modeling errors by capturing model uncertainty and adaptively exploiting it to balance the reward and the cost objectives. First, CAP inflates predicted costs using an uncertainty-based penalty. Theoretically, we show that policies that satisfy this conservative cost constraint are guaranteed to also be feasible in the true environment. We further show that this guarantees the safety of all intermediate solutions during RL training. Further, CAP adaptively tunes this penalty during training using true cost feedback from the environment. We evaluate this conservative and adaptive penalty-based approach for model-based safe RL extensively on state and image-based environments. Our results demonstrate substantial gains in sample-efficiency while incurring fewer violations than prior safe RL algorithms. Code is available at: https://github.com/Redrew/CAP