 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYou Don't Need All Attentions: Distributed Dynamic Fine-Tuning for Foundation Models
Apr 16, 2025Fine-tuning plays a crucial role in adapting models to downstream tasks with minimal training efforts. However, the rapidly increasing size of foundation models poses a daunting challenge for accommodating foundation model fine-tuning in most commercial devices, which often have limited memory bandwidth. Techniques like model sharding and tensor parallelism address this issue by distributing computation across multiple devices to meet memory requirements. Nevertheless, these methods do not fully leverage their foundation nature in facilitating the fine-tuning process, resulting in high computational costs and imbalanced workloads. We introduce a novel Distributed Dynamic Fine-Tuning (D2FT) framework that strategically orchestrates operations across attention modules based on our observation that not all attention modules are necessary for forward and backward propagation in fine-tuning foundation models. Through three innovative selection strategies, D2FT significantly reduces the computational workload required for fine-tuning foundation models. Furthermore, D2FT addresses workload imbalances in distributed computing environments by optimizing these selection strategies via multiple knapsack optimization. Our experimental results demonstrate that the proposed D2FT framework reduces the training computational costs by 40% and training communication costs by 50% with only 1% to 2% accuracy drops on the CIFAR-10, CIFAR-100, and Stanford Cars datasets. Moreover, the results show that D2FT can be effectively extended to recent LoRA, a state-of-the-art parameter-efficient fine-tuning technique. By reducing 40% computational cost or 50% communication cost, D2FT LoRA top-1 accuracy only drops 4% to 6% on Stanford Cars dataset.
Characterizing Out-of-Distribution Error via Optimal Transport
May 25, 2023Out-of-distribution (OOD) data poses serious challenges in deployed machine learning models, so methods of predicting a model's performance on OOD data without labels are important for machine learning safety. While a number of methods have been proposed by prior work, they often underestimate the actual error, sometimes by a large margin, which greatly impacts their applicability to real tasks. In this work, we identify pseudo-label shift, or the difference between the predicted and true OOD label distributions, as a key indicator to this underestimation. Based on this observation, we introduce a novel method for estimating model performance by leveraging optimal transport theory, Confidence Optimal Transport (COT), and show that it provably provides more robust error estimates in the presence of pseudo-label shift. Additionally, we introduce an empirically-motivated variant of COT, Confidence Optimal Transport with Thresholding (COTT), which applies thresholding to the individual transport costs and further improves the accuracy of COT's error estimates. We evaluate COT and COTT on a variety of standard benchmarks that induce various types of distribution shift -- synthetic, novel subpopulation, and natural -- and show that our approaches significantly outperform existing state-of-the-art methods with an up to 3x lower prediction error.
Predicting Out-of-Distribution Error with Confidence Optimal Transport
Feb 10, 2023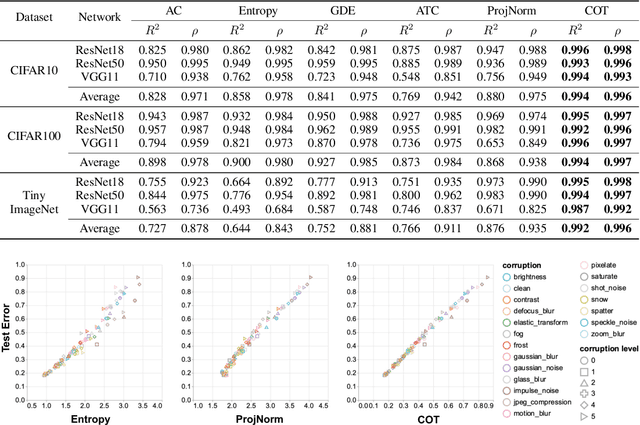
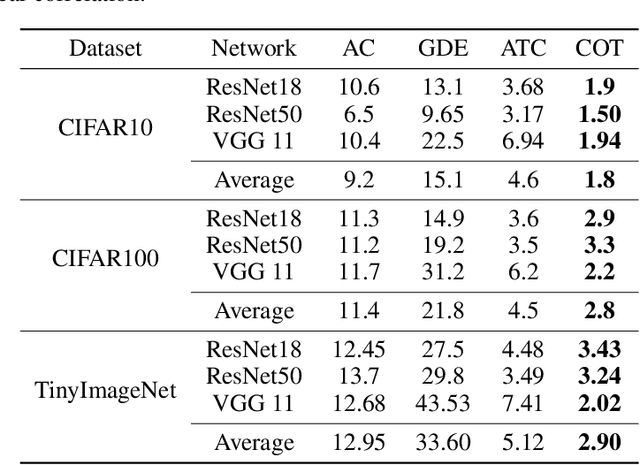
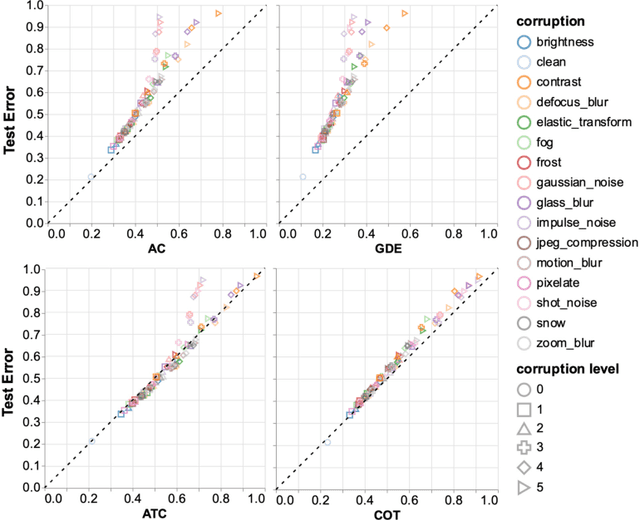
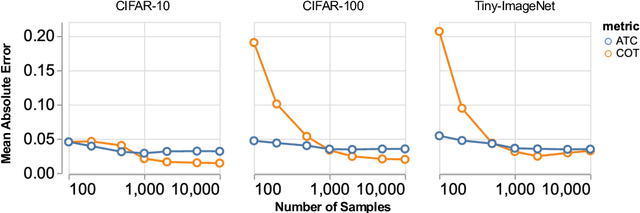
Out-of-distribution (OOD) data poses serious challenges in deployed machine learning models as even subtle changes could incur significant performance drops. Being able to estimate a model's performance on test data is important in practice as it indicates when to trust to model's decisions. We present a simple yet effective method to predict a model's performance on an unknown distribution without any addition annotation. Our approach is rooted in the Optimal Transport theory, viewing test samples' output softmax scores from deep neural networks as empirical samples from an unknown distribution. We show that our method, Confidence Optimal Transport (COT), provides robust estimates of a model's performance on a target domain. Despite its simplicity, our method achieves state-of-the-art results on three benchmark datasets and outperforms existing methods by a large margin.
Best Arm Identification with Safety Constraints
Nov 23, 2021

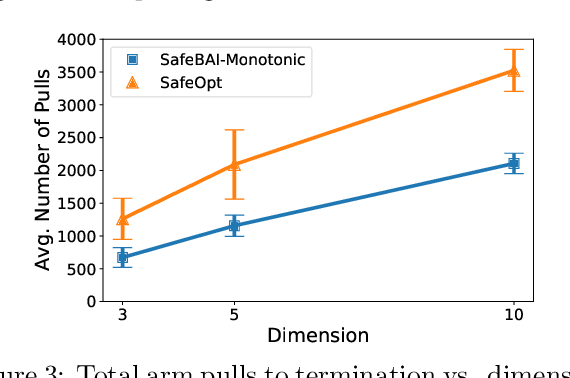
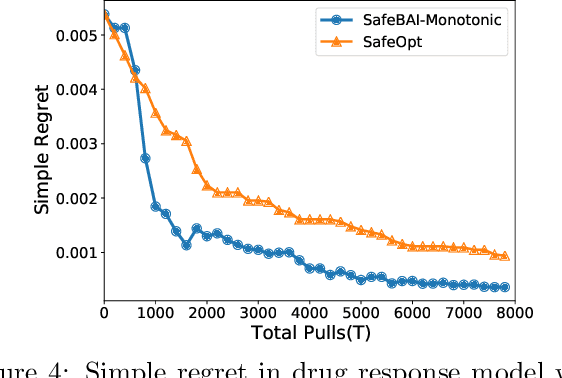
The best arm identification problem in the multi-armed bandit setting is an excellent model of many real-world decision-making problems, yet it fails to capture the fact that in the real-world, safety constraints often must be met while learning. In this work we study the question of best-arm identification in safety-critical settings, where the goal of the agent is to find the best safe option out of many, while exploring in a way that guarantees certain, initially unknown safety constraints are met. We first analyze this problem in the setting where the reward and safety constraint takes a linear structure, and show nearly matching upper and lower bounds. We then analyze a much more general version of the problem where we only assume the reward and safety constraint can be modeled by monotonic functions, and propose an algorithm in this setting which is guaranteed to learn safely. We conclude with experimental results demonstrating the effectiveness of our approaches in scenarios such as safely identifying the best drug out of many in order to treat an illness.
Max-Min Grouped Bandits
Nov 17, 2021


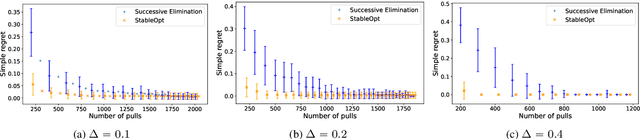
In this paper, we introduce a multi-armed bandit problem termed max-min grouped bandits, in which the arms are arranged in possibly-overlapping groups, and the goal is to find a group whose worst arm has the highest mean reward. This problem is of interest in applications such as recommendation systems, and is also closely related to widely-studied robust optimization problems. We present two algorithms based successive elimination and robust optimization, and derive upper bounds on the number of samples to guarantee finding a max-min optimal or near-optimal group, as well as an algorithm-independent lower bound. We discuss the degree of tightness of our bounds in various cases of interest, and the difficulties in deriving uniformly tight bounds.
GRAPHSPY: Fused Program Semantic-Level Embedding via Graph Neural Networks for Dead Store Detection
Nov 18, 2020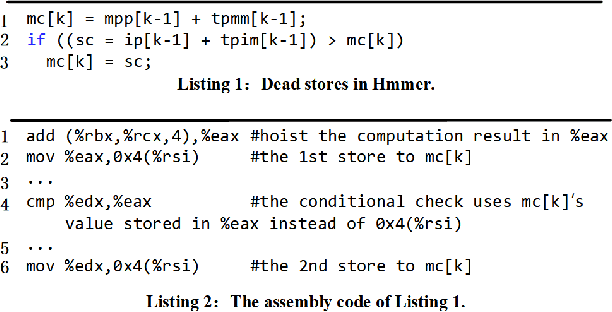
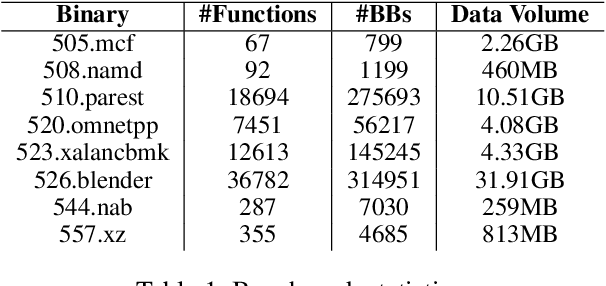
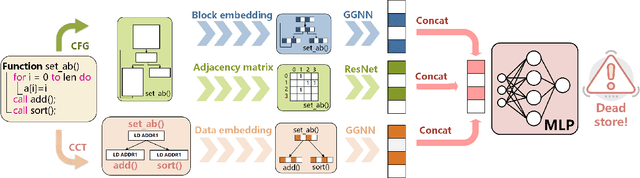
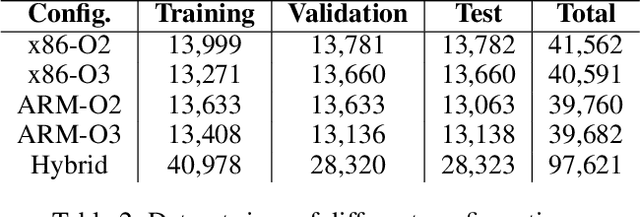
Production software oftentimes suffers from the issue of performance inefficiencies caused by inappropriate use of data structures, programming abstractions, and conservative compiler optimizations. It is desirable to avoid unnecessary memory operations. However, existing works often use a whole-program fine-grained monitoring method with incredibly high overhead. To this end, we propose a learning-aided approach to identify unnecessary memory operations intelligently with low overhead. By applying several prevalent graph neural network models to extract program semantics with respect to program structure, execution order and dynamic states, we present a novel, hybrid program embedding approach so that to derive unnecessary memory operations through the embedding. We train our model with tens of thousands of samples acquired from a set of real-world benchmarks. Results show that our model achieves 90% of accuracy and incurs only around a half of time overhead of the state-of-art tool.