 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRoboReward: General-Purpose Vision-Language Reward Models for Robotics
Jan 08, 2026A well-designed reward is critical for effective reinforcement learning-based policy improvement. In real-world robotics, obtaining such rewards typically requires either labor-intensive human labeling or brittle, handcrafted objectives. Vision-language models (VLMs) have shown promise as automatic reward models, yet their effectiveness on real robot tasks is poorly understood. In this work, we aim to close this gap by introducing (1) RoboReward, a robotics reward dataset and benchmark built on large-scale real-robot corpora from Open X-Embodiment (OXE) and RoboArena, and (2) vision-language reward models trained on this dataset (RoboReward 4B/8B). Because OXE is success-heavy and lacks failure examples, we propose a negative examples data augmentation pipeline that generates calibrated negative and near-misses via counterfactual relabeling of successful episodes and temporal clipping to create partial-progress outcomes from the same videos. Using this framework, we build a large training and evaluation dataset spanning diverse tasks and embodiments to test whether state-of-the-art VLMs can reliably provide rewards for robot learning. Our evaluation of open and proprietary VLMs finds that no model excels across tasks, highlighting substantial room for improvement. We then train general-purpose 4B- and 8B-parameter models that outperform much larger VLMs in assigning rewards for short-horizon robotic tasks. Finally, we deploy the 8B model in real-robot reinforcement learning and find that it improves policy learning over Gemini Robotics-ER 1.5 while narrowing the gap to RL training with human-provided rewards. We release the full dataset, trained reward models, and evaluation suite on our website to advance the development of general-purpose reward models in robotics: https://crfm.stanford.edu/helm/robo-reward-bench (project website).
Robust Finetuning of Vision-Language-Action Robot Policies via Parameter Merging
Dec 18, 2025Generalist robot policies, trained on large and diverse datasets, have demonstrated the ability to generalize across a wide spectrum of behaviors, enabling a single policy to act in varied real-world environments. However, they still fall short on new tasks not covered in the training data. When finetuned on limited demonstrations of a new task, these policies often overfit to the specific demonstrations--not only losing their prior abilities to solve a wide variety of generalist tasks but also failing to generalize within the new task itself. In this work, we aim to develop a method that preserves the generalization capabilities of the generalist policy during finetuning, allowing a single policy to robustly incorporate a new skill into its repertoire. Our goal is a single policy that both learns to generalize to variations of the new task and retains the broad competencies gained from pretraining. We show that this can be achieved through a simple yet effective strategy: interpolating the weights of a finetuned model with that of the pretrained model. We show, across extensive simulated and real-world experiments, that such model merging produces a single model that inherits the generalist abilities of the base model and learns to solve the new task robustly, outperforming both the pretrained and finetuned model on out-of-distribution variations of the new task. Moreover, we show that model merging performance scales with the amount of pretraining data, and enables continual acquisition of new skills in a lifelong learning setting, without sacrificing previously learned generalist abilities.
Posterior Behavioral Cloning: Pretraining BC Policies for Efficient RL Finetuning
Dec 18, 2025Standard practice across domains from robotics to language is to first pretrain a policy on a large-scale demonstration dataset, and then finetune this policy, typically with reinforcement learning (RL), in order to improve performance on deployment domains. This finetuning step has proved critical in achieving human or super-human performance, yet while much attention has been given to developing more effective finetuning algorithms, little attention has been given to ensuring the pretrained policy is an effective initialization for RL finetuning. In this work we seek to understand how the pretrained policy affects finetuning performance, and how to pretrain policies in order to ensure they are effective initializations for finetuning. We first show theoretically that standard behavioral cloning (BC) -- which trains a policy to directly match the actions played by the demonstrator -- can fail to ensure coverage over the demonstrator's actions, a minimal condition necessary for effective RL finetuning. We then show that if, instead of exactly fitting the observed demonstrations, we train a policy to model the posterior distribution of the demonstrator's behavior given the demonstration dataset, we do obtain a policy that ensures coverage over the demonstrator's actions, enabling more effective finetuning. Furthermore, this policy -- which we refer to as the posterior behavioral cloning (PostBC) policy -- achieves this while ensuring pretrained performance is no worse than that of the BC policy. We then show that PostBC is practically implementable with modern generative models in robotic control domains -- relying only on standard supervised learning -- and leads to significantly improved RL finetuning performance on both realistic robotic control benchmarks and real-world robotic manipulation tasks, as compared to standard behavioral cloning.
Active learning of neural population dynamics using two-photon holographic optogenetics
Dec 03, 2024



Recent advances in techniques for monitoring and perturbing neural populations have greatly enhanced our ability to study circuits in the brain. In particular, two-photon holographic optogenetics now enables precise photostimulation of experimenter-specified groups of individual neurons, while simultaneous two-photon calcium imaging enables the measurement of ongoing and induced activity across the neural population. Despite the enormous space of potential photostimulation patterns and the time-consuming nature of photostimulation experiments, very little algorithmic work has been done to determine the most effective photostimulation patterns for identifying the neural population dynamics. Here, we develop methods to efficiently select which neurons to stimulate such that the resulting neural responses will best inform a dynamical model of the neural population activity. Using neural population responses to photostimulation in mouse motor cortex, we demonstrate the efficacy of a low-rank linear dynamical systems model, and develop an active learning procedure which takes advantage of low-rank structure to determine informative photostimulation patterns. We demonstrate our approach on both real and synthetic data, obtaining in some cases as much as a two-fold reduction in the amount of data required to reach a given predictive power. Our active stimulation design method is based on a novel active learning procedure for low-rank regression, which may be of independent interest.
Overcoming the Sim-to-Real Gap: Leveraging Simulation to Learn to Explore for Real-World RL
Oct 26, 2024



In order to mitigate the sample complexity of real-world reinforcement learning, common practice is to first train a policy in a simulator where samples are cheap, and then deploy this policy in the real world, with the hope that it generalizes effectively. Such \emph{direct sim2real} transfer is not guaranteed to succeed, however, and in cases where it fails, it is unclear how to best utilize the simulator. In this work, we show that in many regimes, while direct sim2real transfer may fail, we can utilize the simulator to learn a set of \emph{exploratory} policies which enable efficient exploration in the real world. In particular, in the setting of low-rank MDPs, we show that coupling these exploratory policies with simple, practical approaches -- least-squares regression oracles and naive randomized exploration -- yields a polynomial sample complexity in the real world, an exponential improvement over direct sim2real transfer, or learning without access to a simulator. To the best of our knowledge, this is the first evidence that simulation transfer yields a provable gain in reinforcement learning in settings where direct sim2real transfer fails. We validate our theoretical results on several realistic robotic simulators and a real-world robotic sim2real task, demonstrating that transferring exploratory policies can yield substantial gains in practice as well.
Corruption-Robust Linear Bandits: Minimax Optimality and Gap-Dependent Misspecification
Oct 10, 2024


In linear bandits, how can a learner effectively learn when facing corrupted rewards? While significant work has explored this question, a holistic understanding across different adversarial models and corruption measures is lacking, as is a full characterization of the minimax regret bounds. In this work, we compare two types of corruptions commonly considered: strong corruption, where the corruption level depends on the action chosen by the learner, and weak corruption, where the corruption level does not depend on the action chosen by the learner. We provide a unified framework to analyze these corruptions. For stochastic linear bandits, we fully characterize the gap between the minimax regret under strong and weak corruptions. We also initiate the study of corrupted adversarial linear bandits, obtaining upper and lower bounds with matching dependencies on the corruption level. Next, we reveal a connection between corruption-robust learning and learning with gap-dependent mis-specification, a setting first studied by Liu et al. (2023a), where the misspecification level of an action or policy is proportional to its suboptimality. We present a general reduction that enables any corruption-robust algorithm to handle gap-dependent misspecification. This allows us to recover the results of Liu et al. (2023a) in a black-box manner and significantly generalize them to settings like linear MDPs, yielding the first results for gap-dependent misspecification in reinforcement learning. However, this general reduction does not attain the optimal rate for gap-dependent misspecification. Motivated by this, we develop a specialized algorithm that achieves optimal bounds for gap-dependent misspecification in linear bandits, thus answering an open question posed by Liu et al. (2023a).
Humor in AI: Massive Scale Crowd-Sourced Preferences and Benchmarks for Cartoon Captioning
Jun 15, 2024

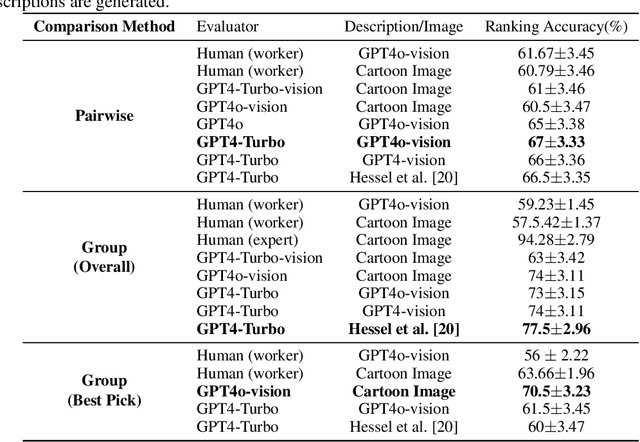
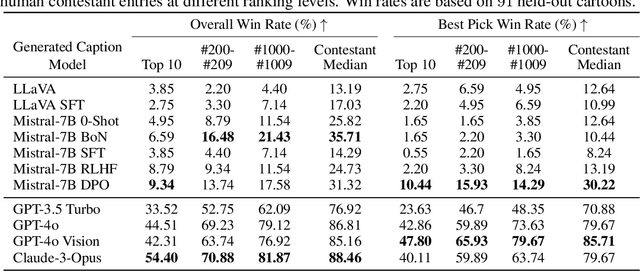
We present a novel multimodal preference dataset for creative tasks, consisting of over 250 million human ratings on more than 2.2 million captions, collected through crowdsourcing rating data for The New Yorker's weekly cartoon caption contest over the past eight years. This unique dataset supports the development and evaluation of multimodal large language models and preference-based fine-tuning algorithms for humorous caption generation. We propose novel benchmarks for judging the quality of model-generated captions, utilizing both GPT4 and human judgments to establish ranking-based evaluation strategies. Our experimental results highlight the limitations of current fine-tuning methods, such as RLHF and DPO, when applied to creative tasks. Furthermore, we demonstrate that even state-of-the-art models like GPT4 and Claude currently underperform top human contestants in generating humorous captions. As we conclude this extensive data collection effort, we release the entire preference dataset to the research community, fostering further advancements in AI humor generation and evaluation.
Sample Complexity Reduction via Policy Difference Estimation in Tabular Reinforcement Learning
Jun 11, 2024


In this paper, we study the non-asymptotic sample complexity for the pure exploration problem in contextual bandits and tabular reinforcement learning (RL): identifying an epsilon-optimal policy from a set of policies with high probability. Existing work in bandits has shown that it is possible to identify the best policy by estimating only the difference between the behaviors of individual policies, which can be substantially cheaper than estimating the behavior of each policy directly. However, the best-known complexities in RL fail to take advantage of this and instead estimate the behavior of each policy directly. Does it suffice to estimate only the differences in the behaviors of policies in RL? We answer this question positively for contextual bandits but in the negative for tabular RL, showing a separation between contextual bandits and RL. However, inspired by this, we show that it almost suffices to estimate only the differences in RL: if we can estimate the behavior of a single reference policy, it suffices to only estimate how any other policy deviates from this reference policy. We develop an algorithm which instantiates this principle and obtains, to the best of our knowledge, the tightest known bound on the sample complexity of tabular RL.
ASID: Active Exploration for System Identification in Robotic Manipulation
Apr 18, 2024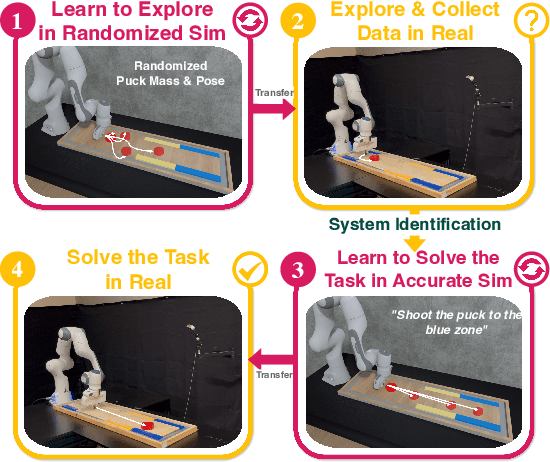

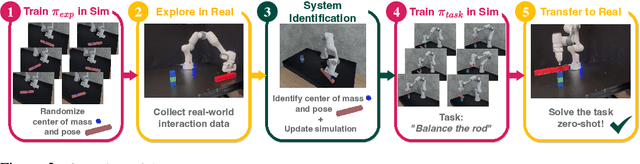

Model-free control strategies such as reinforcement learning have shown the ability to learn control strategies without requiring an accurate model or simulator of the world. While this is appealing due to the lack of modeling requirements, such methods can be sample inefficient, making them impractical in many real-world domains. On the other hand, model-based control techniques leveraging accurate simulators can circumvent these challenges and use a large amount of cheap simulation data to learn controllers that can effectively transfer to the real world. The challenge with such model-based techniques is the requirement for an extremely accurate simulation, requiring both the specification of appropriate simulation assets and physical parameters. This requires considerable human effort to design for every environment being considered. In this work, we propose a learning system that can leverage a small amount of real-world data to autonomously refine a simulation model and then plan an accurate control strategy that can be deployed in the real world. Our approach critically relies on utilizing an initial (possibly inaccurate) simulator to design effective exploration policies that, when deployed in the real world, collect high-quality data. We demonstrate the efficacy of this paradigm in identifying articulation, mass, and other physical parameters in several challenging robotic manipulation tasks, and illustrate that only a small amount of real-world data can allow for effective sim-to-real transfer. Project website at https://weirdlabuw.github.io/asid
Fair Active Learning in Low-Data Regimes
Dec 13, 2023In critical machine learning applications, ensuring fairness is essential to avoid perpetuating social inequities. In this work, we address the challenges of reducing bias and improving accuracy in data-scarce environments, where the cost of collecting labeled data prohibits the use of large, labeled datasets. In such settings, active learning promises to maximize marginal accuracy gains of small amounts of labeled data. However, existing applications of active learning for fairness fail to deliver on this, typically requiring large labeled datasets, or failing to ensure the desired fairness tolerance is met on the population distribution. To address such limitations, we introduce an innovative active learning framework that combines an exploration procedure inspired by posterior sampling with a fair classification subroutine. We demonstrate that this framework performs effectively in very data-scarce regimes, maximizing accuracy while satisfying fairness constraints with high probability. We evaluate our proposed approach using well-established real-world benchmark datasets and compare it against state-of-the-art methods, demonstrating its effectiveness in producing fair models, and improvement over existing methods.