 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Steering Techniques using Human Similarity Judgments
May 25, 2025



Current evaluations of Large Language Model (LLM) steering techniques focus on task-specific performance, overlooking how well steered representations align with human cognition. Using a well-established triadic similarity judgment task, we assessed steered LLMs on their ability to flexibly judge similarity between concepts based on size or kind. We found that prompt-based steering methods outperformed other methods both in terms of steering accuracy and model-to-human alignment. We also found LLMs were biased towards 'kind' similarity and struggled with 'size' alignment. This evaluation approach, grounded in human cognition, adds further support to the efficacy of prompt-based steering and reveals privileged representational axes in LLMs prior to steering.
AI-enhanced semantic feature norms for 786 concepts
May 15, 2025Semantic feature norms have been foundational in the study of human conceptual knowledge, yet traditional methods face trade-offs between concept/feature coverage and verifiability of quality due to the labor-intensive nature of norming studies. Here, we introduce a novel approach that augments a dataset of human-generated feature norms with responses from large language models (LLMs) while verifying the quality of norms against reliable human judgments. We find that our AI-enhanced feature norm dataset, NOVA: Norms Optimized Via AI, shows much higher feature density and overlap among concepts while outperforming a comparable human-only norm dataset and word-embedding models in predicting people's semantic similarity judgments. Taken together, we demonstrate that human conceptual knowledge is richer than captured in previous norm datasets and show that, with proper validation, LLMs can serve as powerful tools for cognitive science research.
Bridging the Creativity Understanding Gap: Small-Scale Human Alignment Enables Expert-Level Humor Ranking in LLMs
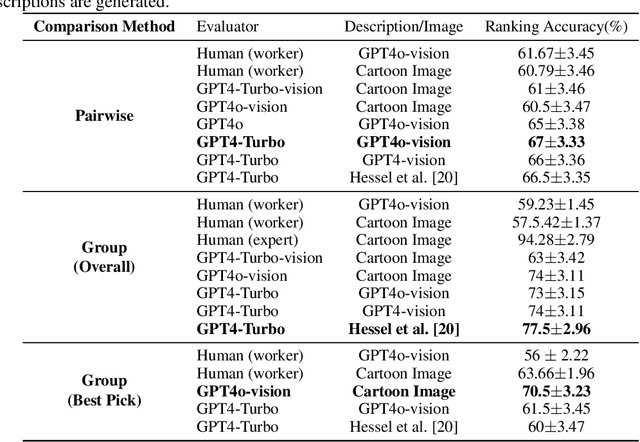
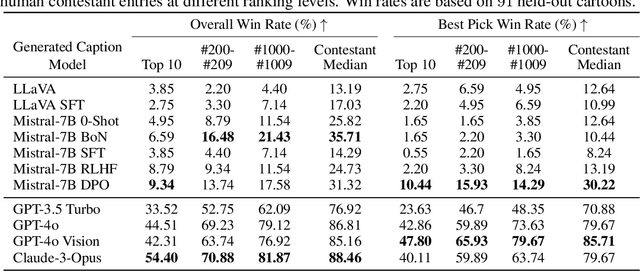
Feb 27, 2025Large Language Models (LLMs) have shown significant limitations in understanding creative content, as demonstrated by Hessel et al. (2023)'s influential work on the New Yorker Cartoon Caption Contest (NYCCC). Their study exposed a substantial gap between LLMs and humans in humor comprehension, establishing that understanding and evaluating creative content is key challenge in AI development. We revisit this challenge by decomposing humor understanding into three components and systematically improve each: enhancing visual understanding through improved annotation, utilizing LLM-generated humor reasoning and explanations, and implementing targeted alignment with human preference data. Our refined approach achieves 82.4% accuracy in caption ranking, singificantly improving upon the previous 67% benchmark and matching the performance of world-renowned human experts in this domain. Notably, while attempts to mimic subgroup preferences through various persona prompts showed minimal impact, model finetuning with crowd preferences proved remarkably effective. These findings reveal that LLM limitations in creative judgment can be effectively addressed through focused alignment to specific subgroups and individuals. Lastly, we propose the position that achieving artificial general intelligence necessitates systematic collection of human preference data across creative domains. We advocate that just as human creativity is deeply influenced by individual and cultural preferences, training LLMs with diverse human preference data may be essential for developing true creative understanding.
Probing LLM World Models: Enhancing Guesstimation with Wisdom of Crowds Decoding
Jan 30, 2025



Guesstimation, the task of making approximate quantity estimates, is a common real-world challenge. However, it has been largely overlooked in large language models (LLMs) and vision language models (VLMs) research. We introduce a novel guesstimation dataset, MARBLES. This dataset requires one to estimate how many items (e.g., marbles) can fit into containers (e.g., a one-cup measuring cup), both with and without accompanying images. Inspired by the social science concept of the ``Wisdom of Crowds'' (WOC) - taking the median from estimates from a crowd), which has proven effective in guesstimation, we propose ``WOC decoding'' strategy for LLM guesstimation. We show that LLMs/VLMs perform well on guesstimation, suggesting that they possess some level of a "world model" necessary for guesstimation. Moreover, similar to human performance, the WOC decoding method improves LLM/VLM guesstimation accuracy. Furthermore, the inclusion of images in the multimodal condition enhances model performance. These results highlight the value of WOC decoding strategy for LLMs/VLMs and position guesstimation as a probe for evaluating LLMs/VLMs' world model. As LLMs' world model is a fundamental prerequisite for many real-world tasks, e.g., human-AI teaming, our findings have broad implications for the AI community.
Humor in AI: Massive Scale Crowd-Sourced Preferences and Benchmarks for Cartoon Captioning
Jun 15, 2024

We present a novel multimodal preference dataset for creative tasks, consisting of over 250 million human ratings on more than 2.2 million captions, collected through crowdsourcing rating data for The New Yorker's weekly cartoon caption contest over the past eight years. This unique dataset supports the development and evaluation of multimodal large language models and preference-based fine-tuning algorithms for humorous caption generation. We propose novel benchmarks for judging the quality of model-generated captions, utilizing both GPT4 and human judgments to establish ranking-based evaluation strategies. Our experimental results highlight the limitations of current fine-tuning methods, such as RLHF and DPO, when applied to creative tasks. Furthermore, we demonstrate that even state-of-the-art models like GPT4 and Claude currently underperform top human contestants in generating humorous captions. As we conclude this extensive data collection effort, we release the entire preference dataset to the research community, fostering further advancements in AI humor generation and evaluation.
Simulating Opinion Dynamics with Networks of LLM-based Agents
Nov 16, 2023Accurately simulating human opinion dynamics is crucial for understanding a variety of societal phenomena, including polarization and the spread of misinformation. However, the agent-based models (ABMs) commonly used for such simulations lack fidelity to human behavior. We propose a new approach to simulating opinion dynamics based on populations of Large Language Models (LLMs). Our findings reveal a strong inherent bias in LLM agents towards accurate information, leading to consensus in line with scientific reality. However, this bias limits the simulation of individuals with resistant views on issues like climate change. After inducing confirmation bias through prompt engineering, we observed opinion fragmentation in line with existing agent-based research. These insights highlight the promise and limitations of LLM agents in this domain and suggest a path forward: refining LLMs with real-world discourse to better simulate the evolution of human beliefs.
Evaluating LLM Agent Group Dynamics against Human Group Dynamics: A Case Study on Wisdom of Partisan Crowds
Nov 16, 2023



This study investigates the potential of Large Language Models (LLMs) to simulate human group dynamics, particularly within politically charged contexts. We replicate the Wisdom of Partisan Crowds phenomenon using LLMs to role-play as Democrat and Republican personas, engaging in a structured interaction akin to human group study. Our approach evaluates how agents' responses evolve through social influence. Our key findings indicate that LLM agents role-playing detailed personas and without Chain-of-Thought (CoT) reasoning closely align with human behaviors, while having CoT reasoning hurts the alignment. However, incorporating explicit biases into agent prompts does not necessarily enhance the wisdom of partisan crowds. Moreover, fine-tuning LLMs with human data shows promise in achieving human-like behavior but poses a risk of overfitting certain behaviors. These findings show the potential and limitations of using LLM agents in modeling human group phenomena.
Learning interactions to boost human creativity with bandits and GPT-4
Nov 16, 2023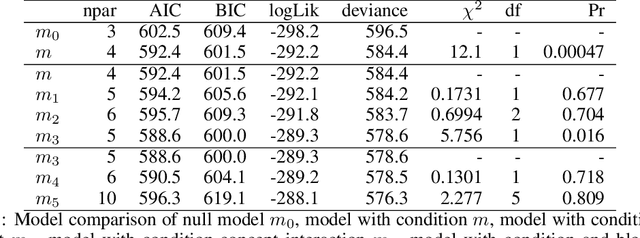
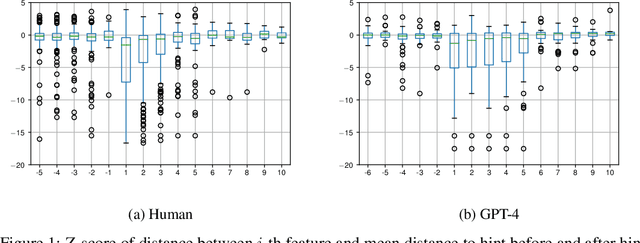
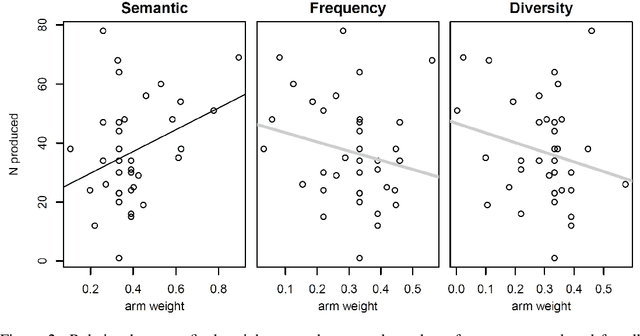

This paper considers how interactions with AI algorithms can boost human creative thought. We employ a psychological task that demonstrates limits on human creativity, namely semantic feature generation: given a concept name, respondents must list as many of its features as possible. Human participants typically produce only a fraction of the features they know before getting "stuck." In experiments with humans and with a language AI (GPT-4) we contrast behavior in the standard task versus a variant in which participants can ask for algorithmically-generated hints. Algorithm choice is administered by a multi-armed bandit whose reward indicates whether the hint helped generating more features. Humans and the AI show similar benefits from hints, and remarkably, bandits learning from AI responses prefer the same prompting strategy as those learning from human behavior. The results suggest that strategies for boosting human creativity via computer interactions can be learned by bandits run on groups of simulated participants.
Semantic Feature Verification in FLAN-T5
Apr 12, 2023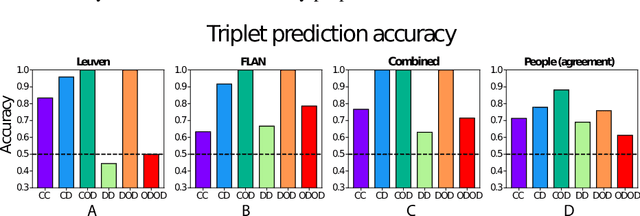
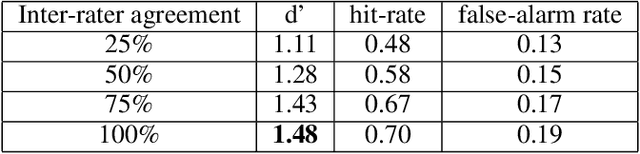

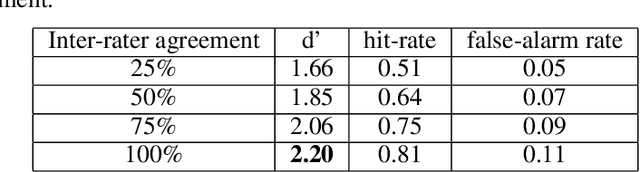
This study evaluates the potential of a large language model for aiding in generation of semantic feature norms - a critical tool for evaluating conceptual structure in cognitive science. Building from an existing human-generated dataset, we show that machine-verified norms capture aspects of conceptual structure beyond what is expressed in human norms alone, and better explain human judgments of semantic similarity amongst items that are distally related. The results suggest that LLMs can greatly enhance traditional methods of semantic feature norm verification, with implications for our understanding of conceptual representation in humans and machines.
Human-machine cooperation for semantic feature listing
Apr 11, 2023
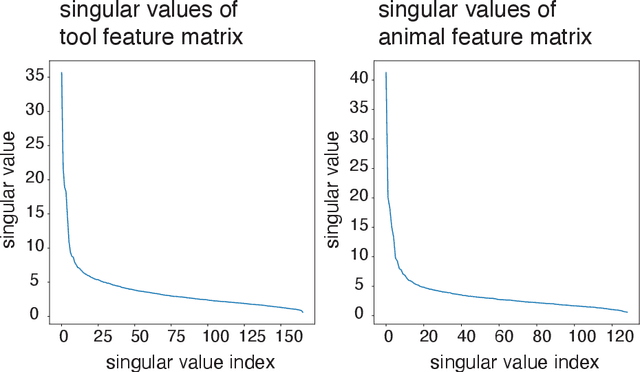


Semantic feature norms, lists of features that concepts do and do not possess, have played a central role in characterizing human conceptual knowledge, but require extensive human labor. Large language models (LLMs) offer a novel avenue for the automatic generation of such feature lists, but are prone to significant error. Here, we present a new method for combining a learned model of human lexical-semantics from limited data with LLM-generated data to efficiently generate high-quality feature norms.