 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridging the Creativity Understanding Gap: Small-Scale Human Alignment Enables Expert-Level Humor Ranking in LLMs
Feb 27, 2025Large Language Models (LLMs) have shown significant limitations in understanding creative content, as demonstrated by Hessel et al. (2023)'s influential work on the New Yorker Cartoon Caption Contest (NYCCC). Their study exposed a substantial gap between LLMs and humans in humor comprehension, establishing that understanding and evaluating creative content is key challenge in AI development. We revisit this challenge by decomposing humor understanding into three components and systematically improve each: enhancing visual understanding through improved annotation, utilizing LLM-generated humor reasoning and explanations, and implementing targeted alignment with human preference data. Our refined approach achieves 82.4% accuracy in caption ranking, singificantly improving upon the previous 67% benchmark and matching the performance of world-renowned human experts in this domain. Notably, while attempts to mimic subgroup preferences through various persona prompts showed minimal impact, model finetuning with crowd preferences proved remarkably effective. These findings reveal that LLM limitations in creative judgment can be effectively addressed through focused alignment to specific subgroups and individuals. Lastly, we propose the position that achieving artificial general intelligence necessitates systematic collection of human preference data across creative domains. We advocate that just as human creativity is deeply influenced by individual and cultural preferences, training LLMs with diverse human preference data may be essential for developing true creative understanding.
Unifying Generative and Dense Retrieval for Sequential Recommendation
Nov 27, 2024

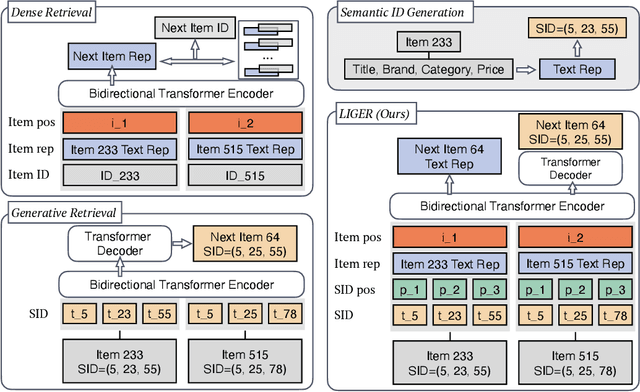
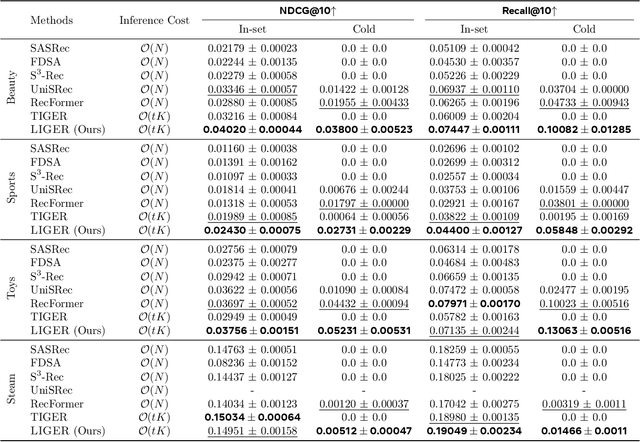
Sequential dense retrieval models utilize advanced sequence learning techniques to compute item and user representations, which are then used to rank relevant items for a user through inner product computation between the user and all item representations. However, this approach requires storing a unique representation for each item, resulting in significant memory requirements as the number of items grow. In contrast, the recently proposed generative retrieval paradigm offers a promising alternative by directly predicting item indices using a generative model trained on semantic IDs that encapsulate items' semantic information. Despite its potential for large-scale applications, a comprehensive comparison between generative retrieval and sequential dense retrieval under fair conditions is still lacking, leaving open questions regarding performance, and computation trade-offs. To address this, we compare these two approaches under controlled conditions on academic benchmarks and propose LIGER (LeveragIng dense retrieval for GEnerative Retrieval), a hybrid model that combines the strengths of these two widely used methods. LIGER integrates sequential dense retrieval into generative retrieval, mitigating performance differences and enhancing cold-start item recommendation in the datasets evaluated. This hybrid approach provides insights into the trade-offs between these approaches and demonstrates improvements in efficiency and effectiveness for recommendation systems in small-scale benchmarks.
LabelBench: A Comprehensive Framework for Benchmarking Label-Efficient Learning
Jun 16, 2023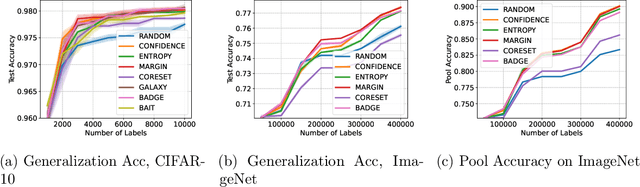


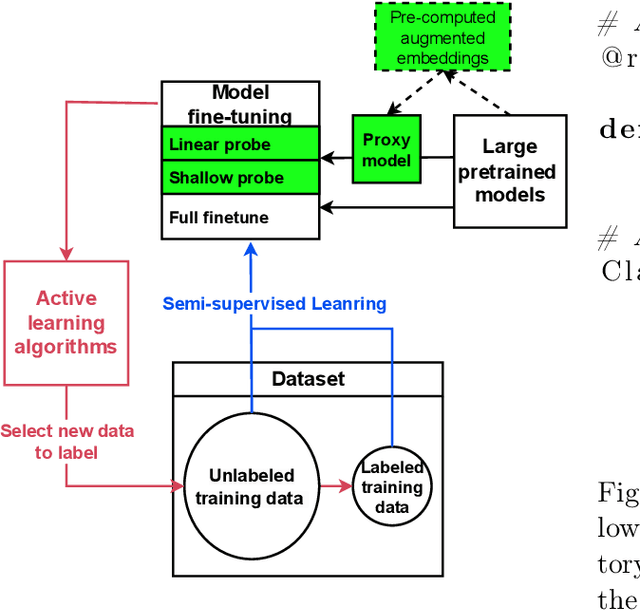
Labeled data are critical to modern machine learning applications, but obtaining labels can be expensive. To mitigate this cost, machine learning methods, such as transfer learning, semi-supervised learning and active learning, aim to be label-efficient: achieving high predictive performance from relatively few labeled examples. While obtaining the best label-efficiency in practice often requires combinations of these techniques, existing benchmark and evaluation frameworks do not capture a concerted combination of all such techniques. This paper addresses this deficiency by introducing LabelBench, a new computationally-efficient framework for joint evaluation of multiple label-efficient learning techniques. As an application of LabelBench, we introduce a novel benchmark of state-of-the-art active learning methods in combination with semi-supervised learning for fine-tuning pretrained vision transformers. Our benchmark demonstrates better label-efficiencies than previously reported in active learning. LabelBench's modular codebase is open-sourced for the broader community to contribute label-efficient learning methods and benchmarks. The repository can be found at: https://github.com/EfficientTraining/LabelBench.