 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Well Does Generative Recommendation Generalize?
Mar 20, 2026A widely held hypothesis for why generative recommendation (GR) models outperform conventional item ID-based models is that they generalize better. However, there is few systematic way to verify this hypothesis beyond a superficial comparison of overall performance. To address this gap, we categorize each data instance based on the specific capability required for a correct prediction: either memorization (reusing item transition patterns observed during training) or generalization (composing known patterns to predict unseen item transitions). Extensive experiments show that GR models perform better on instances that require generalization, whereas item ID-based models perform better when memorization is more important. To explain this divergence, we shift the analysis from the item level to the token level and show that what appears to be item-level generalization often reduces to token-level memorization for GR models. Finally, we show that the two paradigms are complementary. We propose a simple memorization-aware indicator that adaptively combines them on a per-instance basis, leading to improved overall recommendation performance.
CCR-Bench: A Comprehensive Benchmark for Evaluating LLMs on Complex Constraints, Control Flows, and Real-World Cases
Mar 09, 2026Enhancing the ability of large language models (LLMs) to follow complex instructions is critical for their deployment in real-world applications. However, existing evaluation methods often oversimplify instruction complexity as a mere additive combination of atomic constraints, failing to adequately capture the high-dimensional complexity arising from the intricate interplay of content and format, logical workflow control, and real-world applications. This leads to a significant gap between current evaluation practices and practical demands. To bridge this gap, we introduce CCR-Bench, a novel benchmark designed to assess LLMs' adherence to complex instructions. CCR-Bench is characterized by: (1) deep entanglement of content and formatting requirements in task specifications; (2) instructions that involve intricate task decomposition, conditional reasoning, and procedural planning; and (3) evaluation samples derived entirely from real-world industrial scenarios. Extensive experiments on CCR-Bench demonstrate that even state-of-the-art models exhibit substantial performance deficiencies, clearly quantifying the gap between current LLM capabilities and the demands of realworld instruction understanding. We believe that CCR-Bench offers a more rigorous and realistic evaluation framework, advancing the development of LLMs toward the next generation of models capable of understanding and executing complex tasks in industrial applications.
ML-DCN: Masked Low-Rank Deep Crossing Network Towards Scalable Ads Click-through Rate Prediction at Pinterest
Feb 09, 2026Deep learning recommendation systems rely on feature interaction modules to model complex user-item relationships across sparse categorical and dense features. In large-scale ad ranking, increasing model capacity is a promising path to improving both predictive performance and business outcomes, yet production serving budgets impose strict constraints on latency and FLOPs. This creates a central tension: we want interaction modules that both scale effectively with additional compute and remain compute-efficient at serving time. In this work, we study how to scale feature interaction modules under a fixed serving budget. We find that naively scaling DCNv2 and MaskNet, despite their widespread adoption in industry, yields rapidly diminishing offline gains in the Pinterest ads ranking system. To overcome aforementioned limitations, we propose ML-DCN, an interaction module that integrates an instance-conditioned mask into a low-rank crossing layer, enabling per-example selection and amplification of salient interaction directions while maintaining efficient computation. This novel architecture combines the strengths of DCNv2 and MaskNet, scales efficiently with increased compute, and achieves state-of-the-art performance. Experiments on a large internal Pinterest ads dataset show that ML-DCN achieves higher AUC than DCNv2, MaskNet, and recent scaling-oriented alternatives at matched FLOPs, and it scales more favorably overall as compute increases, exhibiting a stronger AUC-FLOPs trade-off. Finally, online A/B tests demonstrate statistically significant improvements in key ads metrics (including CTR and click-quality measures) and ML-DCN has been deployed in the production system with neutral serving cost.
A Consistency-Improved LiDAR-Inertial Bundle Adjustment
Feb 06, 2026Simultaneous Localization and Mapping (SLAM) using 3D LiDAR has emerged as a cornerstone for autonomous navigation in robotics. While feature-based SLAM systems have achieved impressive results by leveraging edge and planar structures, they often suffer from the inconsistent estimator associated with feature parameterization and estimated covariance. In this work, we present a consistency-improved LiDAR-inertial bundle adjustment (BA) with tailored parameterization and estimator. First, we propose a stereographic-projection representation parameterizing the planar and edge features, and conduct a comprehensive observability analysis to support its integrability with consistent estimator. Second, we implement a LiDAR-inertial BA with Maximum a Posteriori (MAP) formulation and First-Estimate Jacobians (FEJ) to preserve the accurate estimated covariance and observability properties of the system. Last, we apply our proposed BA method to a LiDAR-inertial odometry.
Don't Forget Its Variance! The Minimum Path Variance Principle for Accurate and Stable Score-Based Density Ratio Estimation
Jan 31, 2026Score-based methods have emerged as a powerful framework for density ratio estimation (DRE), but they face an important paradox in that, while theoretically path-independent, their practical performance depends critically on the chosen path schedule. We resolve this issue by proving that tractable training objectives differ from the ideal, ground-truth objective by a crucial, overlooked term: the path variance of the time score. To address this, we propose MinPV (\textbf{Min}imum \textbf{P}ath \textbf{V}ariance) Principle, which introduces a principled heuristic to minimize the overlooked path variance. Our key contribution is the derivation of a closed-form expression for the variance, turning an intractable problem into a tractable optimization. By parameterizing the path with a flexible Kumaraswamy Mixture Model, our method learns a data-adaptive, low-variance path without heuristic selection. This principled optimization of the complete objective yields more accurate and stable estimators, establishing new state-of-the-art results on challenging benchmarks.
AFA-LoRA: Enabling Non-Linear Adaptations in LoRA with Activation Function Annealing
Dec 27, 2025Low-Rank Adaptation (LoRA) is a widely adopted parameter-efficient fine-tuning (PEFT) method. However, its linear adaptation process limits its expressive power. This means there is a gap between the expressive power of linear training and non-linear training. To bridge this gap, we propose AFA-LoRA, a novel training strategy that brings non-linear expressivity to LoRA while maintaining its seamless mergeability. Our key innovation is an annealed activation function that transitions from a non-linear to a linear transformation during training, allowing the adapter to initially adopt stronger representational capabilities before converging to a mergeable linear form. We implement our method on supervised fine-tuning, reinforcement learning, and speculative decoding. The results show that AFA-LoRA reduces the performance gap between LoRA and full-parameter training. This work enables a more powerful and practical paradigm of parameter-efficient adaptation.
OmniMoGen: Unifying Human Motion Generation via Learning from Interleaved Text-Motion Instructions
Dec 22, 2025Large language models (LLMs) have unified diverse linguistic tasks within a single framework, yet such unification remains unexplored in human motion generation. Existing methods are confined to isolated tasks, limiting flexibility for free-form and omni-objective generation. To address this, we propose OmniMoGen, a unified framework that enables versatile motion generation through interleaved text-motion instructions. Built upon a concise RVQ-VAE and transformer architecture, OmniMoGen supports end-to-end instruction-driven motion generation. We construct X2Mo, a large-scale dataset of over 137K interleaved text-motion instructions, and introduce AnyContext, a benchmark for evaluating interleaved motion generation. Experiments show that OmniMoGen achieves state-of-the-art performance on text-to-motion, motion editing, and AnyContext, exhibiting emerging capabilities such as compositional editing, self-reflective generation, and knowledge-informed generation. These results mark a step toward the next intelligent motion generation. Project Page: https://OmniMoGen.github.io/.
Exploring Landscapes for Better Minima along Valleys
Oct 31, 2025Finding lower and better-generalizing minima is crucial for deep learning. However, most existing optimizers stop searching the parameter space once they reach a local minimum. Given the complex geometric properties of the loss landscape, it is difficult to guarantee that such a point is the lowest or provides the best generalization. To address this, we propose an adaptor "E" for gradient-based optimizers. The adapted optimizer tends to continue exploring along landscape valleys (areas with low and nearly identical losses) in order to search for potentially better local minima even after reaching a local minimum. This approach increases the likelihood of finding a lower and flatter local minimum, which is often associated with better generalization. We also provide a proof of convergence for the adapted optimizers in both convex and non-convex scenarios for completeness. Finally, we demonstrate their effectiveness in an important but notoriously difficult training scenario, large-batch training, where Lamb is the benchmark optimizer. Our testing results show that the adapted Lamb, ALTO, increases the test accuracy (generalization) of the current state-of-the-art optimizer by an average of 2.5% across a variety of large-batch training tasks. This work potentially opens a new research direction in the design of optimization algorithms.
In-Loop Filtering Using Learned Look-Up Tables for Video Coding
Sep 11, 2025In-loop filtering (ILF) is a key technology in video coding standards to reduce artifacts and enhance visual quality. Recently, neural network-based ILF schemes have achieved remarkable coding gains, emerging as a powerful candidate for next-generation video coding standards. However, the use of deep neural networks (DNN) brings significant computational and time complexity or high demands for dedicated hardware, making it challenging for general use. To address this limitation, we study a practical ILF solution by adopting look-up tables (LUTs). After training a DNN with a restricted reference range for ILF, all possible inputs are traversed, and the output values of the DNN are cached into LUTs. During the coding process, the filtering process is performed by simply retrieving the filtered pixel through locating the input pixels and interpolating between the cached values, instead of relying on heavy inference computations. In this paper, we propose a universal LUT-based ILF framework, termed LUT-ILF++. First, we introduce the cooperation of multiple kinds of filtering LUTs and propose a series of customized indexing mechanisms to enable better filtering reference perception with limited storage consumption. Second, we propose the cross-component indexing mechanism to enable the filtering of different color components jointly. Third, in order to make our solution practical for coding uses, we propose the LUT compaction scheme to enable the LUT pruning, achieving a lower storage cost of the entire solution. The proposed framework is implemented in the VVC reference software. Experimental results show that the proposed framework achieves on average 0.82%/2.97%/1.63% and 0.85%/4.11%/2.06% bitrate reduction for common test sequences, under the AI and RA configurations, respectively. Compared to DNN-based solutions, our proposed solution has much lower time complexity and storage cost.
Any-Step Density Ratio Estimation via Interval-Annealed Secant Alignment
Sep 05, 2025
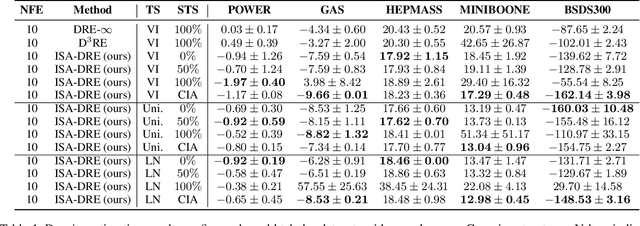
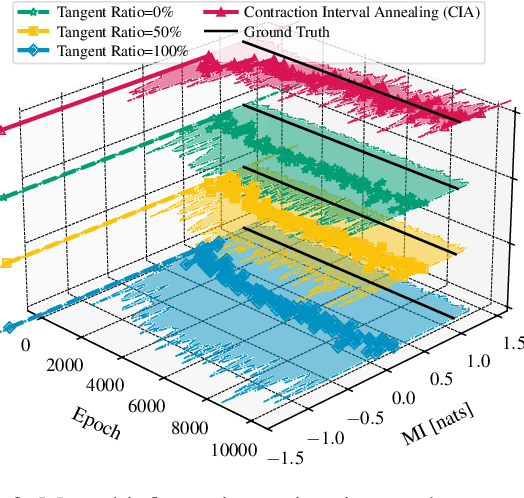
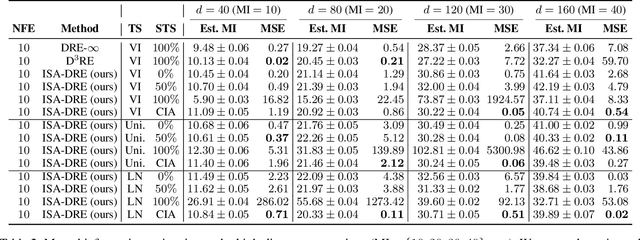
Estimating density ratios is a fundamental problem in machine learning, but existing methods often trade off accuracy for efficiency. We propose \textit{Interval-annealed Secant Alignment Density Ratio Estimation (ISA-DRE)}, a framework that enables accurate, any-step estimation without numerical integration. Instead of modeling infinitesimal tangents as in prior methods, ISA-DRE learns a global secant function, defined as the expectation of all tangents over an interval, with provably lower variance, making it more suitable for neural approximation. This is made possible by the \emph{Secant Alignment Identity}, a self-consistency condition that formally connects the secant with its underlying tangent representations. To mitigate instability during early training, we introduce \emph{Contraction Interval Annealing}, a curriculum strategy that gradually expands the alignment interval during training. This process induces a contraction mapping, which improves convergence and training stability. Empirically, ISA-DRE achieves competitive accuracy with significantly fewer function evaluations compared to prior methods, resulting in much faster inference and making it well suited for real-time and interactive applications.