 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImplicit Variational Rejection Sampling
Jun 12, 2026Variational Inference (VI) is a fundamental inference technique in Bayesian machine learning for approximating complex posterior distributions. Traditional VI often relies on the mean-field factorization, which can inadequately capture true posterior complexity. Recent advancements have leveraged neural networks to model implicit distributions, offering increased flexibility. However, the practical constraints of neural network architectures still produces inaccuracies. In this paper, we propose a method called Implicit Variational Rejection Sampling (IVRS), which integrates implicit distributions with rejection sampling to improve the posterior approximation. Our method uses neural networks to construct implicit proposal distributions, and rejection sampling with a discriminator network that estimates the density ratio between the implicit proposal and the true posterior for refining the approximation. Towards this end, we introduce the Implicit Resampling Evidence Lower Bound (IR-ELBO) as a metric to characterize the resampled distribution's quality and derive a tighter variational lower bound. Experimental results demonstrate that our method outperforms traditional variational inference techniques.
Mitigating the Contractivity Trap in Diffusion ODEs via Stein Stabilization
Jun 05, 2026A fundamental tension exists in the large-step inference of diffusion models via their deterministic probability flow ordinary differential equation (PF-ODE) trajectories, which we identify as the contractivity trap: efficient inference favors large step sizes, while aggressive steps and highly expressive denoisers can undermine contraction-based stability certificates for error suppression. To address this, we propose SteinDiff, a step-wise inference-time stabilization framework that employs Stein-derived corrections without requiring reference samples. Specifically, SteinDiff introduces a geometry-aware residual correction mechanism that regularizes large-step solver updates without retraining. To this end, we derive a closed-form Stein correction coefficient for step-wise solver adjustment, enabling reference-free adaptation to local data geometry. We further establish a score-controlled perturbation bound under distributional shifts and provide a complementary Stein perspective on EDM-style parameterizations. Extensive experiments demonstrate that SteinDiff mitigates severe artifacts and improves generative quality across large-step inference settings.
Don't Forget Its Variance! The Minimum Path Variance Principle for Accurate and Stable Score-Based Density Ratio Estimation
Jan 31, 2026Score-based methods have emerged as a powerful framework for density ratio estimation (DRE), but they face an important paradox in that, while theoretically path-independent, their practical performance depends critically on the chosen path schedule. We resolve this issue by proving that tractable training objectives differ from the ideal, ground-truth objective by a crucial, overlooked term: the path variance of the time score. To address this, we propose MinPV (\textbf{Min}imum \textbf{P}ath \textbf{V}ariance) Principle, which introduces a principled heuristic to minimize the overlooked path variance. Our key contribution is the derivation of a closed-form expression for the variance, turning an intractable problem into a tractable optimization. By parameterizing the path with a flexible Kumaraswamy Mixture Model, our method learns a data-adaptive, low-variance path without heuristic selection. This principled optimization of the complete objective yields more accurate and stable estimators, establishing new state-of-the-art results on challenging benchmarks.
Any-Step Density Ratio Estimation via Interval-Annealed Secant Alignment
Sep 05, 2025
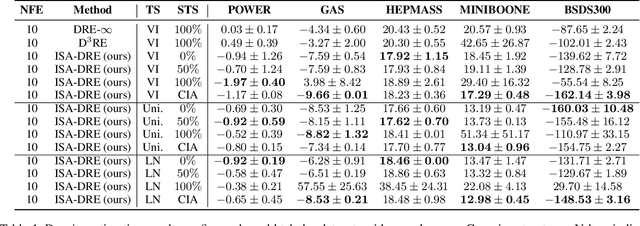
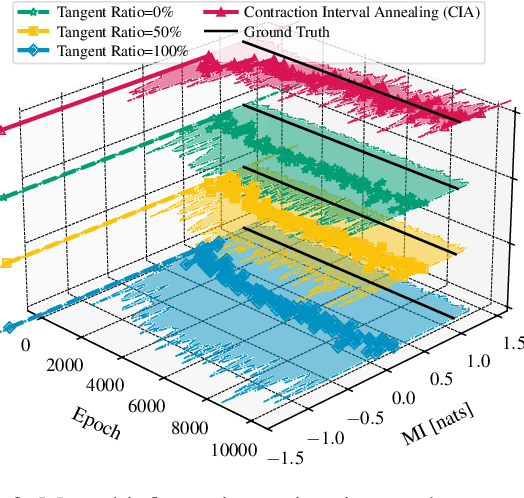
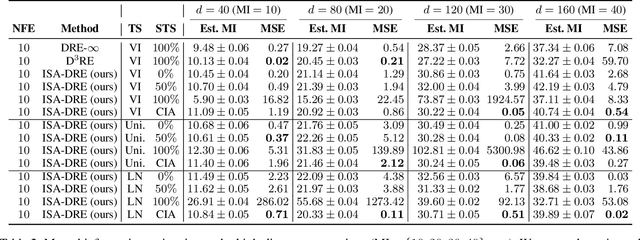
Estimating density ratios is a fundamental problem in machine learning, but existing methods often trade off accuracy for efficiency. We propose \textit{Interval-annealed Secant Alignment Density Ratio Estimation (ISA-DRE)}, a framework that enables accurate, any-step estimation without numerical integration. Instead of modeling infinitesimal tangents as in prior methods, ISA-DRE learns a global secant function, defined as the expectation of all tangents over an interval, with provably lower variance, making it more suitable for neural approximation. This is made possible by the \emph{Secant Alignment Identity}, a self-consistency condition that formally connects the secant with its underlying tangent representations. To mitigate instability during early training, we introduce \emph{Contraction Interval Annealing}, a curriculum strategy that gradually expands the alignment interval during training. This process induces a contraction mapping, which improves convergence and training stability. Empirically, ISA-DRE achieves competitive accuracy with significantly fewer function evaluations compared to prior methods, resulting in much faster inference and making it well suited for real-time and interactive applications.
Dequantified Diffusion Schrödinger Bridge for Density Ratio Estimation
May 08, 2025Density ratio estimation is fundamental to tasks involving $f$-divergences, yet existing methods often fail under significantly different distributions or inadequately overlap supports, suffering from the \textit{density-chasm} and the \textit{support-chasm} problems. Additionally, prior approaches yield divergent time scores near boundaries, leading to instability. We propose $\text{D}^3\text{RE}$, a unified framework for robust and efficient density ratio estimation. It introduces the Dequantified Diffusion-Bridge Interpolant (DDBI), which expands support coverage and stabilizes time scores via diffusion bridges and Gaussian dequantization. Building on DDBI, the Dequantified Schr\"odinger-Bridge Interpolant (DSBI) incorporates optimal transport to solve the Schr\"odinger bridge problem, enhancing accuracy and efficiency. Our method offers uniform approximation and bounded time scores in theory, and outperforms baselines empirically in mutual information and density estimation tasks.
Flexible Bayesian Last Layer Models Using Implicit Priors and Diffusion Posterior Sampling
Aug 07, 2024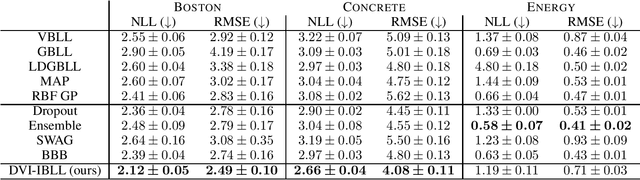
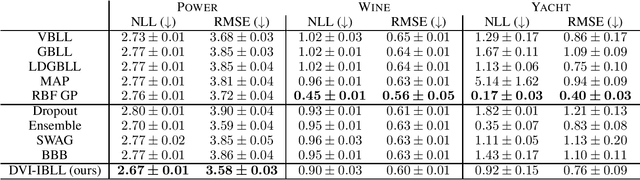
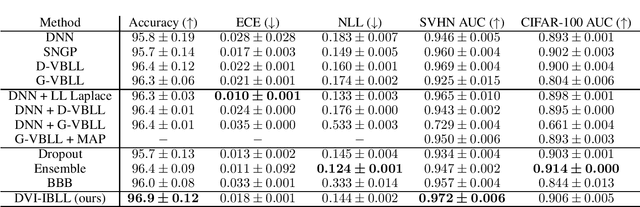
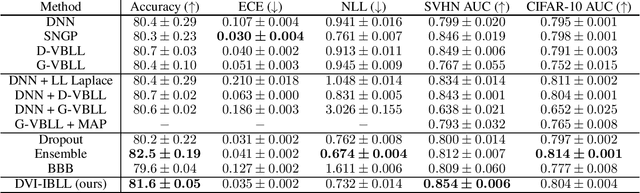
Bayesian Last Layer (BLL) models focus solely on uncertainty in the output layer of neural networks, demonstrating comparable performance to more complex Bayesian models. However, the use of Gaussian priors for last layer weights in Bayesian Last Layer (BLL) models limits their expressive capacity when faced with non-Gaussian, outlier-rich, or high-dimensional datasets. To address this shortfall, we introduce a novel approach that combines diffusion techniques and implicit priors for variational learning of Bayesian last layer weights. This method leverages implicit distributions for modeling weight priors in BLL, coupled with diffusion samplers for approximating true posterior predictions, thereby establishing a comprehensive Bayesian prior and posterior estimation strategy. By delivering an explicit and computationally efficient variational lower bound, our method aims to augment the expressive abilities of BLL models, enhancing model accuracy, calibration, and out-of-distribution detection proficiency. Through detailed exploration and experimental validation, We showcase the method's potential for improving predictive accuracy and uncertainty quantification while ensuring computational efficiency.
Entropy-Informed Weighting Channel Normalizing Flow
Jul 06, 2024
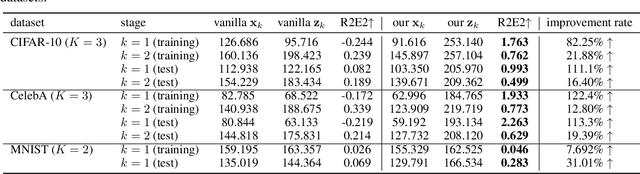
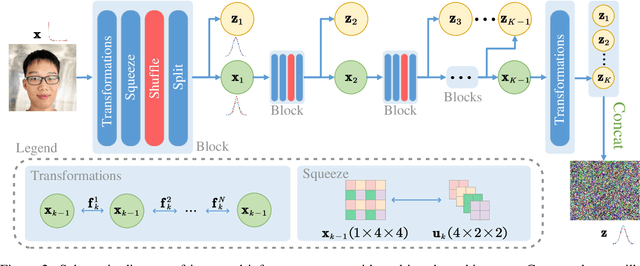
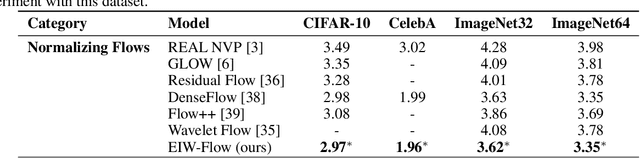
Normalizing Flows (NFs) have gained popularity among deep generative models due to their ability to provide exact likelihood estimation and efficient sampling. However, a crucial limitation of NFs is their substantial memory requirements, arising from maintaining the dimension of the latent space equal to that of the input space. Multi-scale architectures bypass this limitation by progressively reducing the dimension of latent variables while ensuring reversibility. Existing multi-scale architectures split the latent variables in a simple, static manner at the channel level, compromising NFs' expressive power. To address this issue, we propose a regularized and feature-dependent $\mathtt{Shuffle}$ operation and integrate it into vanilla multi-scale architecture. This operation heuristically generates channel-wise weights and adaptively shuffles latent variables before splitting them with these weights. We observe that such operation guides the variables to evolve in the direction of entropy increase, hence we refer to NFs with the $\mathtt{Shuffle}$ operation as \emph{Entropy-Informed Weighting Channel Normalizing Flow} (EIW-Flow). Experimental results indicate that the EIW-Flow achieves state-of-the-art density estimation results and comparable sample quality on CIFAR-10, CelebA and ImageNet datasets, with negligible additional computational overhead.
SciRE-Solver: Efficient Sampling of Diffusion Probabilistic Models by Score-integrand Solver with Recursive Derivative Estimation
Aug 16, 2023



Diffusion probabilistic models (DPMs) are a powerful class of generative models known for their ability to generate high-fidelity image samples. A major challenge in the implementation of DPMs is the slow sampling process. In this work, we bring a high-efficiency sampler for DPMs. Specifically, we propose a score-based exact solution paradigm for the diffusion ODEs corresponding to the sampling process of DPMs, which introduces a new perspective on developing numerical algorithms for solving diffusion ODEs. To achieve an efficient sampler, we propose a recursive derivative estimation (RDE) method to reduce the estimation error. With our proposed solution paradigm and RDE method, we propose the score-integrand solver with the convergence order guarantee as efficient solver (SciRE-Solver) for solving diffusion ODEs. The SciRE-Solver attains state-of-the-art (SOTA) sampling performance with a limited number of score function evaluations (NFE) on both discrete-time and continuous-time DPMs in comparison to existing training-free sampling algorithms. Such as, we achieve $3.48$ FID with $12$ NFE and $2.42$ FID with $20$ NFE for continuous-time DPMs on CIFAR10, respectively. Different from other samplers, SciRE-Solver has the promising potential to surpass the FIDs achieved in the original papers of some pre-trained models with a small NFEs. For example, we reach SOTA value of $2.40$ FID with $100$ NFE for continuous-time DPM and of $3.15$ FID with $84$ NFE for discrete-time DPM on CIFAR-10, as well as of $2.17$ ($2.02$) FID with $18$ ($50$) NFE for discrete-time DPM on CelebA 64$\times$64.