 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeveScale-FSDP: Flexible and High-Performance FSDP at Scale
Feb 25, 2026Fully Sharded Data Parallel (FSDP), also known as ZeRO, is widely used for training large-scale models, featuring its flexibility and minimal intrusion on model code. However, current FSDP systems struggle with structure-aware training methods (e.g., block-wise quantized training) and with non-element-wise optimizers (e.g., Shampoo and Muon) used in cutting-edge models (e.g., Gemini, Kimi K2). FSDP's fixed element- or row-wise sharding formats conflict with the block-structured computations. In addition, today's implementations fall short in communication and memory efficiency, limiting scaling to tens of thousands of GPUs. We introduce veScale-FSDP, a redesigned FSDP system that couples a flexible sharding format, RaggedShard, with a structure-aware planning algorithm to deliver both flexibility and performance at scale. veScale-FSDP natively supports efficient data placement required by FSDP, empowering block-wise quantization and non-element-wise optimizers. As a result, veScale-FSDP achieves 5~66% higher throughput and 16~30% lower memory usage than existing FSDP systems, while scaling efficiently to tens of thousands of GPUs.
Don't Forget Its Variance! The Minimum Path Variance Principle for Accurate and Stable Score-Based Density Ratio Estimation
Jan 31, 2026Score-based methods have emerged as a powerful framework for density ratio estimation (DRE), but they face an important paradox in that, while theoretically path-independent, their practical performance depends critically on the chosen path schedule. We resolve this issue by proving that tractable training objectives differ from the ideal, ground-truth objective by a crucial, overlooked term: the path variance of the time score. To address this, we propose MinPV (\textbf{Min}imum \textbf{P}ath \textbf{V}ariance) Principle, which introduces a principled heuristic to minimize the overlooked path variance. Our key contribution is the derivation of a closed-form expression for the variance, turning an intractable problem into a tractable optimization. By parameterizing the path with a flexible Kumaraswamy Mixture Model, our method learns a data-adaptive, low-variance path without heuristic selection. This principled optimization of the complete objective yields more accurate and stable estimators, establishing new state-of-the-art results on challenging benchmarks.
Virtual Width Networks
Nov 17, 2025



We introduce Virtual Width Networks (VWN), a framework that delivers the benefits of wider representations without incurring the quadratic cost of increasing the hidden size. VWN decouples representational width from backbone width, expanding the embedding space while keeping backbone compute nearly constant. In our large-scale experiment, an 8-times expansion accelerates optimization by over 2 times for next-token and 3 times for next-2-token prediction. The advantage amplifies over training as both the loss gap grows and the convergence-speedup ratio increases, showing that VWN is not only token-efficient but also increasingly effective with scale. Moreover, we identify an approximately log-linear scaling relation between virtual width and loss reduction, offering an initial empirical basis and motivation for exploring virtual-width scaling as a new dimension of large-model efficiency.
Any-Step Density Ratio Estimation via Interval-Annealed Secant Alignment
Sep 05, 2025
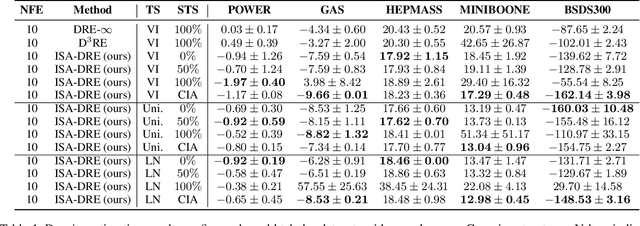
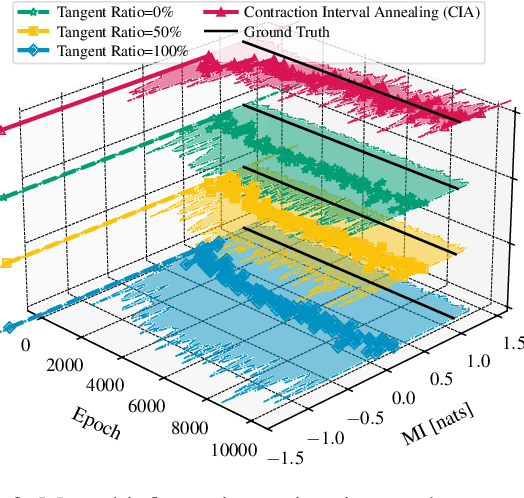
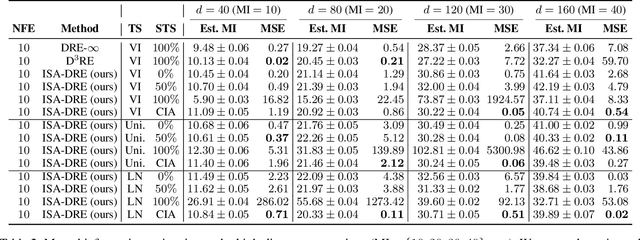
Estimating density ratios is a fundamental problem in machine learning, but existing methods often trade off accuracy for efficiency. We propose \textit{Interval-annealed Secant Alignment Density Ratio Estimation (ISA-DRE)}, a framework that enables accurate, any-step estimation without numerical integration. Instead of modeling infinitesimal tangents as in prior methods, ISA-DRE learns a global secant function, defined as the expectation of all tangents over an interval, with provably lower variance, making it more suitable for neural approximation. This is made possible by the \emph{Secant Alignment Identity}, a self-consistency condition that formally connects the secant with its underlying tangent representations. To mitigate instability during early training, we introduce \emph{Contraction Interval Annealing}, a curriculum strategy that gradually expands the alignment interval during training. This process induces a contraction mapping, which improves convergence and training stability. Empirically, ISA-DRE achieves competitive accuracy with significantly fewer function evaluations compared to prior methods, resulting in much faster inference and making it well suited for real-time and interactive applications.
Truncated Proximal Policy Optimization
Jun 18, 2025



Recently, test-time scaling Large Language Models (LLMs) have demonstrated exceptional reasoning capabilities across scientific and professional tasks by generating long chains-of-thought (CoT). As a crucial component for developing these reasoning models, reinforcement learning (RL), exemplified by Proximal Policy Optimization (PPO) and its variants, allows models to learn through trial and error. However, PPO can be time-consuming due to its inherent on-policy nature, which is further exacerbated by increasing response lengths. In this work, we propose Truncated Proximal Policy Optimization (T-PPO), a novel extension to PPO that improves training efficiency by streamlining policy update and length-restricted response generation. T-PPO mitigates the issue of low hardware utilization, an inherent drawback of fully synchronized long-generation procedures, where resources often sit idle during the waiting periods for complete rollouts. Our contributions are two-folds. First, we propose Extended Generalized Advantage Estimation (EGAE) for advantage estimation derived from incomplete responses while maintaining the integrity of policy learning. Second, we devise a computationally optimized mechanism that allows for the independent optimization of the policy and value models. By selectively filtering prompt and truncated tokens, this mechanism reduces redundant computations and accelerates the training process without sacrificing convergence performance. We demonstrate the effectiveness and efficacy of T-PPO on AIME 2024 with a 32B base model. The experimental results show that T-PPO improves the training efficiency of reasoning LLMs by up to 2.5x and outperforms its existing competitors.
VAPO: Efficient and Reliable Reinforcement Learning for Advanced Reasoning Tasks
Apr 08, 2025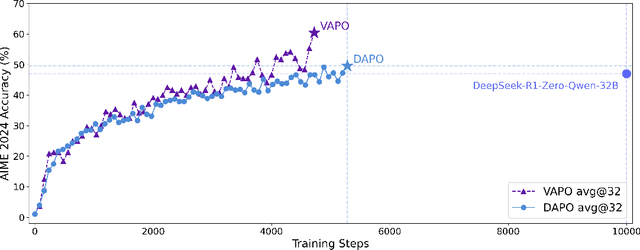

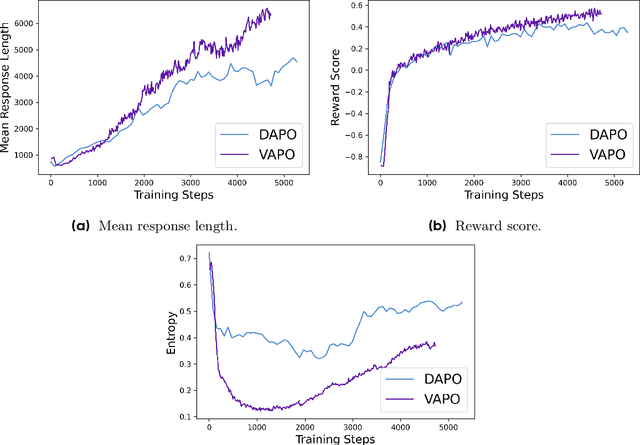
We present VAPO, Value-based Augmented Proximal Policy Optimization framework for reasoning models., a novel framework tailored for reasoning models within the value-based paradigm. Benchmarked the AIME 2024 dataset, VAPO, built on the Qwen 32B pre-trained model, attains a state-of-the-art score of $\mathbf{60.4}$. In direct comparison under identical experimental settings, VAPO outperforms the previously reported results of DeepSeek-R1-Zero-Qwen-32B and DAPO by more than 10 points. The training process of VAPO stands out for its stability and efficiency. It reaches state-of-the-art performance within a mere 5,000 steps. Moreover, across multiple independent runs, no training crashes occur, underscoring its reliability. This research delves into long chain-of-thought (long-CoT) reasoning using a value-based reinforcement learning framework. We pinpoint three key challenges that plague value-based methods: value model bias, the presence of heterogeneous sequence lengths, and the sparsity of reward signals. Through systematic design, VAPO offers an integrated solution that effectively alleviates these challenges, enabling enhanced performance in long-CoT reasoning tasks.
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Mar 18, 2025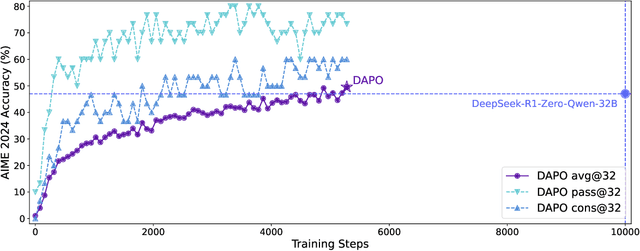

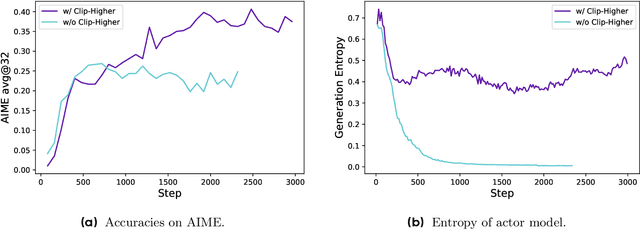

Inference scaling empowers LLMs with unprecedented reasoning ability, with reinforcement learning as the core technique to elicit complex reasoning. However, key technical details of state-of-the-art reasoning LLMs are concealed (such as in OpenAI o1 blog and DeepSeek R1 technical report), thus the community still struggles to reproduce their RL training results. We propose the $\textbf{D}$ecoupled Clip and $\textbf{D}$ynamic s$\textbf{A}$mpling $\textbf{P}$olicy $\textbf{O}$ptimization ($\textbf{DAPO}$) algorithm, and fully open-source a state-of-the-art large-scale RL system that achieves 50 points on AIME 2024 using Qwen2.5-32B base model. Unlike previous works that withhold training details, we introduce four key techniques of our algorithm that make large-scale LLM RL a success. In addition, we open-source our training code, which is built on the verl framework, along with a carefully curated and processed dataset. These components of our open-source system enhance reproducibility and support future research in large-scale LLM RL.
Natural Language Fine-Tuning
Dec 29, 2024Large language model fine-tuning techniques typically depend on extensive labeled data, external guidance, and feedback, such as human alignment, scalar rewards, and demonstration. However, in practical application, the scarcity of specific knowledge poses unprecedented challenges to existing fine-tuning techniques. In this paper, focusing on fine-tuning tasks in specific domains with limited data, we introduce Natural Language Fine-Tuning (NLFT), which utilizes natural language for fine-tuning for the first time. By leveraging the strong language comprehension capability of the target LM, NLFT attaches the guidance of natural language to the token-level outputs. Then, saliency tokens are identified with calculated probabilities. Since linguistic information is effectively utilized in NLFT, our proposed method significantly reduces training costs. It markedly enhances training efficiency, comprehensively outperforming reinforcement fine-tuning algorithms in accuracy, time-saving, and resource conservation. Additionally, on the macro level, NLFT can be viewed as a token-level fine-grained optimization of SFT, thereby efficiently replacing the SFT process without the need for warm-up (as opposed to ReFT requiring multiple rounds of warm-up with SFT). Compared to SFT, NLFT does not increase the algorithmic complexity, maintaining O(n). Extensive experiments on the GSM8K dataset demonstrate that NLFT, with only 50 data instances, achieves an accuracy increase that exceeds SFT by 219%. Compared to ReFT, the time complexity and space complexity of NLFT are reduced by 78.27% and 92.24%, respectively. The superior technique of NLFT is paving the way for the deployment of various innovative LLM fine-tuning applications when resources are limited at network edges. Our code has been released at https://github.com/Julia-LiuJ/NLFT.
Fully Bayesian Differential Gaussian Processes through Stochastic Differential Equations
Aug 12, 2024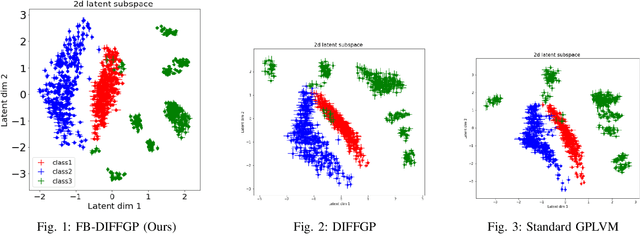
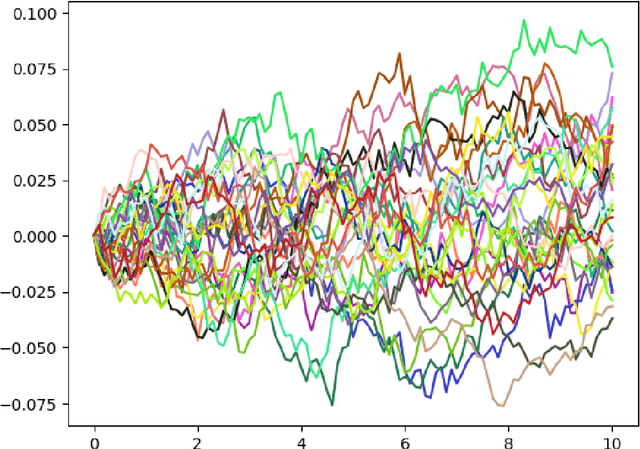
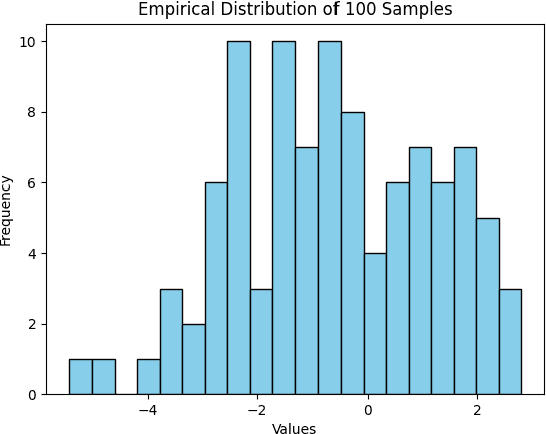

Traditional deep Gaussian processes model the data evolution using a discrete hierarchy, whereas differential Gaussian processes (DIFFGPs) represent the evolution as an infinitely deep Gaussian process. However, prior DIFFGP methods often overlook the uncertainty of kernel hyperparameters and assume them to be fixed and time-invariant, failing to leverage the unique synergy between continuous-time models and approximate inference. In this work, we propose a fully Bayesian approach that treats the kernel hyperparameters as random variables and constructs coupled stochastic differential equations (SDEs) to learn their posterior distribution and that of inducing points. By incorporating estimation uncertainty on hyperparameters, our method enhances the model's flexibility and adaptability to complex dynamics. Additionally, our approach provides a time-varying, comprehensive, and realistic posterior approximation through coupling variables using SDE methods. Experimental results demonstrate the advantages of our method over traditional approaches, showcasing its superior performance in terms of flexibility, accuracy, and other metrics. Our work opens up exciting research avenues for advancing Bayesian inference and offers a powerful modeling tool for continuous-time Gaussian processes.
Flexible Bayesian Last Layer Models Using Implicit Priors and Diffusion Posterior Sampling
Aug 07, 2024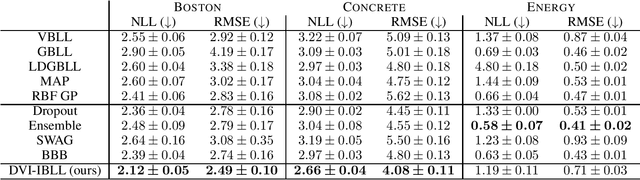
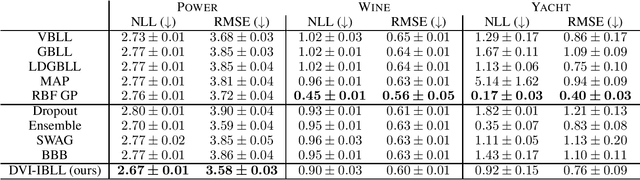
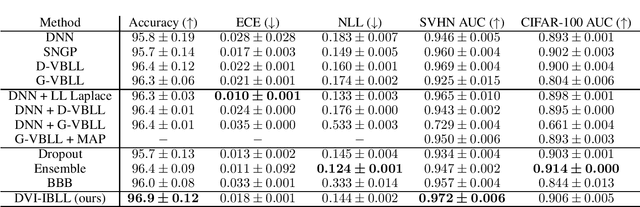
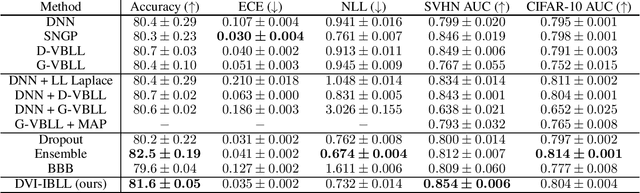
Bayesian Last Layer (BLL) models focus solely on uncertainty in the output layer of neural networks, demonstrating comparable performance to more complex Bayesian models. However, the use of Gaussian priors for last layer weights in Bayesian Last Layer (BLL) models limits their expressive capacity when faced with non-Gaussian, outlier-rich, or high-dimensional datasets. To address this shortfall, we introduce a novel approach that combines diffusion techniques and implicit priors for variational learning of Bayesian last layer weights. This method leverages implicit distributions for modeling weight priors in BLL, coupled with diffusion samplers for approximating true posterior predictions, thereby establishing a comprehensive Bayesian prior and posterior estimation strategy. By delivering an explicit and computationally efficient variational lower bound, our method aims to augment the expressive abilities of BLL models, enhancing model accuracy, calibration, and out-of-distribution detection proficiency. Through detailed exploration and experimental validation, We showcase the method's potential for improving predictive accuracy and uncertainty quantification while ensuring computational efficiency.