 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMSCCL++: Rethinking GPU Communication Abstractions for Cutting-edge AI Applications
Apr 11, 2025

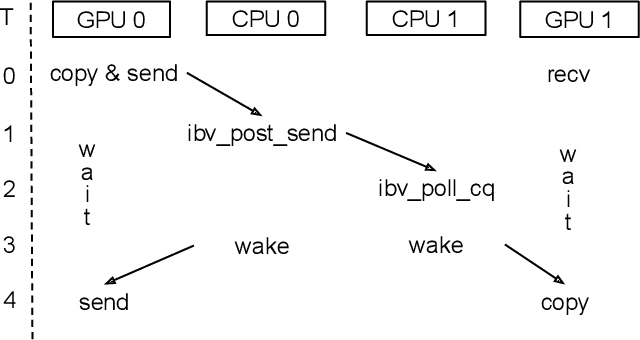
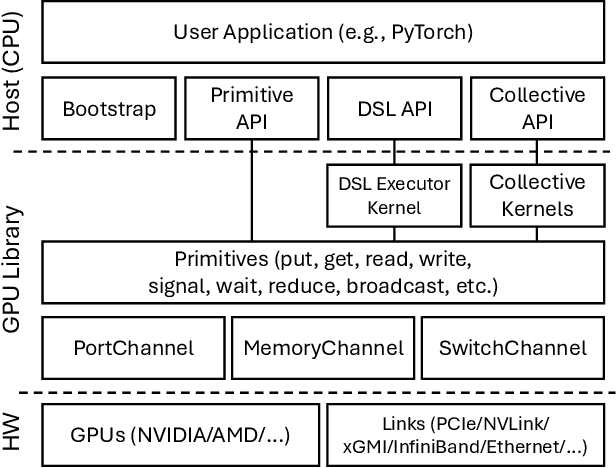
Modern cutting-edge AI applications are being developed over fast-evolving, heterogeneous, nascent hardware devices. This requires frequent reworking of the AI software stack to adopt bottom-up changes from new hardware, which takes time for general-purpose software libraries. Consequently, real applications often develop custom software stacks optimized for their specific workloads and hardware. Custom stacks help quick development and optimization, but incur a lot of redundant efforts across applications in writing non-portable code. This paper discusses an alternative communication library interface for AI applications that offers both portability and performance by reducing redundant efforts while maintaining flexibility for customization. We present MSCCL++, a novel abstraction of GPU communication based on separation of concerns: (1) a primitive interface provides a minimal hardware abstraction as a common ground for software and hardware developers to write custom communication, and (2) higher-level portable interfaces and specialized implementations enable optimization for different hardware environments. This approach makes the primitive interface reusable across applications while enabling highly flexible optimization. Compared to state-of-the-art baselines (NCCL, RCCL, and MSCCL), MSCCL++ achieves speedups of up to 3.8$\times$ for collective communication and up to 15\% for real-world AI inference workloads. MSCCL++ is in production of multiple AI services provided by Microsoft Azure, and is also adopted by RCCL, the GPU collective communication library maintained by AMD. MSCCL++ is open-source and available at https://github.com/microsoft/mscclpp.
ForestColl: Efficient Collective Communications on Heterogeneous Network Fabrics
Feb 09, 2024



As modern DNN models grow ever larger, collective communications between the accelerators (allreduce, etc.) emerge as a significant performance bottleneck. Designing efficient communication schedules is challenging given today's highly diverse and heterogeneous network fabrics. In this paper, we present ForestColl, a tool that generates efficient schedules for any network topology. ForestColl constructs broadcast/aggregation spanning trees as the communication schedule, achieving theoretically minimum network congestion. Its schedule generation runs in strongly polynomial time and is highly scalable. ForestColl supports any network fabrics, including both switching fabrics and direct connections, as well as any network graph structure. We evaluated ForestColl on multi-cluster AMD MI250 and NVIDIA A100 platforms. ForestColl's schedules achieved up to 52\% higher performance compared to the vendors' own optimized communication libraries, RCCL and NCCL. ForestColl also outperforms other state-of-the-art schedule generation techniques with both up to 61\% more efficient generated schedules and orders of magnitude faster schedule generation speed.
Tessel: Boosting Distributed Execution of Large DNN Models via Flexible Schedule Search
Nov 26, 2023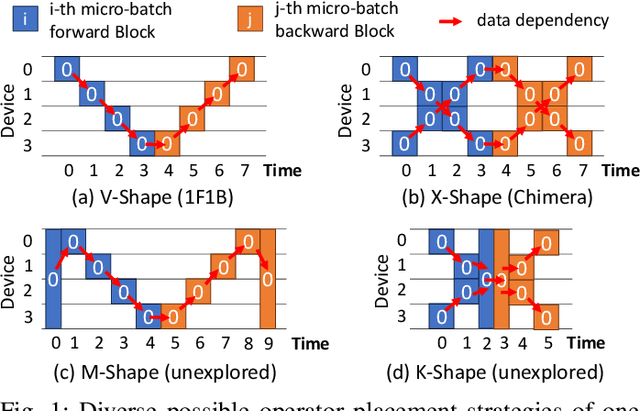
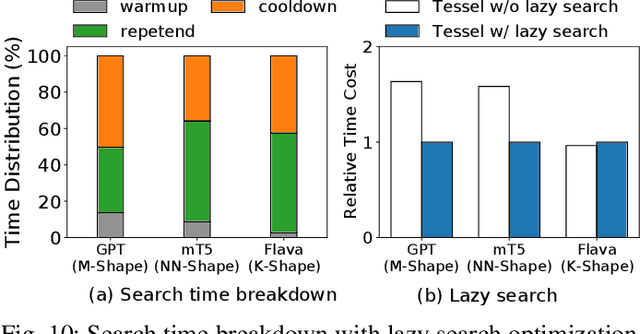
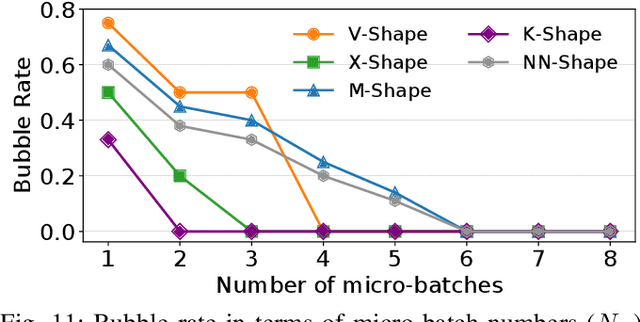
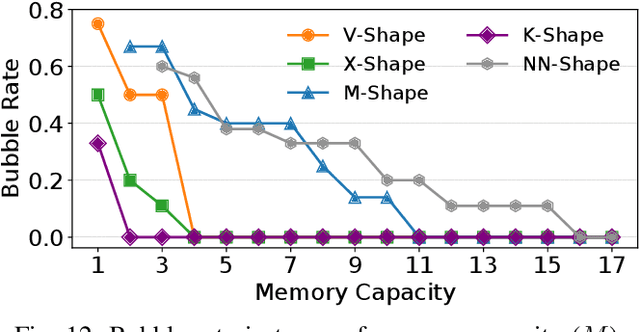
Increasingly complex and diverse deep neural network (DNN) models necessitate distributing the execution across multiple devices for training and inference tasks, and also require carefully planned schedules for performance. However, existing practices often rely on predefined schedules that may not fully exploit the benefits of emerging diverse model-aware operator placement strategies. Handcrafting high-efficiency schedules can be challenging due to the large and varying schedule space. This paper presents Tessel, an automated system that searches for efficient schedules for distributed DNN training and inference for diverse operator placement strategies. To reduce search costs, Tessel leverages the insight that the most efficient schedules often exhibit repetitive pattern (repetend) across different data inputs. This leads to a two-phase approach: repetend construction and schedule completion. By exploring schedules for various operator placement strategies, Tessel significantly improves both training and inference performance. Experiments with representative DNN models demonstrate that Tessel achieves up to 5.5x training performance speedup and up to 38% inference latency reduction.
Look-Up mAI GeMM: Increasing AI GeMMs Performance by Nearly 2.5x via msGeMM
Oct 09, 2023


AI models are increasing in size and recent advancement in the community has shown that unlike HPC applications where double precision datatype are required, lower-precision datatypes such as fp8 or int4 are sufficient to bring the same model quality both for training and inference. Following these trends, GPU vendors such as NVIDIA and AMD have added hardware support for fp16, fp8 and int8 GeMM operations with an exceptional performance via Tensor Cores. However, this paper proposes a new algorithm called msGeMM which shows that AI models with low-precision datatypes can run with ~2.5x fewer multiplication and add instructions. Efficient implementation of this algorithm requires special CUDA cores with the ability to add elements from a small look-up table at the rate of Tensor Cores.
SuperScaler: Supporting Flexible DNN Parallelization via a Unified Abstraction
Jan 21, 2023



With the growing model size, deep neural networks (DNN) are increasingly trained over massive GPU accelerators, which demands a proper parallelization plan that transforms a DNN model into fine-grained tasks and then schedules them to GPUs for execution. Due to the large search space, the contemporary parallelization plan generators often rely on empirical rules that couple transformation and scheduling, and fall short in exploring more flexible schedules that yield better memory usage and compute efficiency. This tension can be exacerbated by the emerging models with increasing complexity in their structure and model size. SuperScaler is a system that facilitates the design and generation of highly flexible parallelization plans. It formulates the plan design and generation into three sequential phases explicitly: model transformation, space-time scheduling, and data dependency preserving. Such a principled approach decouples multiple seemingly intertwined factors and enables the composition of highly flexible parallelization plans. As a result, SuperScaler can not only generate empirical parallelization plans, but also construct new plans that achieve up to 3.5X speedup compared to state-of-the-art solutions like DeepSpeed, Megatron and Alpa, for emerging DNN models like Swin-Transformer and AlphaFold2, as well as well-optimized models like GPT-3.
Synthesizing Collective Communication Algorithms for Heterogeneous Networks with TACCL
Nov 15, 2021
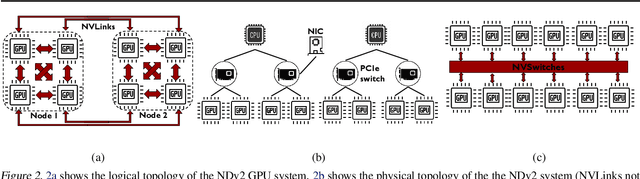
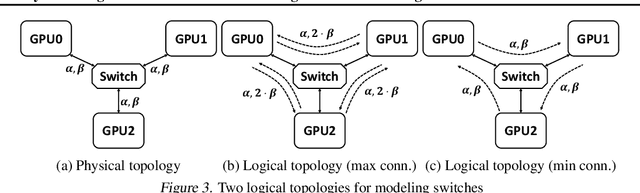
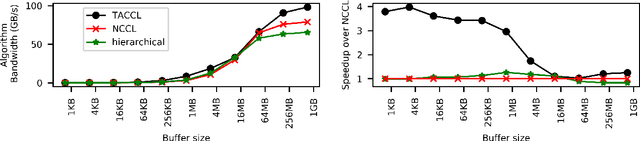
Large ML models and datasets have necessitated the use of multi-GPU systems for distributed model training. To harness the power offered by multi-GPU systems, it is critical to eliminate bottlenecks in inter-GPU communication - a problem made challenging by the heterogeneous nature of interconnects. In this work, we present TACCL, a synthesizer for collective communication primitives for large-scale multi-GPU systems. TACCL encodes a profiled topology and input size into a synthesis problem to generate optimized communication algorithms. TACCL is built on top of the standard NVIDIA Collective Communication Library (NCCL), allowing it to be a drop-in replacement for GPU communication in frameworks like PyTorch with minimal changes. TACCL generates algorithms for communication primitives like Allgather, Alltoall, and Allreduce that are up to $3\times$ faster than NCCL. Using TACCL's algorithms speeds up the end-to-end training of an internal mixture of experts model by $17\%$. By decomposing the optimization problem into parts and leveraging the symmetry in multi-GPU topologies, TACCL synthesizes collectives for up to 80-GPUs in less than 3 minutes, at least two orders of magnitude faster than other synthesis-based state-of-the-art collective communication libraries.
Total Least Squares for Optimal Pose Estimation
Jun 22, 2021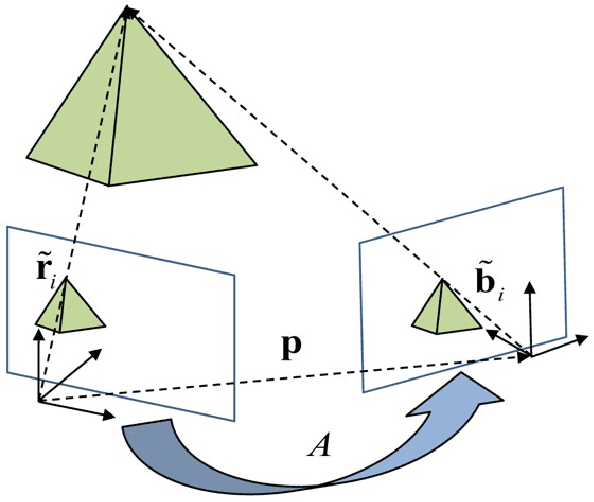
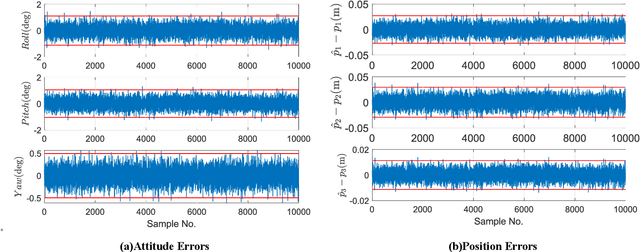
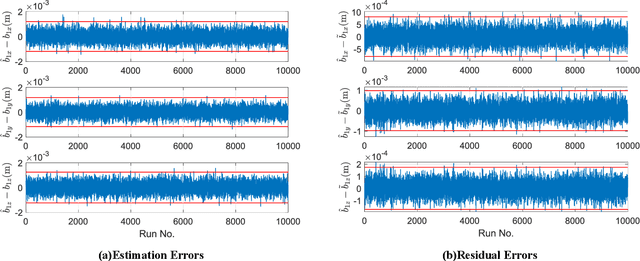
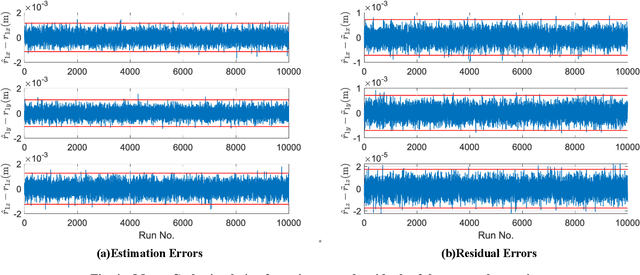
This work provides a theoretical framework for the pose estimation problem using total least squares for vector observations from landmark features. First, the optimization framework is formulated for the pose estimation problem with observation vectors extracted from point cloud features. Then, error-covariance expressions are derived. The attitude and position solutions obtained via the derived optimization framework are proven to reach the bounds defined by the Cram\'er-Rao lower bound under the small angle approximation of attitude errors. The measurement data for the simulation of this problem is provided through a series of vector observation scans, and a fully populated observation noise-covariance matrix is assumed as the weight in the cost function to cover for the most general case of the sensor uncertainty. Here, previous derivations are expanded for the pose estimation problem to include more generic cases of correlations in the errors than previously cases involving an isotropic noise assumption. The proposed solution is simulated in a Monte-Carlo framework with 10,000 samples to validate the error-covariance analysis.
CoCoNet: Co-Optimizing Computation and Communication for Distributed Machine Learning
May 13, 2021
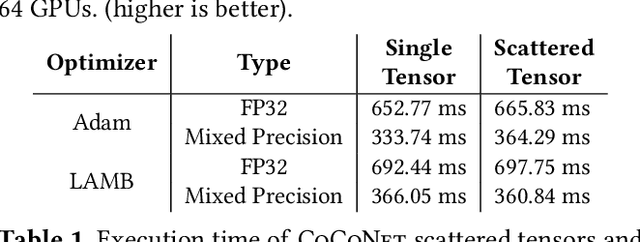

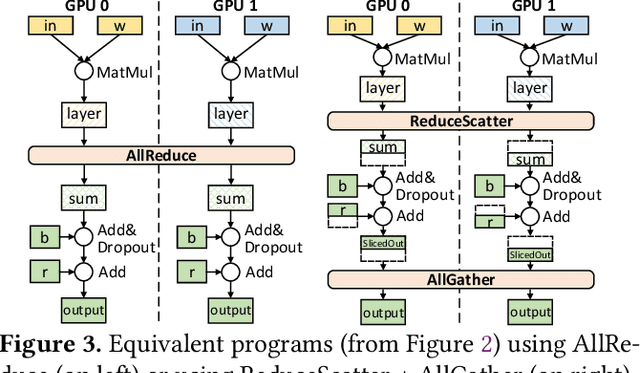
Modern deep learning workloads run on distributed hardware and are difficult to optimize -- data, model, and pipeline parallelism require a developer to thoughtfully restructure their workload around optimized computation and communication kernels in libraries such as cuBLAS and NCCL. The logical separation between computation and communication leaves performance on the table with missed optimization opportunities across abstraction boundaries. To explore these opportunities, this paper presents CoCoNet, which consists of a compute language to express programs with both computation and communication, a scheduling language to apply transformations on such programs, and a compiler to generate high performance kernels. Providing both computation and communication as first class constructs enables new optimizations, such as overlapping or fusion of communication with computation. CoCoNet allowed us to optimize several data, model and pipeline parallel workloads in existing deep learning systems with very few lines of code. We show significant improvements after integrating novel CoCoNet generated kernels.
Scaling Distributed Training with Adaptive Summation
Jun 04, 2020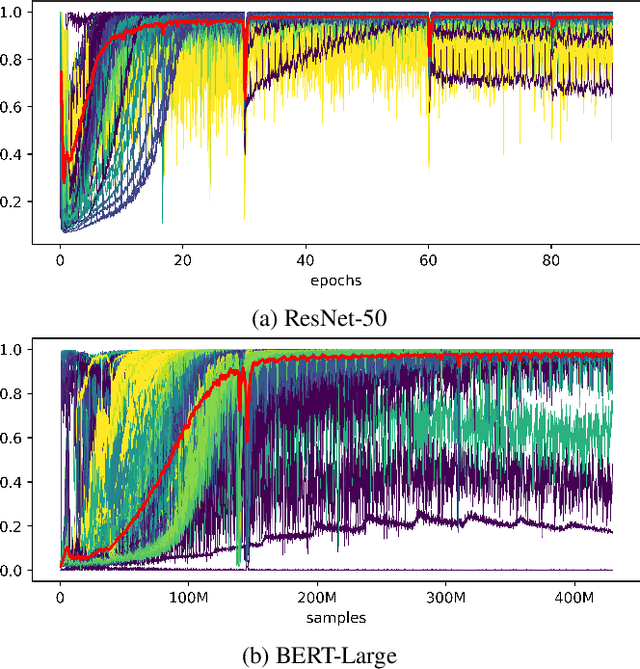
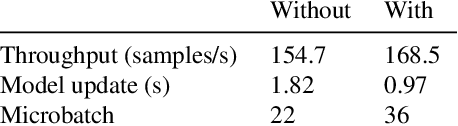
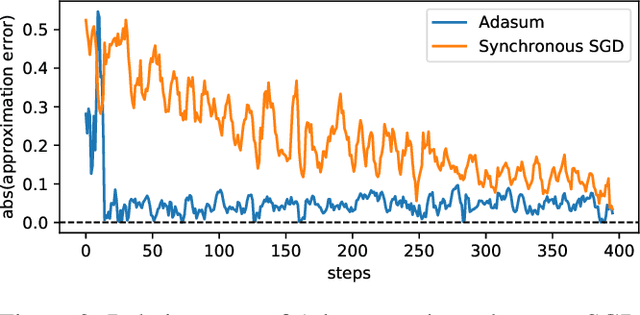

Stochastic gradient descent (SGD) is an inherently sequential training algorithm--computing the gradient at batch $i$ depends on the model parameters learned from batch $i-1$. Prior approaches that break this dependence do not honor them (e.g., sum the gradients for each batch, which is not what sequential SGD would do) and thus potentially suffer from poor convergence. This paper introduces a novel method to combine gradients called Adasum (for adaptive sum) that converges faster than prior work. Adasum is easy to implement, almost as efficient as simply summing gradients, and is integrated into the open-source toolkit Horovod. This paper first provides a formal justification for Adasum and then empirically demonstrates Adasum is more accurate than prior gradient accumulation methods. It then introduces a series of case-studies to show Adasum works with multiple frameworks, (TensorFlow and PyTorch), scales multiple optimizers (Momentum-SGD, Adam, and LAMB) to larger batch-sizes while still giving good downstream accuracy. Finally, it proves that Adasum converges. To summarize, Adasum scales Momentum-SGD on the MLPerf Resnet50 benchmark to 64K examples before communication (no MLPerf v0.5 entry converged with more than 16K), the Adam optimizer to 64K examples before communication on BERT-LARGE (prior work showed Adam stopped scaling at 16K), and the LAMB optimizer to 128K before communication on BERT-LARGE (prior work used 64K), all while maintaining downstream accuracy metrics. Finally, if a user does not need to scale, we show LAMB with Adasum on BERT-LARGE converges in 30% fewer steps than the baseline.
Distributed Word2Vec using Graph Analytics Frameworks
Sep 08, 2019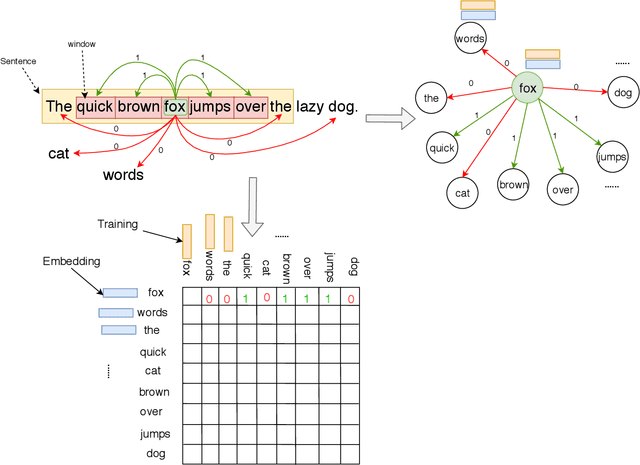
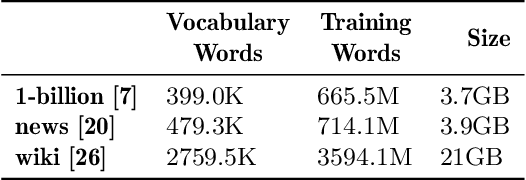
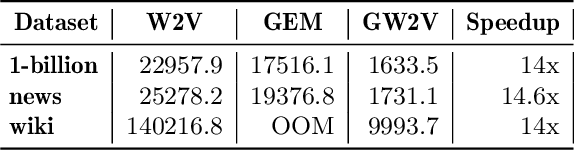
Word embeddings capture semantic and syntactic similarities of words, represented as vectors. Word2Vec is a popular implementation of word embeddings; it takes as input a large corpus of text and learns a model that maps unique words in that corpus to other contextually relevant words. After training, Word2Vec's internal vector representation of words in the corpus map unique words to a vector space, which are then used in many downstream tasks. Training these models requires significant computational resources (training time often measured in days) and is difficult to parallelize. Most word embedding training uses stochastic gradient descent (SGD), an "inherently" sequential algorithm where at each step, the processing of the current example depends on the parameters learned from the previous examples. Prior approaches to parallelizing SGD do not honor these dependencies and thus potentially suffer poor convergence. This paper introduces GraphWord2Vec, a distributedWord2Vec algorithm which formulates the Word2Vec training process as a distributed graph problem and thus leverage state-of-the-art distributed graph analytics frameworks such as D-Galois and Gemini that scale to large distributed clusters. GraphWord2Vec also demonstrates how to use model combiners to honor data dependencies in SGD and thus scale without giving up convergence. We will show that GraphWord2Vec has linear scalability up to 32 machines converging as fast as a sequential run in terms of epochs, thus reducing training time by 14x.