 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynthesizing Collective Communication Algorithms for Heterogeneous Networks with TACCL
Nov 15, 2021
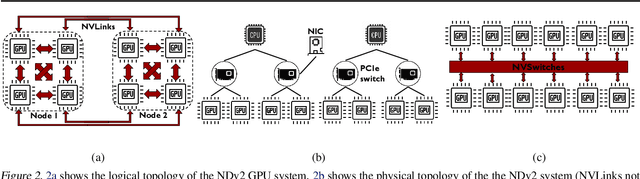
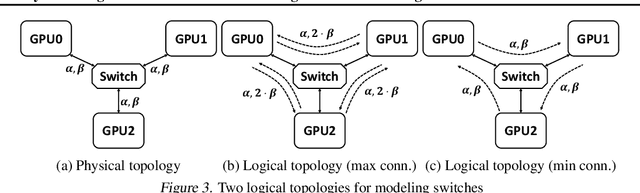
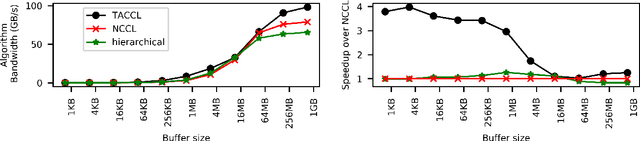
Large ML models and datasets have necessitated the use of multi-GPU systems for distributed model training. To harness the power offered by multi-GPU systems, it is critical to eliminate bottlenecks in inter-GPU communication - a problem made challenging by the heterogeneous nature of interconnects. In this work, we present TACCL, a synthesizer for collective communication primitives for large-scale multi-GPU systems. TACCL encodes a profiled topology and input size into a synthesis problem to generate optimized communication algorithms. TACCL is built on top of the standard NVIDIA Collective Communication Library (NCCL), allowing it to be a drop-in replacement for GPU communication in frameworks like PyTorch with minimal changes. TACCL generates algorithms for communication primitives like Allgather, Alltoall, and Allreduce that are up to $3\times$ faster than NCCL. Using TACCL's algorithms speeds up the end-to-end training of an internal mixture of experts model by $17\%$. By decomposing the optimization problem into parts and leveraging the symmetry in multi-GPU topologies, TACCL synthesizes collectives for up to 80-GPUs in less than 3 minutes, at least two orders of magnitude faster than other synthesis-based state-of-the-art collective communication libraries.
Synergy: Resource Sensitive DNN Scheduling in Multi-Tenant Clusters
Oct 12, 2021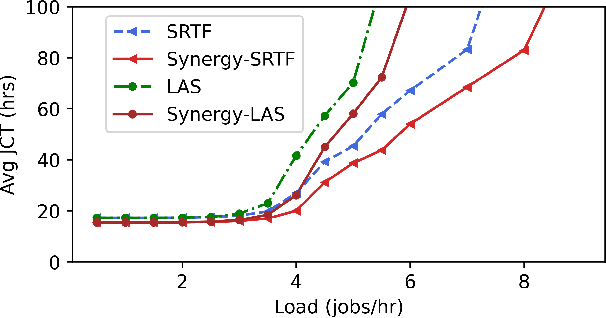
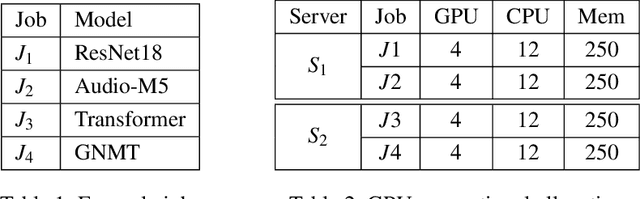
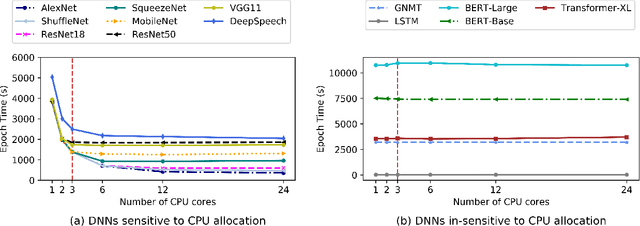
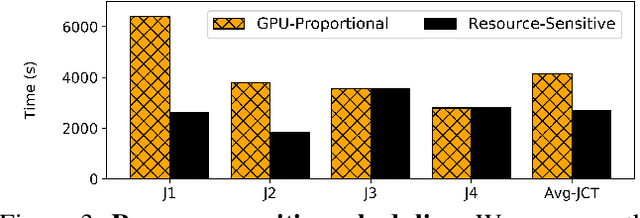
Training Deep Neural Networks (DNNs) is a widely popular workload in both enterprises and cloud data centers. Existing schedulers for DNN training consider GPU as the dominant resource, and allocate other resources such as CPU and memory proportional to the number of GPUs requested by the job. Unfortunately, these schedulers do not consider the impact of a job's sensitivity to allocation of CPU, memory, and storage resources. In this work, we propose Synergy, a resource-sensitive scheduler for shared GPU clusters. Synergy infers the sensitivity of DNNs to different resources using optimistic profiling; some jobs might benefit from more than the GPU-proportional allocation and some jobs might not be affected by less than GPU-proportional allocation. Synergy performs such multi-resource workload-aware assignments across a set of jobs scheduled on shared multi-tenant clusters using a new near-optimal online algorithm. Our experiments show that workload-aware CPU and memory allocations can improve average JCT up to 3.4x when compared to traditional GPU-proportional scheduling.
Memory Optimization for Deep Networks
Oct 29, 2020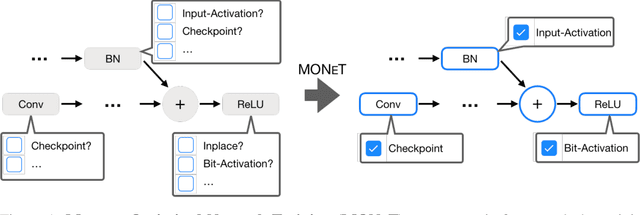


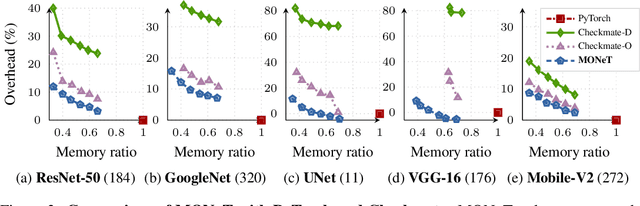
Deep learning is slowly, but steadily, hitting a memory bottleneck. While the tensor computation in top-of-the-line GPUs increased by 32x over the last five years, the total available memory only grew by 2.5x. This prevents researchers from exploring larger architectures, as training large networks requires more memory for storing intermediate outputs. In this paper, we present MONeT, an automatic framework that minimizes both the memory footprint and computational overhead of deep networks. MONeT jointly optimizes the checkpointing schedule and the implementation of various operators. MONeT is able to outperform all prior hand-tuned operations as well as automated checkpointing. MONeT reduces the overall memory requirement by 3x for various PyTorch models, with a 9-16% overhead in computation. For the same computation cost, MONeT requires 1.2-1.8x less memory than current state-of-the-art automated checkpointing frameworks. Our code is available at https://github.com/utsaslab/MONeT.
Analyzing and Mitigating Data Stalls in DNN Training
Jul 14, 2020
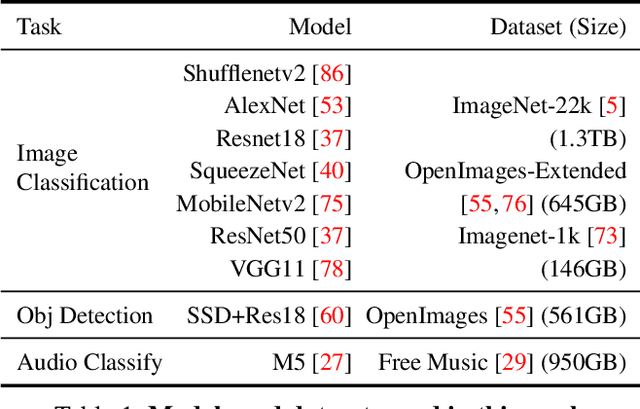
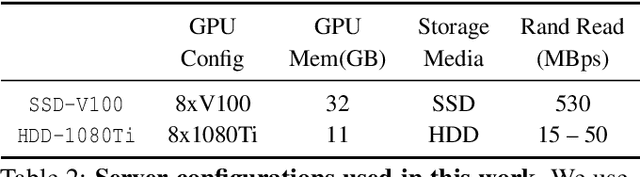
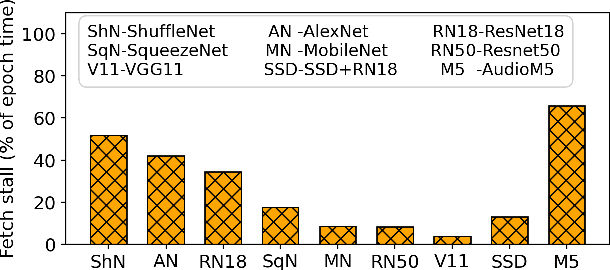
We present the first comprehensive analysis of how the data pipeline affects the training of the widely used Deep Neural Networks (DNNs). We analyze nine models and four datasets while varying factors such as the amount of memory, number of CPU threads, etc. We find that in many cases, DNN training time is dominated by data stall time: time spent waiting for data to be fetched from storage and pre-processed. Based on our insights, we build CoorDL, a novel data-loading library that accelerates DNN training by minimizing data stalls. CoorDL introduces three core techniques: coordinated pre-processing, partitioned caching, and DNN-aware software caching policy (MinIO). CoorDL does not affect training accuracy, and does not require special hardware support. CoorDL accelerates multiple aspects of DNN training: hyperparameter search, single-server training, and multi-server training. Our experiments on a range of DNN tasks, models, datasets, and hardware configurations show that CoorDL accelerates hyperparameter search by upto 5.7x, single-server training by upto 2x, and multi-server training by upto 15x compared to the state-of-the-art data loading library DALI on PyTorch.