 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEntropy-Preserving Reinforcement Learning
Mar 12, 2026Policy gradient algorithms have driven many recent advancements in language model reasoning. An appealing property is their ability to learn from exploration on their own trajectories, a process crucial for fostering diverse and creative solutions. As we show in this paper, many policy gradient algorithms naturally reduce the entropy -- and thus the diversity of explored trajectories -- as part of training, yielding a policy increasingly limited in its ability to explore. In this paper, we argue that entropy should be actively monitored and controlled throughout training. We formally analyze the contributions of leading policy gradient objectives on entropy dynamics, identify empirical factors (such as numerical precision) that significantly impact entropy behavior, and propose explicit mechanisms for entropy control. These include REPO, a family of algorithms that modify the advantage function to regulate entropy, and ADAPO, an adaptive asymmetric clipping approach. Models trained with our entropy-preserving methods maintain diversity throughout training, yielding final policies that are more performant and retain their trainability for sequential learning in new environments.
* Published at ICLR 2026
Compressed Map Priors for 3D Perception
Dec 31, 2025Human drivers rarely travel where no person has gone before. After all, thousands of drivers use busy city roads every day, and only one can claim to be the first. The same holds for autonomous computer vision systems. The vast majority of the deployment area of an autonomous vision system will have been visited before. Yet, most autonomous vehicle vision systems act as if they are encountering each location for the first time. In this work, we present Compressed Map Priors (CMP), a simple but effective framework to learn spatial priors from historic traversals. The map priors use a binarized hashmap that requires only $32\text{KB}/\text{km}^2$, a $20\times$ reduction compared to the dense storage. Compressed Map Priors easily integrate into leading 3D perception systems at little to no extra computational costs, and lead to a significant and consistent improvement in 3D object detection on the nuScenes dataset across several architectures.
Spherical Leech Quantization for Visual Tokenization and Generation
Dec 16, 2025



Non-parametric quantization has received much attention due to its efficiency on parameters and scalability to a large codebook. In this paper, we present a unified formulation of different non-parametric quantization methods through the lens of lattice coding. The geometry of lattice codes explains the necessity of auxiliary loss terms when training auto-encoders with certain existing lookup-free quantization variants such as BSQ. As a step forward, we explore a few possible candidates, including random lattices, generalized Fibonacci lattices, and densest sphere packing lattices. Among all, we find the Leech lattice-based quantization method, which is dubbed as Spherical Leech Quantization ($Λ_{24}$-SQ), leads to both a simplified training recipe and an improved reconstruction-compression tradeoff thanks to its high symmetry and even distribution on the hypersphere. In image tokenization and compression tasks, this quantization approach achieves better reconstruction quality across all metrics than BSQ, the best prior art, while consuming slightly fewer bits. The improvement also extends to state-of-the-art auto-regressive image generation frameworks.
Interactive Post-Training for Vision-Language-Action Models
May 22, 2025We introduce RIPT-VLA, a simple and scalable reinforcement-learning-based interactive post-training paradigm that fine-tunes pretrained Vision-Language-Action (VLA) models using only sparse binary success rewards. Existing VLA training pipelines rely heavily on offline expert demonstration data and supervised imitation, limiting their ability to adapt to new tasks and environments under low-data regimes. RIPT-VLA addresses this by enabling interactive post-training with a stable policy optimization algorithm based on dynamic rollout sampling and leave-one-out advantage estimation. RIPT-VLA has the following characteristics. First, it applies to various VLA models, resulting in an improvement on the lightweight QueST model by 21.2%, and the 7B OpenVLA-OFT model to an unprecedented 97.5% success rate. Second, it is computationally efficient and data-efficient: with only one demonstration, RIPT-VLA enables an unworkable SFT model (4%) to succeed with a 97% success rate within 15 iterations. Furthermore, we demonstrate that the policy learned by RIPT-VLA generalizes across different tasks and scenarios and is robust to the initial state context. These results highlight RIPT-VLA as a practical and effective paradigm for post-training VLA models through minimal supervision.
PerceptionLM: Open-Access Data and Models for Detailed Visual Understanding
Apr 17, 2025



Vision-language models are integral to computer vision research, yet many high-performing models remain closed-source, obscuring their data, design and training recipe. The research community has responded by using distillation from black-box models to label training data, achieving strong benchmark results, at the cost of measurable scientific progress. However, without knowing the details of the teacher model and its data sources, scientific progress remains difficult to measure. In this paper, we study building a Perception Language Model (PLM) in a fully open and reproducible framework for transparent research in image and video understanding. We analyze standard training pipelines without distillation from proprietary models and explore large-scale synthetic data to identify critical data gaps, particularly in detailed video understanding. To bridge these gaps, we release 2.8M human-labeled instances of fine-grained video question-answer pairs and spatio-temporally grounded video captions. Additionally, we introduce PLM-VideoBench, a suite for evaluating challenging video understanding tasks focusing on the ability to reason about "what", "where", "when", and "how" of a video. We make our work fully reproducible by providing data, training recipes, code & models.
QLIP: Text-Aligned Visual Tokenization Unifies Auto-Regressive Multimodal Understanding and Generation
Feb 07, 2025We introduce Quantized Language-Image Pretraining (QLIP), a visual tokenization method that combines state-of-the-art reconstruction quality with state-of-the-art zero-shot image understanding. QLIP trains a binary-spherical-quantization-based autoencoder with reconstruction and language-image alignment objectives. We are the first to show that the two objectives do not need to be at odds. We balance the two loss terms dynamically during training and show that a two-stage training pipeline effectively mixes the large-batch requirements of image-language pre-training with the memory bottleneck imposed by the reconstruction objective. We validate the effectiveness of QLIP for multimodal understanding and text-conditioned image generation with a single model. Specifically, QLIP serves as a drop-in replacement for the visual encoder for LLaVA and the image tokenizer for LlamaGen with comparable or even better performance. Finally, we demonstrate that QLIP enables a unified mixed-modality auto-regressive model for understanding and generation.
Robust Autonomy Emerges from Self-Play
Feb 05, 2025Self-play has powered breakthroughs in two-player and multi-player games. Here we show that self-play is a surprisingly effective strategy in another domain. We show that robust and naturalistic driving emerges entirely from self-play in simulation at unprecedented scale -- 1.6~billion~km of driving. This is enabled by Gigaflow, a batched simulator that can synthesize and train on 42 years of subjective driving experience per hour on a single 8-GPU node. The resulting policy achieves state-of-the-art performance on three independent autonomous driving benchmarks. The policy outperforms the prior state of the art when tested on recorded real-world scenarios, amidst human drivers, without ever seeing human data during training. The policy is realistic when assessed against human references and achieves unprecedented robustness, averaging 17.5 years of continuous driving between incidents in simulation.
Reinforcement Learning for Long-Horizon Interactive LLM Agents
Feb 04, 2025Interactive digital agents (IDAs) leverage APIs of stateful digital environments to perform tasks in response to user requests. While IDAs powered by instruction-tuned large language models (LLMs) can react to feedback from interface invocations in multi-step exchanges, they have not been trained in their respective digital environments. Prior methods accomplish less than half of tasks in sophisticated benchmarks such as AppWorld. We present a reinforcement learning (RL) approach that trains IDAs directly in their target environments. We formalize this training as a partially observable Markov decision process and derive LOOP, a data- and memory-efficient variant of proximal policy optimization. LOOP uses no value network and maintains exactly one copy of the underlying LLM in memory, making its implementation straightforward and as memory-efficient as fine-tuning a single LLM. A 32-billion-parameter agent trained with LOOP in the AppWorld environment outperforms the much larger OpenAI o1 agent by 9 percentage points (15% relative). To our knowledge, this is the first reported application of RL to IDAs that interact with a stateful, multi-domain, multi-app environment via direct API calls. Our analysis sheds light on the effectiveness of RL in this area, showing that the agent learns to consult the API documentation, avoid unwarranted assumptions, minimize confabulation, and recover from setbacks.
Cut Your Losses in Large-Vocabulary Language Models
Nov 13, 2024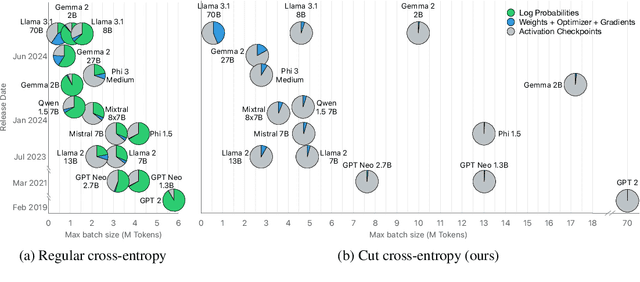
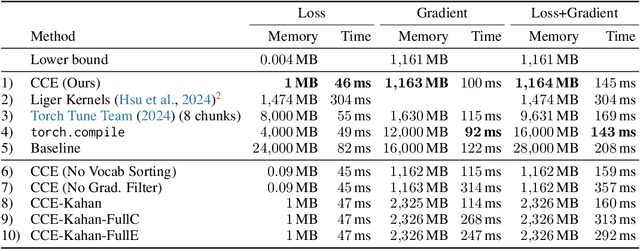
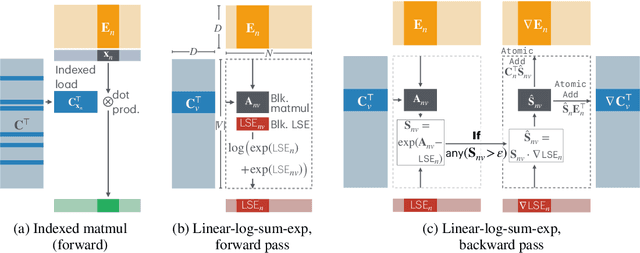
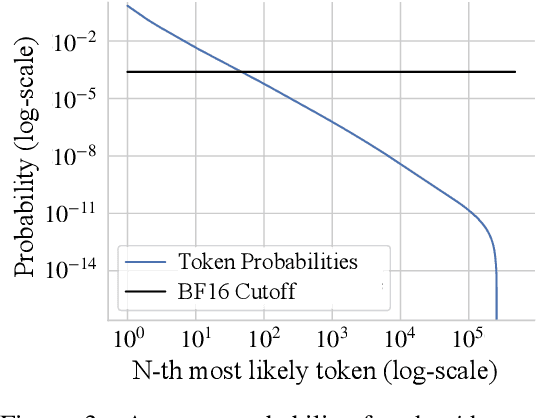
As language models grow ever larger, so do their vocabularies. This has shifted the memory footprint of LLMs during training disproportionately to one single layer: the cross-entropy in the loss computation. Cross-entropy builds up a logit matrix with entries for each pair of input tokens and vocabulary items and, for small models, consumes an order of magnitude more memory than the rest of the LLM combined. We propose Cut Cross-Entropy (CCE), a method that computes the cross-entropy loss without materializing the logits for all tokens into global memory. Rather, CCE only computes the logit for the correct token and evaluates the log-sum-exp over all logits on the fly. We implement a custom kernel that performs the matrix multiplications and the log-sum-exp reduction over the vocabulary in flash memory, making global memory consumption for the cross-entropy computation negligible. This has a dramatic effect. Taking the Gemma 2 (2B) model as an example, CCE reduces the memory footprint of the loss computation from 24 GB to 1 MB, and the total training-time memory consumption of the classifier head from 28 GB to 1 GB. To improve the throughput of CCE, we leverage the inherent sparsity of softmax and propose to skip elements of the gradient computation that have a negligible (i.e., below numerical precision) contribution to the gradient. Experiments demonstrate that the dramatic reduction in memory consumption is accomplished without sacrificing training speed or convergence.
Promptable Closed-loop Traffic Simulation
Sep 09, 2024


Simulation stands as a cornerstone for safe and efficient autonomous driving development. At its core a simulation system ought to produce realistic, reactive, and controllable traffic patterns. In this paper, we propose ProSim, a multimodal promptable closed-loop traffic simulation framework. ProSim allows the user to give a complex set of numerical, categorical or textual prompts to instruct each agent's behavior and intention. ProSim then rolls out a traffic scenario in a closed-loop manner, modeling each agent's interaction with other traffic participants. Our experiments show that ProSim achieves high prompt controllability given different user prompts, while reaching competitive performance on the Waymo Sim Agents Challenge when no prompt is given. To support research on promptable traffic simulation, we create ProSim-Instruct-520k, a multimodal prompt-scenario paired driving dataset with over 10M text prompts for over 520k real-world driving scenarios. We will release code of ProSim as well as data and labeling tools of ProSim-Instruct-520k at https://ariostgx.github.io/ProSim.