 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThinkJEPA: Empowering Latent World Models with Large Vision-Language Reasoning Model
Mar 23, 2026Recent progress in latent world models (e.g., V-JEPA2) has shown promising capability in forecasting future world states from video observations. Nevertheless, dense prediction from a short observation window limits temporal context and can bias predictors toward local, low-level extrapolation, making it difficult to capture long-horizon semantics and reducing downstream utility. Vision--language models (VLMs), in contrast, provide strong semantic grounding and general knowledge by reasoning over uniformly sampled frames, but they are not ideal as standalone dense predictors due to compute-driven sparse sampling, a language-output bottleneck that compresses fine-grained interaction states into text-oriented representations, and a data-regime mismatch when adapting to small action-conditioned datasets. We propose a VLM-guided JEPA-style latent world modeling framework that combines dense-frame dynamics modeling with long-horizon semantic guidance via a dual-temporal pathway: a dense JEPA branch for fine-grained motion and interaction cues, and a uniformly sampled VLM \emph{thinker} branch with a larger temporal stride for knowledge-rich guidance. To transfer the VLM's progressive reasoning signals effectively, we introduce a hierarchical pyramid representation extraction module that aggregates multi-layer VLM representations into guidance features compatible with latent prediction. Experiments on hand-manipulation trajectory prediction show that our method outperforms both a strong VLM-only baseline and a JEPA-predictor baseline, and yields more robust long-horizon rollout behavior.
A Lightweight Library for Energy-Based Joint-Embedding Predictive Architectures
Feb 03, 2026We present EB-JEPA, an open-source library for learning representations and world models using Joint-Embedding Predictive Architectures (JEPAs). JEPAs learn to predict in representation space rather than pixel space, avoiding the pitfalls of generative modeling while capturing semantically meaningful features suitable for downstream tasks. Our library provides modular, self-contained implementations that illustrate how representation learning techniques developed for image-level self-supervised learning can transfer to video, where temporal dynamics add complexity, and ultimately to action-conditioned world models, where the model must additionally learn to predict the effects of control inputs. Each example is designed for single-GPU training within a few hours, making energy-based self-supervised learning accessible for research and education. We provide ablations of JEA components on CIFAR-10. Probing these representations yields 91% accuracy, indicating that the model learns useful features. Extending to video, we include a multi-step prediction example on Moving MNIST that demonstrates how the same principles scale to temporal modeling. Finally, we show how these representations can drive action-conditioned world models, achieving a 97% planning success rate on the Two Rooms navigation task. Comprehensive ablations reveal the critical importance of each regularization component for preventing representation collapse. Code is available at https://github.com/facebookresearch/eb_jepa.
Learning Latent Action World Models In The Wild
Jan 08, 2026Agents capable of reasoning and planning in the real world require the ability of predicting the consequences of their actions. While world models possess this capability, they most often require action labels, that can be complex to obtain at scale. This motivates the learning of latent action models, that can learn an action space from videos alone. Our work addresses the problem of learning latent actions world models on in-the-wild videos, expanding the scope of existing works that focus on simple robotics simulations, video games, or manipulation data. While this allows us to capture richer actions, it also introduces challenges stemming from the video diversity, such as environmental noise, or the lack of a common embodiment across videos. To address some of the challenges, we discuss properties that actions should follow as well as relevant architectural choices and evaluations. We find that continuous, but constrained, latent actions are able to capture the complexity of actions from in-the-wild videos, something that the common vector quantization does not. We for example find that changes in the environment coming from agents, such as humans entering the room, can be transferred across videos. This highlights the capability of learning actions that are specific to in-the-wild videos. In the absence of a common embodiment across videos, we are mainly able to learn latent actions that become localized in space, relative to the camera. Nonetheless, we are able to train a controller that maps known actions to latent ones, allowing us to use latent actions as a universal interface and solve planning tasks with our world model with similar performance as action-conditioned baselines. Our analyses and experiments provide a step towards scaling latent action models to the real world.
PerceptionLM: Open-Access Data and Models for Detailed Visual Understanding
Apr 17, 2025



Vision-language models are integral to computer vision research, yet many high-performing models remain closed-source, obscuring their data, design and training recipe. The research community has responded by using distillation from black-box models to label training data, achieving strong benchmark results, at the cost of measurable scientific progress. However, without knowing the details of the teacher model and its data sources, scientific progress remains difficult to measure. In this paper, we study building a Perception Language Model (PLM) in a fully open and reproducible framework for transparent research in image and video understanding. We analyze standard training pipelines without distillation from proprietary models and explore large-scale synthetic data to identify critical data gaps, particularly in detailed video understanding. To bridge these gaps, we release 2.8M human-labeled instances of fine-grained video question-answer pairs and spatio-temporally grounded video captions. Additionally, we introduce PLM-VideoBench, a suite for evaluating challenging video understanding tasks focusing on the ability to reason about "what", "where", "when", and "how" of a video. We make our work fully reproducible by providing data, training recipes, code & models.
VITED: Video Temporal Evidence Distillation
Mar 17, 2025We investigate complex video question answering via chain-of-evidence reasoning -- identifying sequences of temporal spans from multiple relevant parts of the video, together with visual evidence within them. Existing models struggle with multi-step reasoning as they uniformly sample a fixed number of frames, which can miss critical evidence distributed nonuniformly throughout the video. Moreover, they lack the ability to temporally localize such evidence in the broader context of the full video, which is required for answering complex questions. We propose a framework to enhance existing VideoQA datasets with evidence reasoning chains, automatically constructed by searching for optimal intervals of interest in the video with supporting evidence, that maximizes the likelihood of answering a given question. We train our model (VITED) to generate these evidence chains directly, enabling it to both localize evidence windows as well as perform multi-step reasoning across them in long-form video content. We show the value of our evidence-distilled models on a suite of long video QA benchmarks where we outperform state-of-the-art approaches that lack evidence reasoning capabilities.
SPOC: Spatially-Progressing Object State Change Segmentation in Video
Mar 15, 2025Object state changes in video reveal critical information about human and agent activity. However, existing methods are limited to temporal localization of when the object is in its initial state (e.g., the unchopped avocado) versus when it has completed a state change (e.g., the chopped avocado), which limits applicability for any task requiring detailed information about the progress of the actions and its spatial localization. We propose to deepen the problem by introducing the spatially-progressing object state change segmentation task. The goal is to segment at the pixel-level those regions of an object that are actionable and those that are transformed. We introduce the first model to address this task, designing a VLM-based pseudo-labeling approach, state-change dynamics constraints, and a novel WhereToChange benchmark built on in-the-wild Internet videos. Experiments on two datasets validate both the challenge of the new task as well as the promise of our model for localizing exactly where and how fast objects are changing in video. We further demonstrate useful implications for tracking activity progress to benefit robotic agents. Project page: https://vision.cs.utexas.edu/projects/spoc-spatially-progressing-osc
BIMBA: Selective-Scan Compression for Long-Range Video Question Answering
Mar 13, 2025Video Question Answering (VQA) in long videos poses the key challenge of extracting relevant information and modeling long-range dependencies from many redundant frames. The self-attention mechanism provides a general solution for sequence modeling, but it has a prohibitive cost when applied to a massive number of spatiotemporal tokens in long videos. Most prior methods rely on compression strategies to lower the computational cost, such as reducing the input length via sparse frame sampling or compressing the output sequence passed to the large language model (LLM) via space-time pooling. However, these naive approaches over-represent redundant information and often miss salient events or fast-occurring space-time patterns. In this work, we introduce BIMBA, an efficient state-space model to handle long-form videos. Our model leverages the selective scan algorithm to learn to effectively select critical information from high-dimensional video and transform it into a reduced token sequence for efficient LLM processing. Extensive experiments demonstrate that BIMBA achieves state-of-the-art accuracy on multiple long-form VQA benchmarks, including PerceptionTest, NExT-QA, EgoSchema, VNBench, LongVideoBench, and Video-MME. Code, and models are publicly available at https://sites.google.com/view/bimba-mllm.
Switch-a-View: Few-Shot View Selection Learned from Edited Videos
Dec 24, 2024We introduce Switch-a-View, a model that learns to automatically select the viewpoint to display at each timepoint when creating a how-to video. The key insight of our approach is how to train such a model from unlabeled--but human-edited--video samples. We pose a pretext task that pseudo-labels segments in the training videos for their primary viewpoint (egocentric or exocentric), and then discovers the patterns between those view-switch moments on the one hand and the visual and spoken content in the how-to video on the other hand. Armed with this predictor, our model then takes an unseen multi-view video as input and orchestrates which viewpoint should be displayed when. We further introduce a few-shot training setting that permits steering the model towards a new data domain. We demonstrate our idea on a variety of real-world video from HowTo100M and Ego-Exo4D and rigorously validate its advantages.
Which Viewpoint Shows it Best? Language for Weakly Supervising View Selection in Multi-view Videos
Nov 13, 2024



Given a multi-view video, which viewpoint is most informative for a human observer? Existing methods rely on heuristics or expensive ``best-view" supervision to answer this question, limiting their applicability. We propose a weakly supervised approach that leverages language accompanying an instructional multi-view video as a means to recover its most informative viewpoint(s). Our key hypothesis is that the more accurately an individual view can predict a view-agnostic text summary, the more informative it is. To put this into action, we propose a framework that uses the relative accuracy of view-dependent caption predictions as a proxy for best view pseudo-labels. Then, those pseudo-labels are used to train a view selector, together with an auxiliary camera pose predictor that enhances view-sensitivity. During inference, our model takes as input only a multi-view video -- no language or camera poses -- and returns the best viewpoint to watch at each timestep. On two challenging datasets comprised of diverse multi-camera setups and how-to activities, our model consistently outperforms state-of-the-art baselines, both with quantitative metrics and human evaluation.
Human Action Anticipation: A Survey
Oct 17, 2024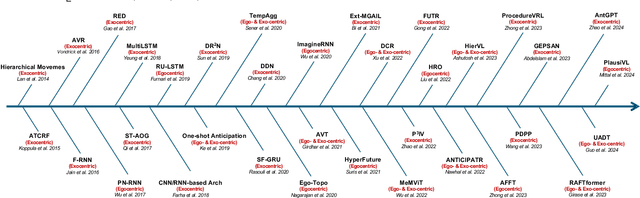

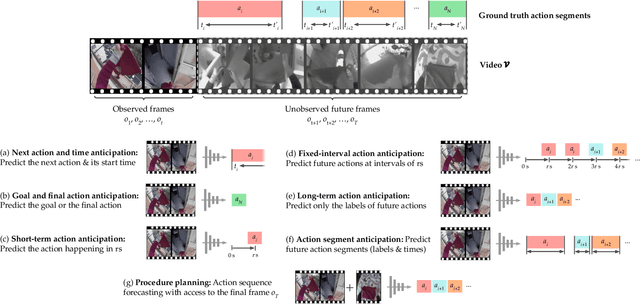
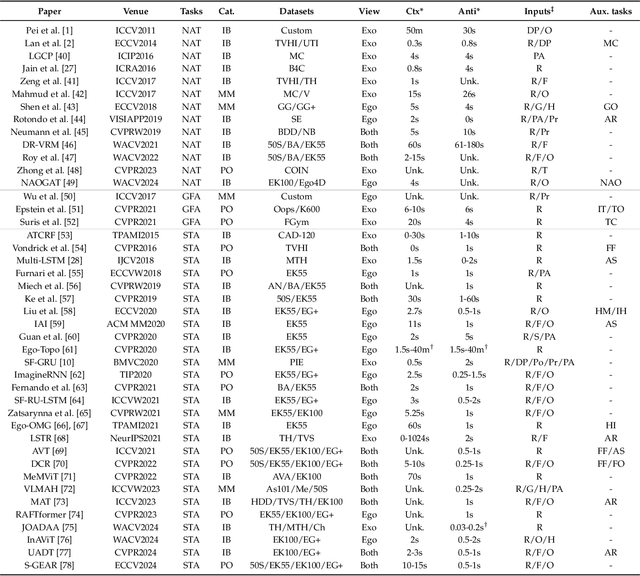
Predicting future human behavior is an increasingly popular topic in computer vision, driven by the interest in applications such as autonomous vehicles, digital assistants and human-robot interactions. The literature on behavior prediction spans various tasks, including action anticipation, activity forecasting, intent prediction, goal prediction, and so on. Our survey aims to tie together this fragmented literature, covering recent technical innovations as well as the development of new large-scale datasets for model training and evaluation. We also summarize the widely-used metrics for different tasks and provide a comprehensive performance comparison of existing approaches on eleven action anticipation datasets. This survey serves as not only a reference for contemporary methodologies in action anticipation, but also a guideline for future research direction of this evolving landscape.