 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSERM: Self-Evolving Relevance Model with Agent-Driven Learning from Massive Query Streams
Jan 14, 2026Due to the dynamically evolving nature of real-world query streams, relevance models struggle to generalize to practical search scenarios. A sophisticated solution is self-evolution techniques. However, in large-scale industrial settings with massive query streams, this technique faces two challenges: (1) informative samples are often sparse and difficult to identify, and (2) pseudo-labels generated by the current model could be unreliable. To address these challenges, in this work, we propose a Self-Evolving Relevance Model approach (SERM), which comprises two complementary multi-agent modules: a multi-agent sample miner, designed to detect distributional shifts and identify informative training samples, and a multi-agent relevance annotator, which provides reliable labels through a two-level agreement framework. We evaluate SERM in a large-scale industrial setting, which serves billions of user requests daily. Experimental results demonstrate that SERM can achieve significant performance gains through iterative self-evolution, as validated by extensive offline multilingual evaluations and online testing.
Zebrafish Counting Using Event Stream Data
Apr 18, 2025



Zebrafish share a high degree of homology with human genes and are commonly used as model organism in biomedical research. For medical laboratories, counting zebrafish is a daily task. Due to the tiny size of zebrafish, manual visual counting is challenging. Existing counting methods are either not applicable to small fishes or have too many limitations. The paper proposed a zebrafish counting algorithm based on the event stream data. Firstly, an event camera is applied for data acquisition. Secondly, camera calibration and image fusion were preformed successively. Then, the trajectory information was used to improve the counting accuracy. Finally, the counting results were averaged over an empirical of period and rounded up to get the final results. To evaluate the accuracy of the algorithm, 20 zebrafish were put in a four-liter breeding tank. Among 100 counting trials, the average accuracy reached 97.95%. As compared with traditional algorithms, the proposed one offers a simpler implementation and achieves higher accuracy.
PerceptionLM: Open-Access Data and Models for Detailed Visual Understanding
Apr 17, 2025



Vision-language models are integral to computer vision research, yet many high-performing models remain closed-source, obscuring their data, design and training recipe. The research community has responded by using distillation from black-box models to label training data, achieving strong benchmark results, at the cost of measurable scientific progress. However, without knowing the details of the teacher model and its data sources, scientific progress remains difficult to measure. In this paper, we study building a Perception Language Model (PLM) in a fully open and reproducible framework for transparent research in image and video understanding. We analyze standard training pipelines without distillation from proprietary models and explore large-scale synthetic data to identify critical data gaps, particularly in detailed video understanding. To bridge these gaps, we release 2.8M human-labeled instances of fine-grained video question-answer pairs and spatio-temporally grounded video captions. Additionally, we introduce PLM-VideoBench, a suite for evaluating challenging video understanding tasks focusing on the ability to reason about "what", "where", "when", and "how" of a video. We make our work fully reproducible by providing data, training recipes, code & models.
BIMBA: Selective-Scan Compression for Long-Range Video Question Answering
Mar 13, 2025Video Question Answering (VQA) in long videos poses the key challenge of extracting relevant information and modeling long-range dependencies from many redundant frames. The self-attention mechanism provides a general solution for sequence modeling, but it has a prohibitive cost when applied to a massive number of spatiotemporal tokens in long videos. Most prior methods rely on compression strategies to lower the computational cost, such as reducing the input length via sparse frame sampling or compressing the output sequence passed to the large language model (LLM) via space-time pooling. However, these naive approaches over-represent redundant information and often miss salient events or fast-occurring space-time patterns. In this work, we introduce BIMBA, an efficient state-space model to handle long-form videos. Our model leverages the selective scan algorithm to learn to effectively select critical information from high-dimensional video and transform it into a reduced token sequence for efficient LLM processing. Extensive experiments demonstrate that BIMBA achieves state-of-the-art accuracy on multiple long-form VQA benchmarks, including PerceptionTest, NExT-QA, EgoSchema, VNBench, LongVideoBench, and Video-MME. Code, and models are publicly available at https://sites.google.com/view/bimba-mllm.
TimeRefine: Temporal Grounding with Time Refining Video LLM
Dec 12, 2024



Video temporal grounding aims to localize relevant temporal boundaries in a video given a textual prompt. Recent work has focused on enabling Video LLMs to perform video temporal grounding via next-token prediction of temporal timestamps. However, accurately localizing timestamps in videos remains challenging for Video LLMs when relying solely on temporal token prediction. Our proposed TimeRefine addresses this challenge in two ways. First, instead of directly predicting the start and end timestamps, we reformulate the temporal grounding task as a temporal refining task: the model first makes rough predictions and then refines them by predicting offsets to the target segment. This refining process is repeated multiple times, through which the model progressively self-improves its temporal localization accuracy. Second, to enhance the model's temporal perception capabilities, we incorporate an auxiliary prediction head that penalizes the model more if a predicted segment deviates further from the ground truth, thus encouraging the model to make closer and more accurate predictions. Our plug-and-play method can be integrated into most LLM-based temporal grounding approaches. The experimental results demonstrate that TimeRefine achieves 3.6% and 5.0% mIoU improvements on the ActivityNet and Charades-STA datasets, respectively. Code and pretrained models will be released.
MusicFlow: Cascaded Flow Matching for Text Guided Music Generation
Oct 27, 2024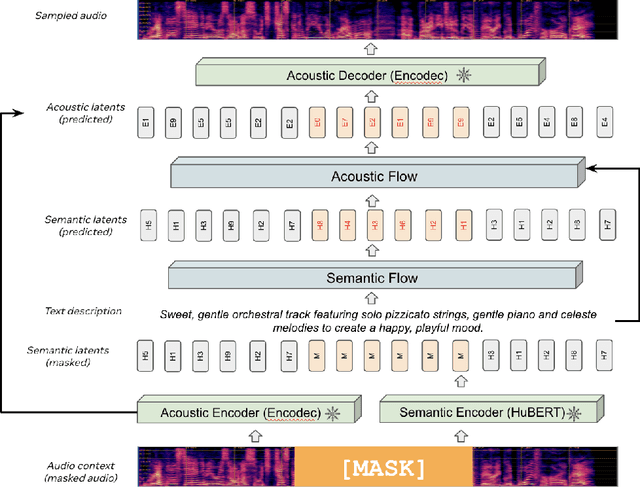
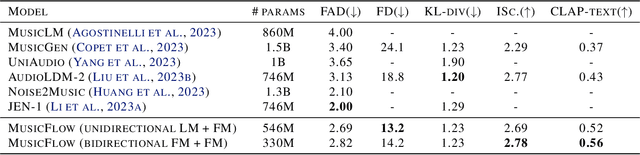
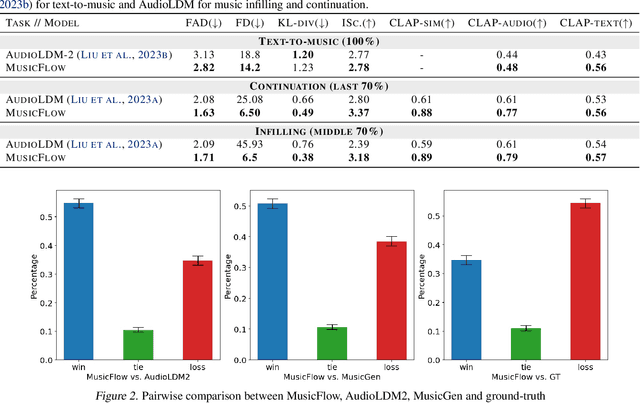
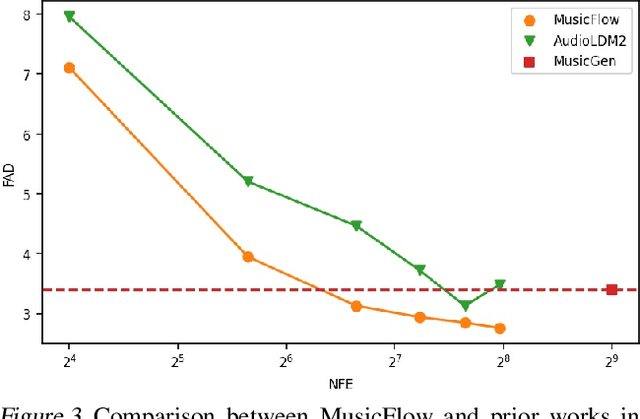
We introduce MusicFlow, a cascaded text-to-music generation model based on flow matching. Based on self-supervised representations to bridge between text descriptions and music audios, we construct two flow matching networks to model the conditional distribution of semantic and acoustic features. Additionally, we leverage masked prediction as the training objective, enabling the model to generalize to other tasks such as music infilling and continuation in a zero-shot manner. Experiments on MusicCaps reveal that the music generated by MusicFlow exhibits superior quality and text coherence despite being over $2\sim5$ times smaller and requiring $5$ times fewer iterative steps. Simultaneously, the model can perform other music generation tasks and achieves competitive performance in music infilling and continuation. Our code and model will be publicly available.
Propose, Assess, Search: Harnessing LLMs for Goal-Oriented Planning in Instructional Videos
Sep 30, 2024
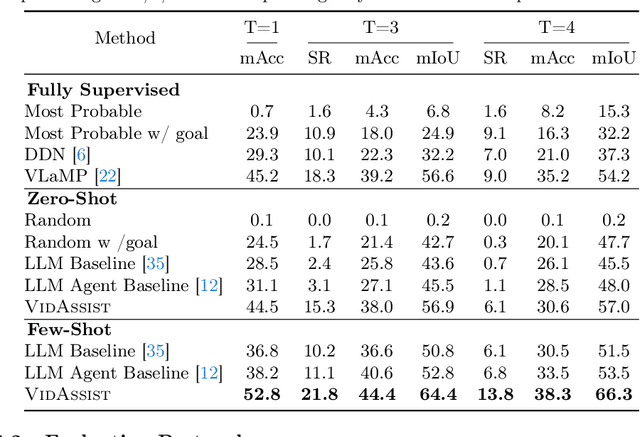
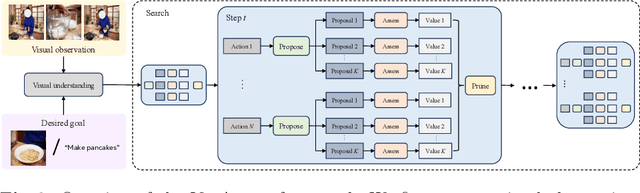
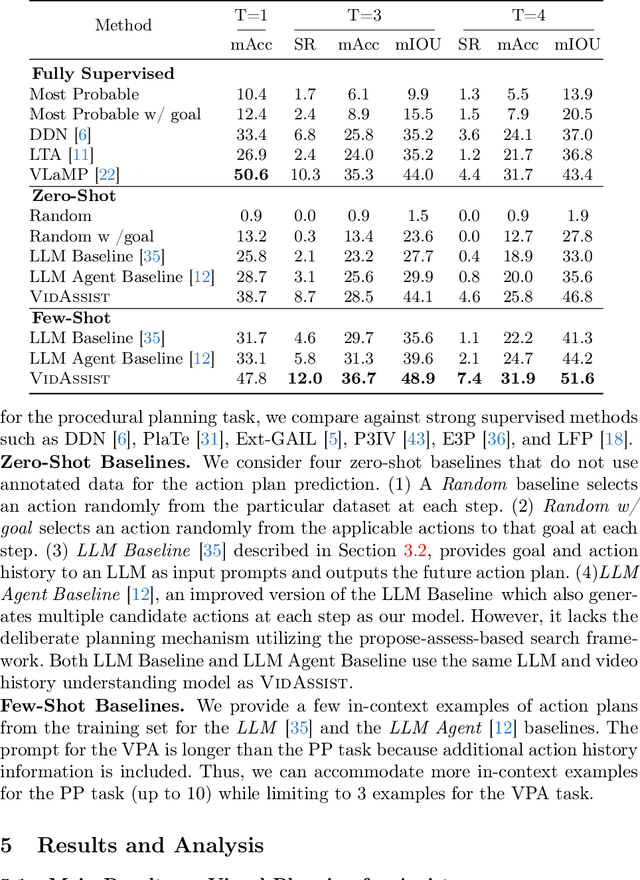
Goal-oriented planning, or anticipating a series of actions that transition an agent from its current state to a predefined objective, is crucial for developing intelligent assistants aiding users in daily procedural tasks. The problem presents significant challenges due to the need for comprehensive knowledge of temporal and hierarchical task structures, as well as strong capabilities in reasoning and planning. To achieve this, prior work typically relies on extensive training on the target dataset, which often results in significant dataset bias and a lack of generalization to unseen tasks. In this work, we introduce VidAssist, an integrated framework designed for zero/few-shot goal-oriented planning in instructional videos. VidAssist leverages large language models (LLMs) as both the knowledge base and the assessment tool for generating and evaluating action plans, thus overcoming the challenges of acquiring procedural knowledge from small-scale, low-diversity datasets. Moreover, VidAssist employs a breadth-first search algorithm for optimal plan generation, in which a composite of value functions designed for goal-oriented planning is utilized to assess the predicted actions at each step. Extensive experiments demonstrate that VidAssist offers a unified framework for different goal-oriented planning setups, e.g., visual planning for assistance (VPA) and procedural planning (PP), and achieves remarkable performance in zero-shot and few-shot setups. Specifically, our few-shot model outperforms the prior fully supervised state-of-the-art method by +7.7% in VPA and +4.81% PP task on the COIN dataset while predicting 4 future actions. Code, and models are publicly available at https://sites.google.com/view/vidassist.
VideoINSTA: Zero-shot Long Video Understanding via Informative Spatial-Temporal Reasoning with LLMs
Sep 30, 2024



In the video-language domain, recent works in leveraging zero-shot Large Language Model-based reasoning for video understanding have become competitive challengers to previous end-to-end models. However, long video understanding presents unique challenges due to the complexity of reasoning over extended timespans, even for zero-shot LLM-based approaches. The challenge of information redundancy in long videos prompts the question of what specific information is essential for large language models (LLMs) and how to leverage them for complex spatial-temporal reasoning in long-form video analysis. We propose a framework VideoINSTA, i.e. INformative Spatial-TemporAl Reasoning for zero-shot long-form video understanding. VideoINSTA contributes (1) a zero-shot framework for long video understanding using LLMs; (2) an event-based temporal reasoning and content-based spatial reasoning approach for LLMs to reason over spatial-temporal information in videos; (3) a self-reflective information reasoning scheme balancing temporal factors based on information sufficiency and prediction confidence. Our model significantly improves the state-of-the-art on three long video question-answering benchmarks: EgoSchema, NextQA, and IntentQA, and the open question answering dataset ActivityNetQA. The code is released here: https://github.com/mayhugotong/VideoINSTA.
Unlocking Exocentric Video-Language Data for Egocentric Video Representation Learning
Aug 07, 2024We present EMBED (Egocentric Models Built with Exocentric Data), a method designed to transform exocentric video-language data for egocentric video representation learning. Large-scale exocentric data covers diverse activities with significant potential for egocentric learning, but inherent disparities between egocentric and exocentric data pose challenges in utilizing one view for the other seamlessly. Egocentric videos predominantly feature close-up hand-object interactions, whereas exocentric videos offer a broader perspective on human activities. Additionally, narratives in egocentric datasets are typically more action-centric and closely linked with the visual content, in contrast to the narrative styles found in exocentric datasets. To address these challenges, we employ a data transformation framework to adapt exocentric data for egocentric training, focusing on identifying specific video clips that emphasize hand-object interactions and transforming narration styles to align with egocentric perspectives. By applying both vision and language style transfer, our framework creates a new egocentric dataset derived from exocentric video-language data. Through extensive evaluations, we demonstrate the effectiveness of EMBED, achieving state-of-the-art results across various egocentric downstream tasks, including an absolute improvement of 4.7% on the Epic-Kitchens-100 multi-instance retrieval and 6.2% on the EGTEA classification benchmarks in zero-shot settings. Furthermore, EMBED enables egocentric video-language models to perform competitively in exocentric tasks. Finally, we showcase EMBED's application across various exocentric datasets, exhibiting strong generalization capabilities when applied to different exocentric datasets.
Rethinking Video-Text Understanding: Retrieval from Counterfactually Augmented Data
Jul 18, 2024Recent video-text foundation models have demonstrated strong performance on a wide variety of downstream video understanding tasks. Can these video-text models genuinely understand the contents of natural videos? Standard video-text evaluations could be misleading as many questions can be inferred merely from the objects and contexts in a single frame or biases inherent in the datasets. In this paper, we aim to better assess the capabilities of current video-text models and understand their limitations. We propose a novel evaluation task for video-text understanding, namely retrieval from counterfactually augmented data (RCAD), and a new Feint6K dataset. To succeed on our new evaluation task, models must derive a comprehensive understanding of the video from cross-frame reasoning. Analyses show that previous video-text foundation models can be easily fooled by counterfactually augmented data and are far behind human-level performance. In order to narrow the gap between video-text models and human performance on RCAD, we identify a key limitation of current contrastive approaches on video-text data and introduce LLM-teacher, a more effective approach to learn action semantics by leveraging knowledge obtained from a pretrained large language model. Experiments and analyses show that our approach successfully learn more discriminative action embeddings and improves results on Feint6K when applied to multiple video-text models. Our Feint6K dataset and project page is available at https://feint6k.github.io.