 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSAM 3D Body: Robust Full-Body Human Mesh Recovery
Feb 17, 2026We introduce SAM 3D Body (3DB), a promptable model for single-image full-body 3D human mesh recovery (HMR) that demonstrates state-of-the-art performance, with strong generalization and consistent accuracy in diverse in-the-wild conditions. 3DB estimates the human pose of the body, feet, and hands. It is the first model to use a new parametric mesh representation, Momentum Human Rig (MHR), which decouples skeletal structure and surface shape. 3DB employs an encoder-decoder architecture and supports auxiliary prompts, including 2D keypoints and masks, enabling user-guided inference similar to the SAM family of models. We derive high-quality annotations from a multi-stage annotation pipeline that uses various combinations of manual keypoint annotation, differentiable optimization, multi-view geometry, and dense keypoint detection. Our data engine efficiently selects and processes data to ensure data diversity, collecting unusual poses and rare imaging conditions. We present a new evaluation dataset organized by pose and appearance categories, enabling nuanced analysis of model behavior. Our experiments demonstrate superior generalization and substantial improvements over prior methods in both qualitative user preference studies and traditional quantitative analysis. Both 3DB and MHR are open-source.
Progress-Aware Video Frame Captioning
Dec 03, 2024
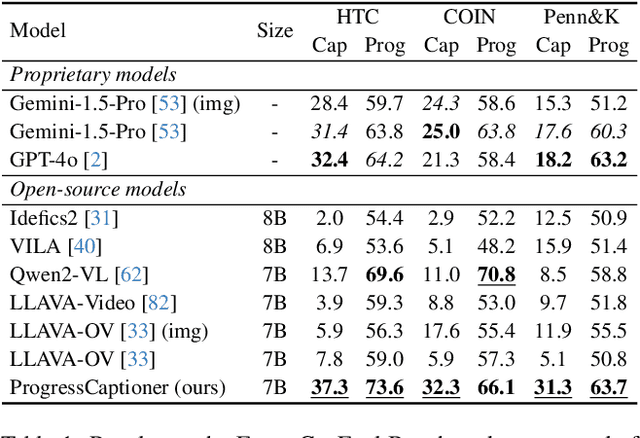
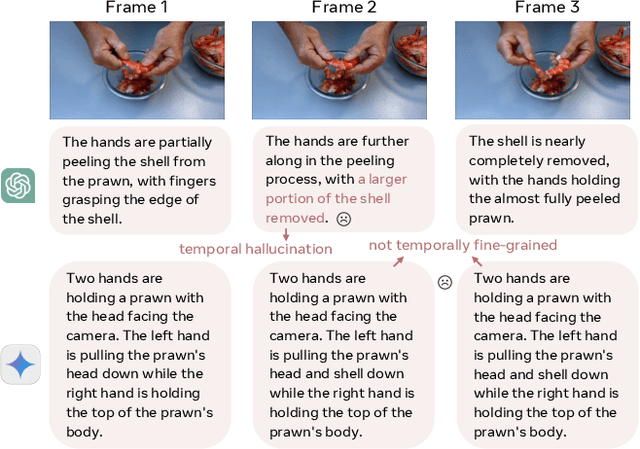
While image captioning provides isolated descriptions for individual images, and video captioning offers one single narrative for an entire video clip, our work explores an important middle ground: progress-aware video captioning at the frame level. This novel task aims to generate temporally fine-grained captions that not only accurately describe each frame but also capture the subtle progression of actions throughout a video sequence. Despite the strong capabilities of existing leading vision language models, they often struggle to discern the nuances of frame-wise differences. To address this, we propose ProgressCaptioner, a captioning model designed to capture the fine-grained temporal dynamics within an action sequence. Alongside, we develop the FrameCap dataset to support training and the FrameCapEval benchmark to assess caption quality. The results demonstrate that ProgressCaptioner significantly surpasses leading captioning models, producing precise captions that accurately capture action progression and set a new standard for temporal precision in video captioning. Finally, we showcase practical applications of our approach, specifically in aiding keyframe selection and advancing video understanding, highlighting its broad utility.
Propose, Assess, Search: Harnessing LLMs for Goal-Oriented Planning in Instructional Videos
Sep 30, 2024
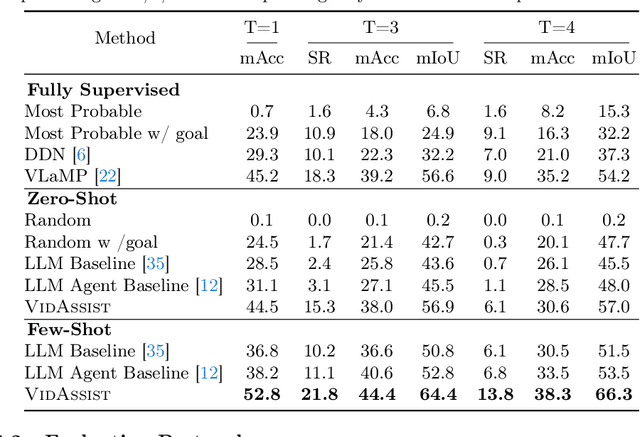
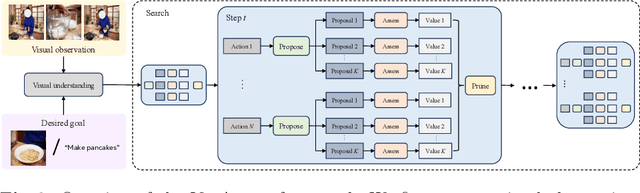
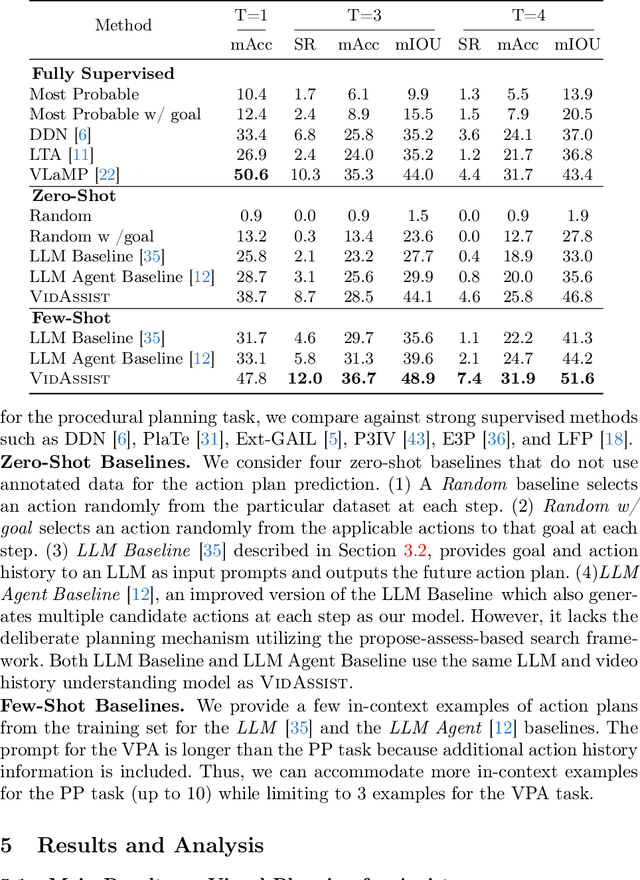
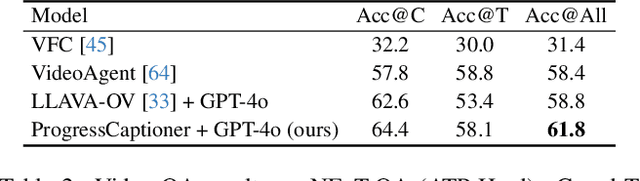
Goal-oriented planning, or anticipating a series of actions that transition an agent from its current state to a predefined objective, is crucial for developing intelligent assistants aiding users in daily procedural tasks. The problem presents significant challenges due to the need for comprehensive knowledge of temporal and hierarchical task structures, as well as strong capabilities in reasoning and planning. To achieve this, prior work typically relies on extensive training on the target dataset, which often results in significant dataset bias and a lack of generalization to unseen tasks. In this work, we introduce VidAssist, an integrated framework designed for zero/few-shot goal-oriented planning in instructional videos. VidAssist leverages large language models (LLMs) as both the knowledge base and the assessment tool for generating and evaluating action plans, thus overcoming the challenges of acquiring procedural knowledge from small-scale, low-diversity datasets. Moreover, VidAssist employs a breadth-first search algorithm for optimal plan generation, in which a composite of value functions designed for goal-oriented planning is utilized to assess the predicted actions at each step. Extensive experiments demonstrate that VidAssist offers a unified framework for different goal-oriented planning setups, e.g., visual planning for assistance (VPA) and procedural planning (PP), and achieves remarkable performance in zero-shot and few-shot setups. Specifically, our few-shot model outperforms the prior fully supervised state-of-the-art method by +7.7% in VPA and +4.81% PP task on the COIN dataset while predicting 4 future actions. Code, and models are publicly available at https://sites.google.com/view/vidassist.
GenRec: Unifying Video Generation and Recognition with Diffusion Models
Aug 27, 2024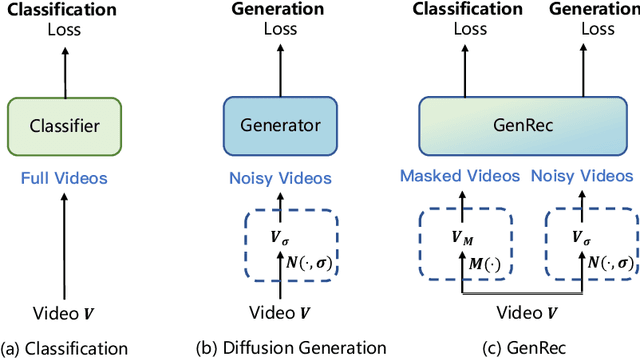
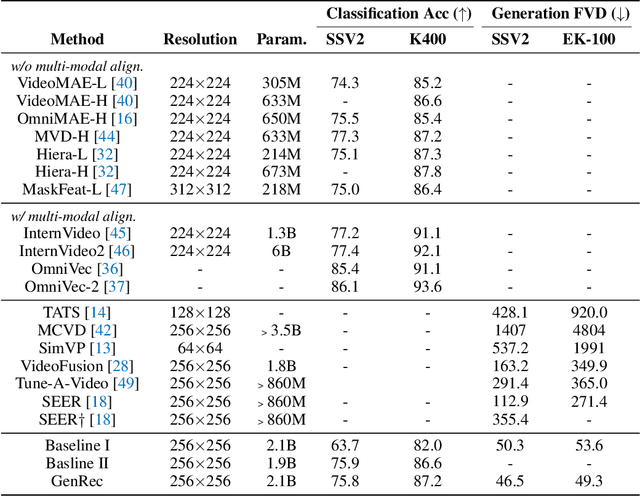
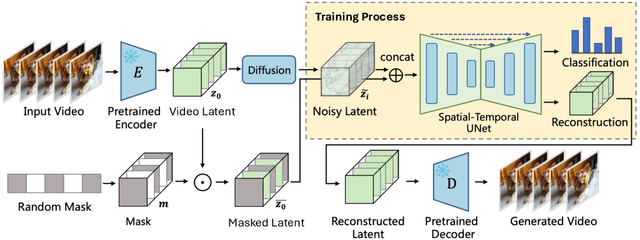
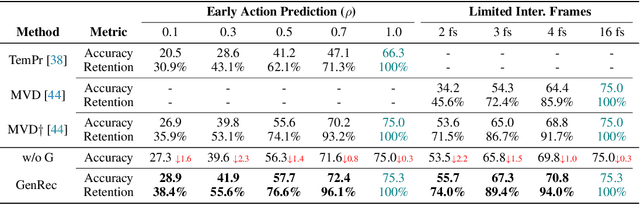
Video diffusion models are able to generate high-quality videos by learning strong spatial-temporal priors on large-scale datasets. In this paper, we aim to investigate whether such priors derived from a generative process are suitable for video recognition, and eventually joint optimization of generation and recognition. Building upon Stable Video Diffusion, we introduce GenRec, the first unified framework trained with a random-frame conditioning process so as to learn generalized spatial-temporal representations. The resulting framework can naturally supports generation and recognition, and more importantly is robust even when visual inputs contain limited information. Extensive experiments demonstrate the efficacy of GenRec for both recognition and generation. In particular, GenRec achieves competitive recognition performance, offering 75.8% and 87.2% accuracy on SSV2 and K400, respectively. GenRec also performs the best class-conditioned image-to-video generation results, achieving 46.5 and 49.3 FVD scores on SSV2 and EK-100 datasets. Furthermore, GenRec demonstrates extraordinary robustness in scenarios that only limited frames can be observed.
Unlocking Exocentric Video-Language Data for Egocentric Video Representation Learning
Aug 07, 2024We present EMBED (Egocentric Models Built with Exocentric Data), a method designed to transform exocentric video-language data for egocentric video representation learning. Large-scale exocentric data covers diverse activities with significant potential for egocentric learning, but inherent disparities between egocentric and exocentric data pose challenges in utilizing one view for the other seamlessly. Egocentric videos predominantly feature close-up hand-object interactions, whereas exocentric videos offer a broader perspective on human activities. Additionally, narratives in egocentric datasets are typically more action-centric and closely linked with the visual content, in contrast to the narrative styles found in exocentric datasets. To address these challenges, we employ a data transformation framework to adapt exocentric data for egocentric training, focusing on identifying specific video clips that emphasize hand-object interactions and transforming narration styles to align with egocentric perspectives. By applying both vision and language style transfer, our framework creates a new egocentric dataset derived from exocentric video-language data. Through extensive evaluations, we demonstrate the effectiveness of EMBED, achieving state-of-the-art results across various egocentric downstream tasks, including an absolute improvement of 4.7% on the Epic-Kitchens-100 multi-instance retrieval and 6.2% on the EGTEA classification benchmarks in zero-shot settings. Furthermore, EMBED enables egocentric video-language models to perform competitively in exocentric tasks. Finally, we showcase EMBED's application across various exocentric datasets, exhibiting strong generalization capabilities when applied to different exocentric datasets.
Video ReCap: Recursive Captioning of Hour-Long Videos
Feb 28, 2024



Most video captioning models are designed to process short video clips of few seconds and output text describing low-level visual concepts (e.g., objects, scenes, atomic actions). However, most real-world videos last for minutes or hours and have a complex hierarchical structure spanning different temporal granularities. We propose Video ReCap, a recursive video captioning model that can process video inputs of dramatically different lengths (from 1 second to 2 hours) and output video captions at multiple hierarchy levels. The recursive video-language architecture exploits the synergy between different video hierarchies and can process hour-long videos efficiently. We utilize a curriculum learning training scheme to learn the hierarchical structure of videos, starting from clip-level captions describing atomic actions, then focusing on segment-level descriptions, and concluding with generating summaries for hour-long videos. Furthermore, we introduce Ego4D-HCap dataset by augmenting Ego4D with 8,267 manually collected long-range video summaries. Our recursive model can flexibly generate captions at different hierarchy levels while also being useful for other complex video understanding tasks, such as VideoQA on EgoSchema. Data, code, and models are available at: https://sites.google.com/view/vidrecap
Ego-Exo4D: Understanding Skilled Human Activity from First- and Third-Person Perspectives
Nov 30, 2023



We present Ego-Exo4D, a diverse, large-scale multimodal multiview video dataset and benchmark challenge. Ego-Exo4D centers around simultaneously-captured egocentric and exocentric video of skilled human activities (e.g., sports, music, dance, bike repair). More than 800 participants from 13 cities worldwide performed these activities in 131 different natural scene contexts, yielding long-form captures from 1 to 42 minutes each and 1,422 hours of video combined. The multimodal nature of the dataset is unprecedented: the video is accompanied by multichannel audio, eye gaze, 3D point clouds, camera poses, IMU, and multiple paired language descriptions -- including a novel "expert commentary" done by coaches and teachers and tailored to the skilled-activity domain. To push the frontier of first-person video understanding of skilled human activity, we also present a suite of benchmark tasks and their annotations, including fine-grained activity understanding, proficiency estimation, cross-view translation, and 3D hand/body pose. All resources will be open sourced to fuel new research in the community.
Building an Open-Vocabulary Video CLIP Model with Better Architectures, Optimization and Data
Oct 08, 2023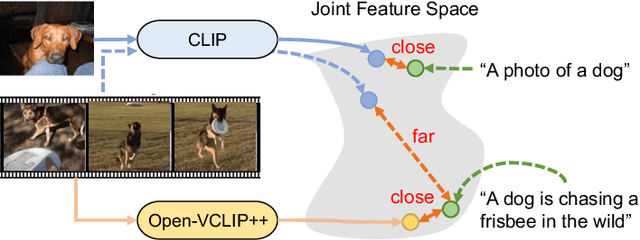
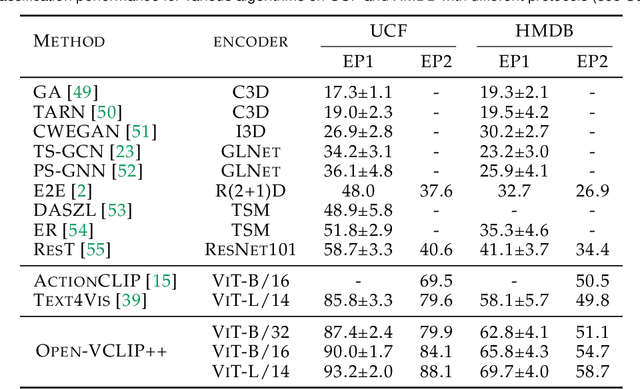

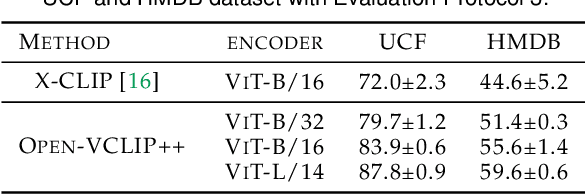
Despite significant results achieved by Contrastive Language-Image Pretraining (CLIP) in zero-shot image recognition, limited effort has been made exploring its potential for zero-shot video recognition. This paper presents Open-VCLIP++, a simple yet effective framework that adapts CLIP to a strong zero-shot video classifier, capable of identifying novel actions and events during testing. Open-VCLIP++ minimally modifies CLIP to capture spatial-temporal relationships in videos, thereby creating a specialized video classifier while striving for generalization. We formally demonstrate that training Open-VCLIP++ is tantamount to continual learning with zero historical data. To address this problem, we introduce Interpolated Weight Optimization, a technique that leverages the advantages of weight interpolation during both training and testing. Furthermore, we build upon large language models to produce fine-grained video descriptions. These detailed descriptions are further aligned with video features, facilitating a better transfer of CLIP to the video domain. Our approach is evaluated on three widely used action recognition datasets, following a variety of zero-shot evaluation protocols. The results demonstrate that our method surpasses existing state-of-the-art techniques by significant margins. Specifically, we achieve zero-shot accuracy scores of 88.1%, 58.7%, and 81.2% on UCF, HMDB, and Kinetics-600 datasets respectively, outpacing the best-performing alternative methods by 8.5%, 8.2%, and 12.3%. We also evaluate our approach on the MSR-VTT video-text retrieval dataset, where it delivers competitive video-to-text and text-to-video retrieval performance, while utilizing substantially less fine-tuning data compared to other methods. Code is released at https://github.com/wengzejia1/Open-VCLIP.
Towards Scalable Neural Representation for Diverse Videos
Mar 24, 2023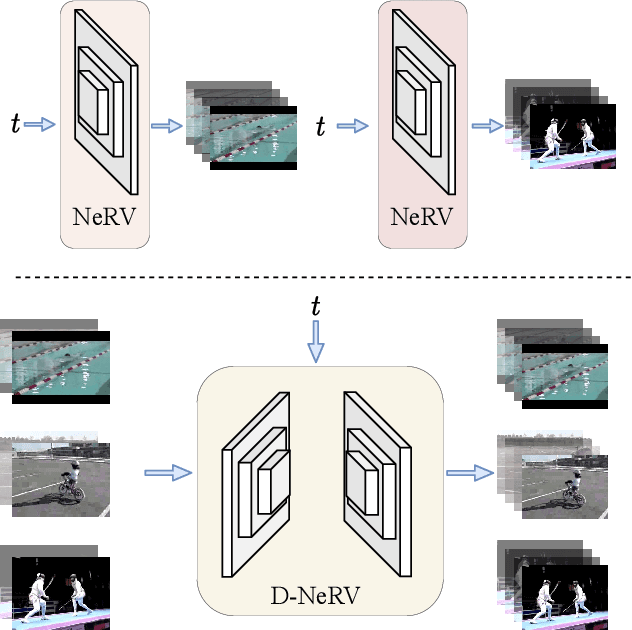
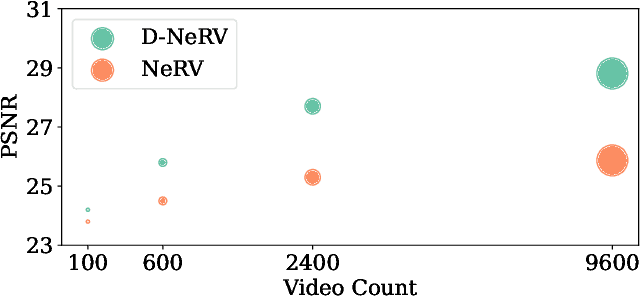
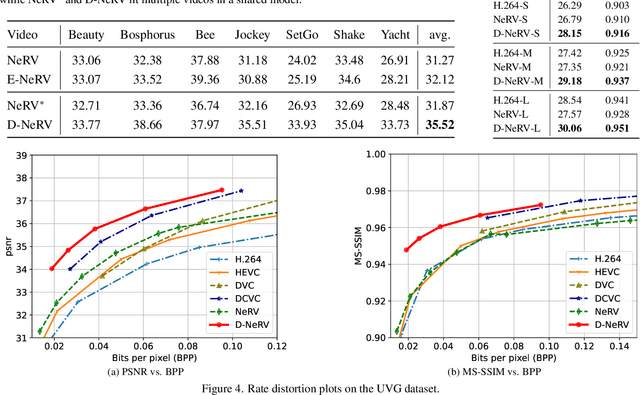
Implicit neural representations (INR) have gained increasing attention in representing 3D scenes and images, and have been recently applied to encode videos (e.g., NeRV, E-NeRV). While achieving promising results, existing INR-based methods are limited to encoding a handful of short videos (e.g., seven 5-second videos in the UVG dataset) with redundant visual content, leading to a model design that fits individual video frames independently and is not efficiently scalable to a large number of diverse videos. This paper focuses on developing neural representations for a more practical setup -- encoding long and/or a large number of videos with diverse visual content. We first show that instead of dividing videos into small subsets and encoding them with separate models, encoding long and diverse videos jointly with a unified model achieves better compression results. Based on this observation, we propose D-NeRV, a novel neural representation framework designed to encode diverse videos by (i) decoupling clip-specific visual content from motion information, (ii) introducing temporal reasoning into the implicit neural network, and (iii) employing the task-oriented flow as intermediate output to reduce spatial redundancies. Our new model largely surpasses NeRV and traditional video compression techniques on UCF101 and UVG datasets on the video compression task. Moreover, when used as an efficient data-loader, D-NeRV achieves 3%-10% higher accuracy than NeRV on action recognition tasks on the UCF101 dataset under the same compression ratios.
MINOTAUR: Multi-task Video Grounding From Multimodal Queries
Feb 16, 2023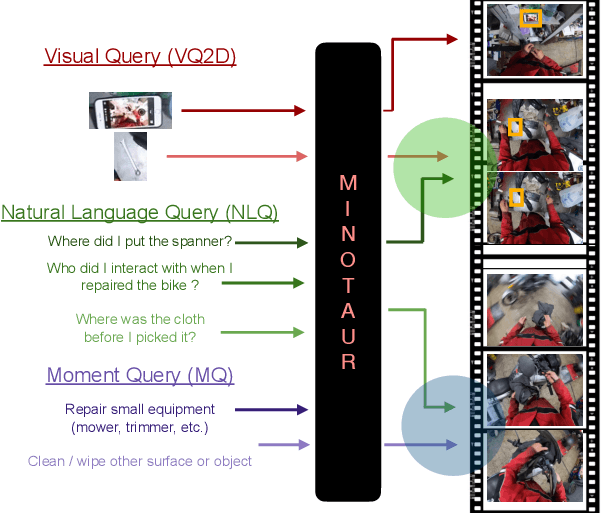

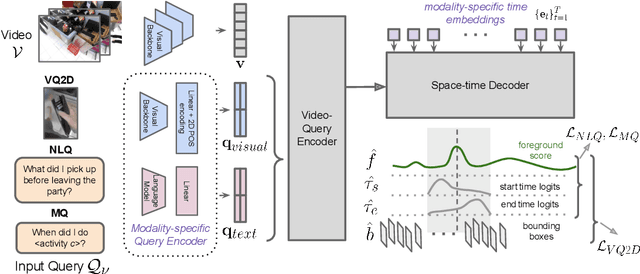
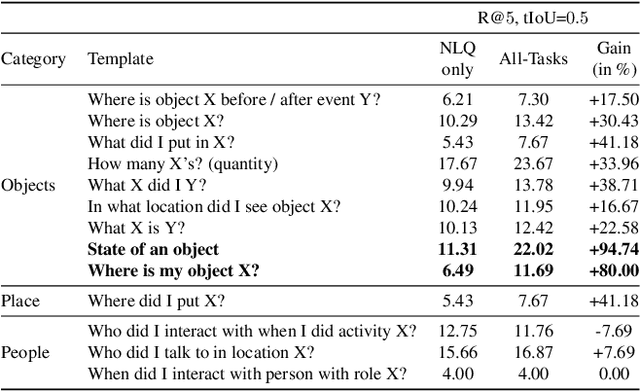
Video understanding tasks take many forms, from action detection to visual query localization and spatio-temporal grounding of sentences. These tasks differ in the type of inputs (only video, or video-query pair where query is an image region or sentence) and outputs (temporal segments or spatio-temporal tubes). However, at their core they require the same fundamental understanding of the video, i.e., the actors and objects in it, their actions and interactions. So far these tasks have been tackled in isolation with individual, highly specialized architectures, which do not exploit the interplay between tasks. In contrast, in this paper, we present a single, unified model for tackling query-based video understanding in long-form videos. In particular, our model can address all three tasks of the Ego4D Episodic Memory benchmark which entail queries of three different forms: given an egocentric video and a visual, textual or activity query, the goal is to determine when and where the answer can be seen within the video. Our model design is inspired by recent query-based approaches to spatio-temporal grounding, and contains modality-specific query encoders and task-specific sliding window inference that allow multi-task training with diverse input modalities and different structured outputs. We exhaustively analyze relationships among the tasks and illustrate that cross-task learning leads to improved performance on each individual task, as well as the ability to generalize to unseen tasks, such as zero-shot spatial localization of language queries.