 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniversalVTG: A Universal and Lightweight Foundation Model for Video Temporal Grounding
Apr 09, 2026Video temporal grounding (VTG) is typically tackled with dataset-specific models that transfer poorly across domains and query styles. Recent efforts to overcome this limitation have adapted large multimodal language models (MLLMs) to VTG, but their high compute cost and limited video context still hinder long-video grounding. We instead scale unified supervision while keeping the model lightweight. We present UniversalVTG, a single VTG model trained with large-scale cross-dataset pretraining. An offline Query Unifier canonicalizes heterogeneous query formats into a shared declarative space, reducing linguistic mismatch and preventing the negative transfer observed under naïve joint training. Combined with an efficient grounding head, UniversalVTG scales to long, untrimmed videos. Across diverse benchmarks-GoalStep-StepGrounding, Ego4D-NLQ, TACoS, Charades-STA, and ActivityNet-Captions-one UniversalVTG checkpoint achieves state-of-the-art performance versus dedicated VTG models. Moreover, despite being $>100\times$ smaller than recent MLLM-based approaches, UniversalVTG matches or exceeds their accuracy on multiple benchmarks, offering a practical alternative to parameter-heavy MLLMs.
HieraMamba: Video Temporal Grounding via Hierarchical Anchor-Mamba Pooling
Oct 27, 2025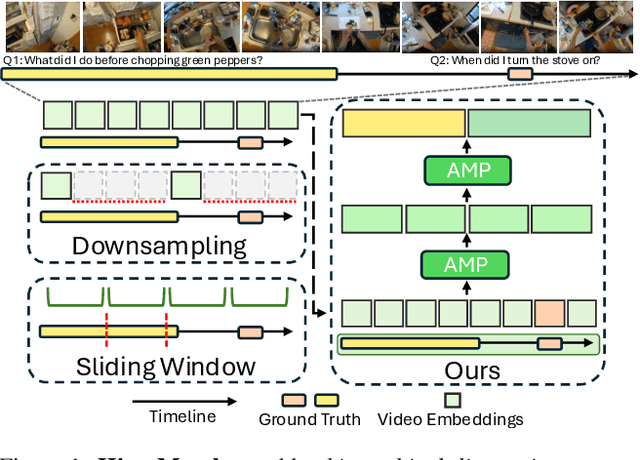
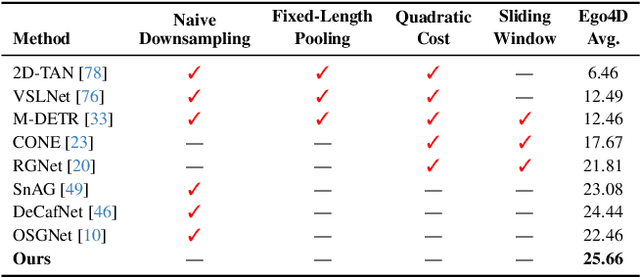
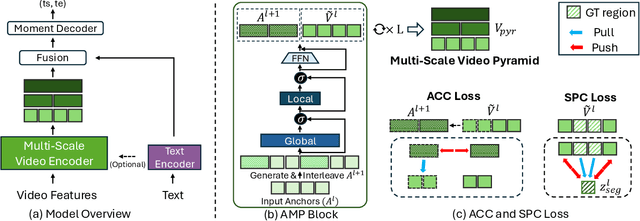
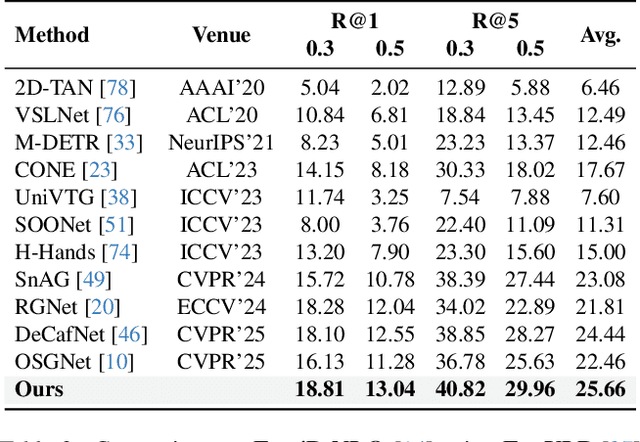
Video temporal grounding, the task of localizing the start and end times of a natural language query in untrimmed video, requires capturing both global context and fine-grained temporal detail. This challenge is particularly pronounced in long videos, where existing methods often compromise temporal fidelity by over-downsampling or relying on fixed windows. We present HieraMamba, a hierarchical architecture that preserves temporal structure and semantic richness across scales. At its core are Anchor-MambaPooling (AMP) blocks, which utilize Mamba's selective scanning to produce compact anchor tokens that summarize video content at multiple granularities. Two complementary objectives, anchor-conditioned and segment-pooled contrastive losses, encourage anchors to retain local detail while remaining globally discriminative. HieraMamba sets a new state-of-the-art on Ego4D-NLQ, MAD, and TACoS, demonstrating precise, temporally faithful localization in long, untrimmed videos.
Progress-Aware Video Frame Captioning
Dec 03, 2024
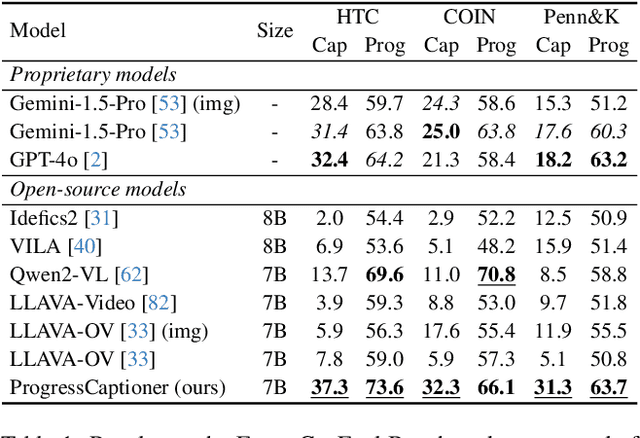
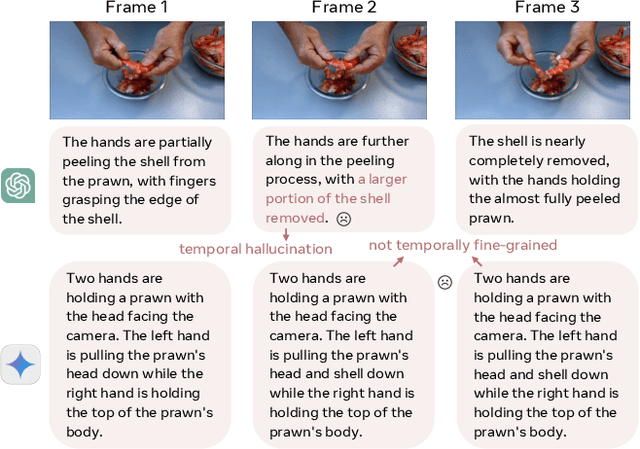
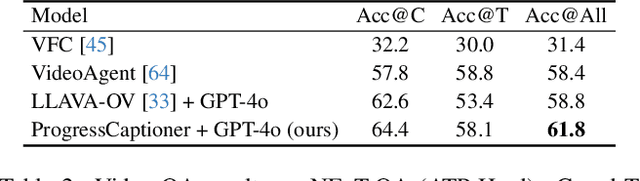
While image captioning provides isolated descriptions for individual images, and video captioning offers one single narrative for an entire video clip, our work explores an important middle ground: progress-aware video captioning at the frame level. This novel task aims to generate temporally fine-grained captions that not only accurately describe each frame but also capture the subtle progression of actions throughout a video sequence. Despite the strong capabilities of existing leading vision language models, they often struggle to discern the nuances of frame-wise differences. To address this, we propose ProgressCaptioner, a captioning model designed to capture the fine-grained temporal dynamics within an action sequence. Alongside, we develop the FrameCap dataset to support training and the FrameCapEval benchmark to assess caption quality. The results demonstrate that ProgressCaptioner significantly surpasses leading captioning models, producing precise captions that accurately capture action progression and set a new standard for temporal precision in video captioning. Finally, we showcase practical applications of our approach, specifically in aiding keyframe selection and advancing video understanding, highlighting its broad utility.
ActionSwitch: Class-agnostic Detection of Simultaneous Actions in Streaming Videos
Jul 17, 2024



Online Temporal Action Localization (On-TAL) is a critical task that aims to instantaneously identify action instances in untrimmed streaming videos as soon as an action concludes -- a major leap from frame-based Online Action Detection (OAD). Yet, the challenge of detecting overlapping actions is often overlooked even though it is a common scenario in streaming videos. Current methods that can address concurrent actions depend heavily on class information, limiting their flexibility. This paper introduces ActionSwitch, the first class-agnostic On-TAL framework capable of detecting overlapping actions. By obviating the reliance on class information, ActionSwitch provides wider applicability to various situations, including overlapping actions of the same class or scenarios where class information is unavailable. This approach is complemented by the proposed "conservativeness loss", which directly embeds a conservative decision-making principle into the loss function for On-TAL. Our ActionSwitch achieves state-of-the-art performance in complex datasets, including Epic-Kitchens 100 targeting the challenging egocentric view and FineAction consisting of fine-grained actions.
Object Aware Egocentric Online Action Detection
Jun 03, 2024



Advancements in egocentric video datasets like Ego4D, EPIC-Kitchens, and Ego-Exo4D have enriched the study of first-person human interactions, which is crucial for applications in augmented reality and assisted living. Despite these advancements, current Online Action Detection methods, which efficiently detect actions in streaming videos, are predominantly designed for exocentric views and thus fail to capitalize on the unique perspectives inherent to egocentric videos. To address this gap, we introduce an Object-Aware Module that integrates egocentric-specific priors into existing OAD frameworks, enhancing first-person footage interpretation. Utilizing object-specific details and temporal dynamics, our module improves scene understanding in detecting actions. Validated extensively on the Epic-Kitchens 100 dataset, our work can be seamlessly integrated into existing models with minimal overhead and bring consistent performance enhancements, marking an important step forward in adapting action detection systems to egocentric video analysis.
DATa: Domain Adaptation-Aided Deep Table Detection Using Visual-Lexical Representations
Nov 12, 2022



Considerable research attention has been paid to table detection by developing not only rule-based approaches reliant on hand-crafted heuristics but also deep learning approaches. Although recent studies successfully perform table detection with enhanced results, they often experience performance degradation when they are used for transferred domains whose table layout features might differ from the source domain in which the underlying model has been trained. To overcome this problem, we present DATa, a novel Domain Adaptation-aided deep Table detection method that guarantees satisfactory performance in a specific target domain where few trusted labels are available. To this end, we newly design lexical features and an augmented model used for re-training. More specifically, after pre-training one of state-of-the-art vision-based models as our backbone network, we re-train our augmented model, consisting of the vision-based model and the multilayer perceptron (MLP) architecture. Using new confidence scores acquired based on the trained MLP architecture as well as an initial prediction of bounding boxes and their confidence scores, we calculate each confidence score more accurately. To validate the superiority of DATa, we perform experimental evaluations by adopting a real-world benchmark dataset in a source domain and another dataset in our target domain consisting of materials science articles. Experimental results demonstrate that the proposed DATa method substantially outperforms competing methods that only utilize visual representations in the target domain. Such gains are possible owing to the capability of eliminating high false positives or false negatives according to the setting of a confidence score threshold.
Soft-Landing Strategy for Alleviating the Task Discrepancy Problem in Temporal Action Localization Tasks
Nov 11, 2022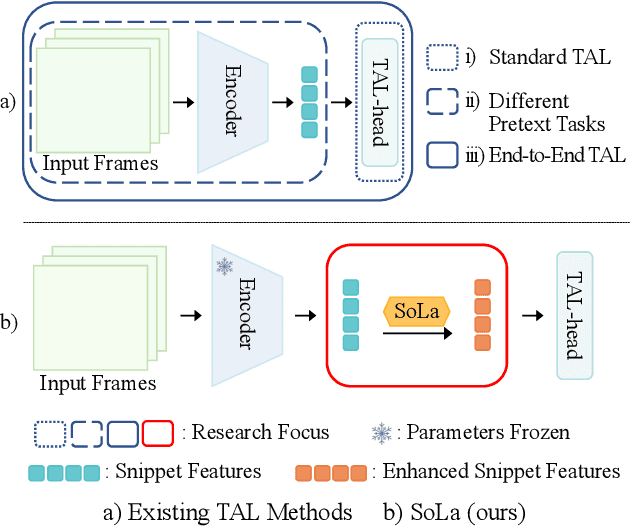
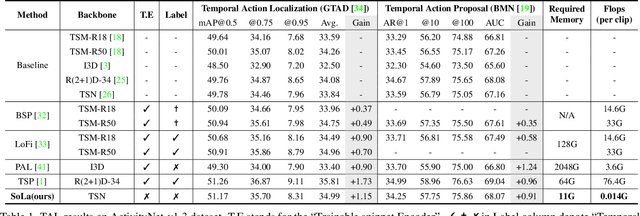
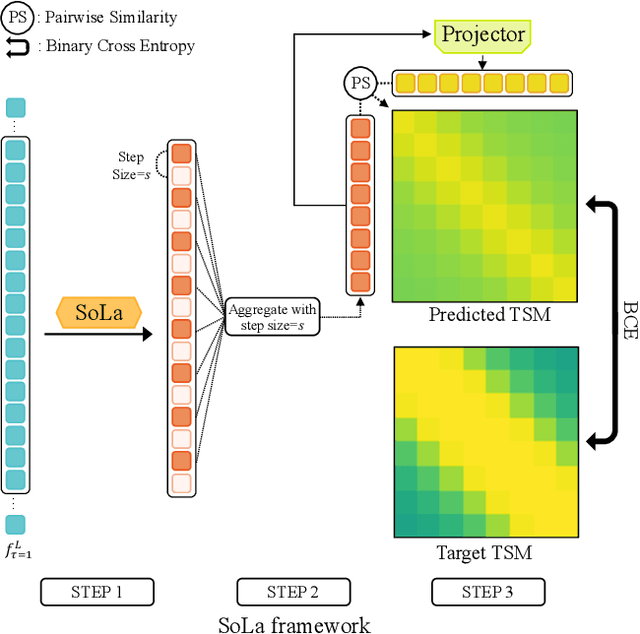
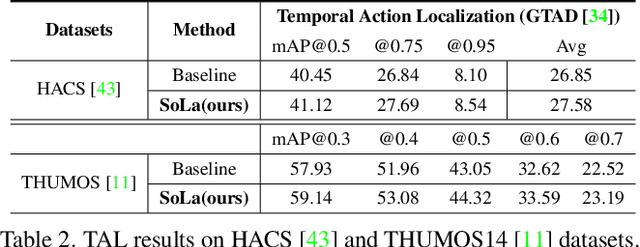
Temporal Action Localization (TAL) methods typically operate on top of feature sequences from a frozen snippet encoder that is pretrained with the Trimmed Action Classification (TAC) tasks, resulting in a task discrepancy problem. While existing TAL methods mitigate this issue either by retraining the encoder with a pretext task or by end-to-end fine-tuning, they commonly require an overload of high memory and computation. In this work, we introduce Soft-Landing (SoLa) strategy, an efficient yet effective framework to bridge the transferability gap between the pretrained encoder and the downstream tasks by incorporating a light-weight neural network, i.e., a SoLa module, on top of the frozen encoder. We also propose an unsupervised training scheme for the SoLa module; it learns with inter-frame Similarity Matching that uses the frame interval as its supervisory signal, eliminating the need for temporal annotations. Experimental evaluation on various benchmarks for downstream TAL tasks shows that our method effectively alleviates the task discrepancy problem with remarkable computational efficiency.