 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Granular Spatio-Temporal Token Merging for Training-Free Acceleration of Video LLMs
Jul 10, 2025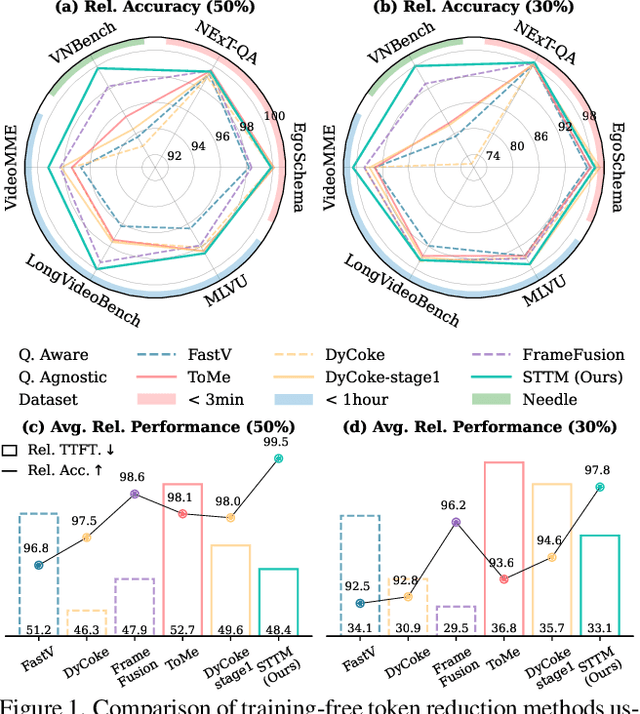

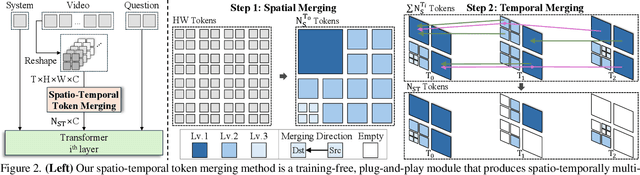

Video large language models (LLMs) achieve strong video understanding by leveraging a large number of spatio-temporal tokens, but suffer from quadratic computational scaling with token count. To address this, we propose a training-free spatio-temporal token merging method, named STTM. Our key insight is to exploit local spatial and temporal redundancy in video data which has been overlooked in prior work. STTM first transforms each frame into multi-granular spatial tokens using a coarse-to-fine search over a quadtree structure, then performs directed pairwise merging across the temporal dimension. This decomposed merging approach outperforms existing token reduction methods across six video QA benchmarks. Notably, STTM achieves a 2$\times$ speed-up with only a 0.5% accuracy drop under a 50% token budget, and a 3$\times$ speed-up with just a 2% drop under a 30% budget. Moreover, STTM is query-agnostic, allowing KV cache reuse across different questions for the same video. The project page is available at https://www.jshyun.me/projects/sttm.
ActionSwitch: Class-agnostic Detection of Simultaneous Actions in Streaming Videos
Jul 17, 2024



Online Temporal Action Localization (On-TAL) is a critical task that aims to instantaneously identify action instances in untrimmed streaming videos as soon as an action concludes -- a major leap from frame-based Online Action Detection (OAD). Yet, the challenge of detecting overlapping actions is often overlooked even though it is a common scenario in streaming videos. Current methods that can address concurrent actions depend heavily on class information, limiting their flexibility. This paper introduces ActionSwitch, the first class-agnostic On-TAL framework capable of detecting overlapping actions. By obviating the reliance on class information, ActionSwitch provides wider applicability to various situations, including overlapping actions of the same class or scenarios where class information is unavailable. This approach is complemented by the proposed "conservativeness loss", which directly embeds a conservative decision-making principle into the loss function for On-TAL. Our ActionSwitch achieves state-of-the-art performance in complex datasets, including Epic-Kitchens 100 targeting the challenging egocentric view and FineAction consisting of fine-grained actions.
Exploring Scalability of Self-Training for Open-Vocabulary Temporal Action Localization
Jul 09, 2024The vocabulary size in temporal action localization (TAL) is constrained by the scarcity of large-scale annotated datasets. To address this, recent works incorporate powerful pre-trained vision-language models (VLMs), such as CLIP, to perform open-vocabulary TAL (OV-TAL). However, unlike VLMs trained on extensive image/video-text pairs, existing OV-TAL methods still rely on small, fully labeled TAL datasets for training an action localizer. In this paper, we explore the scalability of self-training with unlabeled YouTube videos for OV-TAL. Our self-training approach consists of two stages. First, a class-agnostic action localizer is trained on a human-labeled TAL dataset and used to generate pseudo-labels for unlabeled videos. Second, the large-scale pseudo-labeled dataset is combined with the human-labeled dataset to train the localizer. Extensive experiments demonstrate that leveraging web-scale videos in self-training significantly enhances the generalizability of an action localizer. Additionally, we highlighted issues with existing OV-TAL evaluation schemes and proposed a new evaluation protocol. Code is released at https://github.com/HYUNJS/STOV-TAL
AAM-VDT: Vehicle Digital Twin for Tele-Operations in Advanced Air Mobility
Apr 15, 2024



This study advanced tele-operations in Advanced Air Mobility (AAM) through the creation of a Vehicle Digital Twin (VDT) system for eVTOL aircraft, tailored to enhance remote control safety and efficiency, especially for Beyond Visual Line of Sight (BVLOS) operations. By synergizing digital twin technology with immersive Virtual Reality (VR) interfaces, we notably elevate situational awareness and control precision for remote operators. Our VDT framework integrates immersive tele-operation with a high-fidelity aerodynamic database, essential for authentically simulating flight dynamics and control tactics. At the heart of our methodology lies an eVTOL's high-fidelity digital replica, placed within a simulated reality that accurately reflects physical laws, enabling operators to manage the aircraft via a master-slave dynamic, substantially outperforming traditional 2D interfaces. The architecture of the designed system ensures seamless interaction between the operator, the digital twin, and the actual aircraft, facilitating exact, instantaneous feedback. Experimental assessments, involving propulsion data gathering, simulation database fidelity verification, and tele-operation testing, verify the system's capability in precise control command transmission and maintaining the digital-physical eVTOL synchronization. Our findings underscore the VDT system's potential in augmenting AAM efficiency and safety, paving the way for broader digital twin application in autonomous aerial vehicles.
A Generalized Framework for Video Instance Segmentation
Nov 16, 2022



Recently, handling long videos of complex and occluded sequences has emerged as a new challenge in the video instance segmentation (VIS) community. However, existing methods show limitations in addressing the challenge. We argue that the biggest bottleneck in current approaches is the discrepancy between the training and the inference. To effectively bridge the gap, we propose a \textbf{Gen}eralized framework for \textbf{VIS}, namely \textbf{GenVIS}, that achieves the state-of-the-art performance on challenging benchmarks without designing complicated architectures or extra post-processing. The key contribution of GenVIS is the learning strategy. Specifically, we propose a query-based training pipeline for sequential learning, using a novel target label assignment strategy. To further fill the remaining gaps, we introduce a memory that effectively acquires information from previous states. Thanks to the new perspective, which focuses on building relationships between separate frames or clips, GenVIS can be flexibly executed in both online and semi-online manner. We evaluate our methods on popular VIS benchmarks, YouTube-VIS 2019/2021/2022 and Occluded VIS (OVIS), achieving state-of-the-art results. Notably, we greatly outperform the state-of-the-art on the long VIS benchmark (OVIS), improving 5.6 AP with ResNet-50 backbone. Code will be available at https://github.com/miranheo/GenVIS.
Detection Recovery in Online Multi-Object Tracking with Sparse Graph Tracker
May 02, 2022



Joint object detection and online multi-object tracking (JDT) methods have been proposed recently to achieve one-shot tracking. Yet, existing works overlook the importance of detection itself and often result in missed detections when confronted by occlusions or motion blurs. The missed detections affect not only detection performance but also tracking performance due to inconsistent tracklets. Hence, we propose a new JDT model that recovers the missed detections while associating the detection candidates of consecutive frames by learning object-level spatio-temporal consistency through edge features in a Graph Neural Network (GNN). Our proposed model Sparse Graph Tracker (SGT) converts video data into a graph, where the nodes are top-$K$ scored detection candidates, and the edges are relations between the nodes at different times, such as position difference and visual similarity. Two nodes are connected if they are close in either a Euclidean or feature space, generating a sparsely connected graph. Without motion prediction or Re-Identification (ReID), the association is performed by predicting an edge score representing the probability that two connected nodes refer to the same object. Under the online setting, our SGT achieves state-of-the-art (SOTA) on the MOT17/20 Detection and MOT16/20 benchmarks in terms of AP and MOTA, respectively. Especially, SGT surpasses the previous SOTA on the crowded dataset MOT20 where partial occlusion cases are dominant, showing the effectiveness of detection recovery against partial occlusion. Code will be released at https://github.com/HYUNJS/SGT.