 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Temporally Dynamic Data Augmentation for Video Recognition
Jun 30, 2022
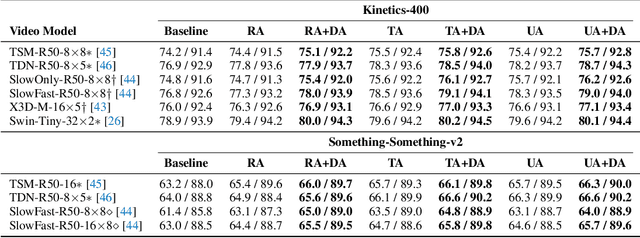
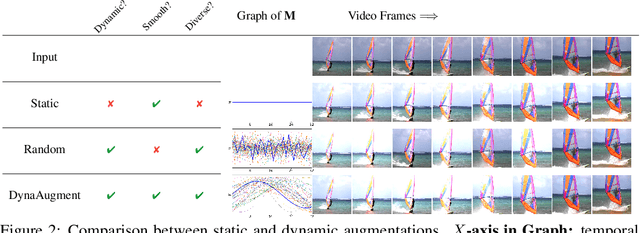

Data augmentation has recently emerged as an essential component of modern training recipes for visual recognition tasks. However, data augmentation for video recognition has been rarely explored despite its effectiveness. Few existing augmentation recipes for video recognition naively extend the image augmentation methods by applying the same operations to the whole video frames. Our main idea is that the magnitude of augmentation operations for each frame needs to be changed over time to capture the real-world video's temporal variations. These variations should be generated as diverse as possible using fewer additional hyper-parameters during training. Through this motivation, we propose a simple yet effective video data augmentation framework, DynaAugment. The magnitude of augmentation operations on each frame is changed by an effective mechanism, Fourier Sampling that parameterizes diverse, smooth, and realistic temporal variations. DynaAugment also includes an extended search space suitable for video for automatic data augmentation methods. DynaAugment experimentally demonstrates that there are additional performance rooms to be improved from static augmentations on diverse video models. Specifically, we show the effectiveness of DynaAugment on various video datasets and tasks: large-scale video recognition (Kinetics-400 and Something-Something-v2), small-scale video recognition (UCF- 101 and HMDB-51), fine-grained video recognition (Diving-48 and FineGym), video action segmentation on Breakfast, video action localization on THUMOS'14, and video object detection on MOT17Det. DynaAugment also enables video models to learn more generalized representation to improve the model robustness on the corrupted videos.
Detection Recovery in Online Multi-Object Tracking with Sparse Graph Tracker
May 02, 2022



Joint object detection and online multi-object tracking (JDT) methods have been proposed recently to achieve one-shot tracking. Yet, existing works overlook the importance of detection itself and often result in missed detections when confronted by occlusions or motion blurs. The missed detections affect not only detection performance but also tracking performance due to inconsistent tracklets. Hence, we propose a new JDT model that recovers the missed detections while associating the detection candidates of consecutive frames by learning object-level spatio-temporal consistency through edge features in a Graph Neural Network (GNN). Our proposed model Sparse Graph Tracker (SGT) converts video data into a graph, where the nodes are top-$K$ scored detection candidates, and the edges are relations between the nodes at different times, such as position difference and visual similarity. Two nodes are connected if they are close in either a Euclidean or feature space, generating a sparsely connected graph. Without motion prediction or Re-Identification (ReID), the association is performed by predicting an edge score representing the probability that two connected nodes refer to the same object. Under the online setting, our SGT achieves state-of-the-art (SOTA) on the MOT17/20 Detection and MOT16/20 benchmarks in terms of AP and MOTA, respectively. Especially, SGT surpasses the previous SOTA on the crowded dataset MOT20 where partial occlusion cases are dominant, showing the effectiveness of detection recovery against partial occlusion. Code will be released at https://github.com/HYUNJS/SGT.