 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMoRGS: Efficient Per-Gaussian Motion Reasoning for Streamable Dynamic 3D Scenes
Mar 26, 2026Online reconstruction of dynamic scenes aims to learn from streaming multi-view inputs under low-latency constraints. The fast training and real-time rendering capabilities of 3D Gaussian Splatting have made on-the-fly reconstruction practically feasible, enabling online 4D reconstruction. However, existing online approaches, despite their efficiency and visual quality, fail to learn per-Gaussian motion that reflects true scene dynamics. Without explicit motion cues, appearance and motion are optimized solely under photometric loss, causing per-Gaussian motion to chase pixel residuals rather than true 3D motion. To address this, we propose MoRGS, an efficient online per-Gaussian motion reasoning framework that explicitly models per-Gaussian motion to improve 4D reconstruction quality. Specifically, we leverage optical flow on a sparse set of key views as lightweight motion cues that regularize per-Gaussian motion beyond photometric supervision. To compensate for the sparsity of flow supervision, we learn a per-Gaussian motion offset field that reconciles discrepancies between projected 3D motion and observed flow across views and time. In addition, we introduce a per-Gaussian motion confidence that separates dynamic from static Gaussians and weights Gaussian attribute residual updates, thereby suppressing redundant motion in static regions for better temporal consistency and accelerating the modeling of large motions. Extensive experiments demonstrate that MoRGS achieves state-of-the-art reconstruction quality and motion fidelity among online methods, while maintaining streamable performance.
Revisiting Weakly-Supervised Video Scene Graph Generation via Pair Affinity Learning
Mar 23, 2026Weakly-supervised video scene graph generation (WS-VSGG) aims to parse video content into structured relational triplets without bounding box annotations and with only sparse temporal labeling, significantly reducing annotation costs. Without ground-truth bounding boxes, these methods rely on off-the-shelf detectors to generate object proposals, yet largely overlook a fundamental discrepancy from fullysupervised pipelines. Fully-supervised detectors implicitly filter out noninteractive objects, while off-the-shelf detectors indiscriminately detect all visible objects, overwhelming relation models with noisy pairs.We address this by introducing a learnable pair affinity that estimates the likelihood of interaction between subject-object pairs. Through Pair Affinity Learning and Scoring (PALS), pair affinity is incorporated into inferencetime ranking and further integrated into contextual reasoning through Pair Affinity Modulation (PAM), enabling the model to suppress noninteractive pairs and focus on relationally meaningful ones. To provide cleaner supervision for pair affinity learning, we further propose Relation- Aware Matching (RAM), which leverages vision-language grounding to resolve class-level ambiguity in pseudo-label generation. Extensive experiments on Action Genome demonstrate that our approach consistently yields substantial improvements across different baselines and backbones, achieving state-of-the-art WS-VSGG performance.
MonoCLUE : Object-Aware Clustering Enhances Monocular 3D Object Detection
Nov 11, 2025Monocular 3D object detection offers a cost-effective solution for autonomous driving but suffers from ill-posed depth and limited field of view. These constraints cause a lack of geometric cues and reduced accuracy in occluded or truncated scenes. While recent approaches incorporate additional depth information to address geometric ambiguity, they overlook the visual cues crucial for robust recognition. We propose MonoCLUE, which enhances monocular 3D detection by leveraging both local clustering and generalized scene memory of visual features. First, we perform K-means clustering on visual features to capture distinct object-level appearance parts (e.g., bonnet, car roof), improving detection of partially visible objects. The clustered features are propagated across regions to capture objects with similar appearances. Second, we construct a generalized scene memory by aggregating clustered features across images, providing consistent representations that generalize across scenes. This improves object-level feature consistency, enabling stable detection across varying environments. Lastly, we integrate both local cluster features and generalized scene memory into object queries, guiding attention toward informative regions. Exploiting a unified local clustering and generalized scene memory strategy, MonoCLUE enables robust monocular 3D detection under occlusion and limited visibility, achieving state-of-the-art performance on the KITTI benchmark.
DualFocus: Depth from Focus with Spatio-Focal Dual Variational Constraints
Sep 26, 2025Depth-from-Focus (DFF) enables precise depth estimation by analyzing focus cues across a stack of images captured at varying focal lengths. While recent learning-based approaches have advanced this field, they often struggle in complex scenes with fine textures or abrupt depth changes, where focus cues may become ambiguous or misleading. We present DualFocus, a novel DFF framework that leverages the focal stack's unique gradient patterns induced by focus variation, jointly modeling focus changes over spatial and focal dimensions. Our approach introduces a variational formulation with dual constraints tailored to DFF: spatial constraints exploit gradient pattern changes across focus levels to distinguish true depth edges from texture artifacts, while focal constraints enforce unimodal, monotonic focus probabilities aligned with physical focus behavior. These inductive biases improve robustness and accuracy in challenging regions. Comprehensive experiments on four public datasets demonstrate that DualFocus consistently outperforms state-of-the-art methods in both depth accuracy and perceptual quality.
GenCLIP: Generalizing CLIP Prompts for Zero-shot Anomaly Detection
Apr 21, 2025Zero-shot anomaly detection (ZSAD) aims to identify anomalies in unseen categories by leveraging CLIP's zero-shot capabilities to match text prompts with visual features. A key challenge in ZSAD is learning general prompts stably and utilizing them effectively, while maintaining both generalizability and category specificity. Although general prompts have been explored in prior works, achieving their stable optimization and effective deployment remains a significant challenge. In this work, we propose GenCLIP, a novel framework that learns and leverages general prompts more effectively through multi-layer prompting and dual-branch inference. Multi-layer prompting integrates category-specific visual cues from different CLIP layers, enriching general prompts with more comprehensive and robust feature representations. By combining general prompts with multi-layer visual features, our method further enhances its generalization capability. To balance specificity and generalization, we introduce a dual-branch inference strategy, where a vision-enhanced branch captures fine-grained category-specific features, while a query-only branch prioritizes generalization. The complementary outputs from both branches improve the stability and reliability of anomaly detection across unseen categories. Additionally, we propose an adaptive text prompt filtering mechanism, which removes irrelevant or atypical class names not encountered during CLIP's training, ensuring that only meaningful textual inputs contribute to the final vision-language alignment.
CoMoGaussian: Continuous Motion-Aware Gaussian Splatting from Motion-Blurred Images
Mar 07, 20253D Gaussian Splatting (3DGS) has gained significant attention for their high-quality novel view rendering, motivating research to address real-world challenges. A critical issue is the camera motion blur caused by movement during exposure, which hinders accurate 3D scene reconstruction. In this study, we propose CoMoGaussian, a Continuous Motion-Aware Gaussian Splatting that reconstructs precise 3D scenes from motion-blurred images while maintaining real-time rendering speed. Considering the complex motion patterns inherent in real-world camera movements, we predict continuous camera trajectories using neural ordinary differential equations (ODEs). To ensure accurate modeling, we employ rigid body transformations, preserving the shape and size of the object but rely on the discrete integration of sampled frames. To better approximate the continuous nature of motion blur, we introduce a continuous motion refinement (CMR) transformation that refines rigid transformations by incorporating additional learnable parameters. By revisiting fundamental camera theory and leveraging advanced neural ODE techniques, we achieve precise modeling of continuous camera trajectories, leading to improved reconstruction accuracy. Extensive experiments demonstrate state-of-the-art performance both quantitatively and qualitatively on benchmark datasets, which include a wide range of motion blur scenarios, from moderate to extreme blur.
Find First, Track Next: Decoupling Identification and Propagation in Referring Video Object Segmentation
Mar 05, 2025



Referring video object segmentation aims to segment and track a target object in a video using a natural language prompt. Existing methods typically fuse visual and textual features in a highly entangled manner, processing multi-modal information together to generate per-frame masks. However, this approach often struggles with ambiguous target identification, particularly in scenes with multiple similar objects, and fails to ensure consistent mask propagation across frames. To address these limitations, we introduce FindTrack, a novel decoupled framework that separates target identification from mask propagation. FindTrack first adaptively selects a key frame by balancing segmentation confidence and vision-text alignment, establishing a robust reference for the target object. This reference is then utilized by a dedicated propagation module to track and segment the object across the entire video. By decoupling these processes, FindTrack effectively reduces ambiguities in target association and enhances segmentation consistency. We demonstrate that FindTrack outperforms existing methods on public benchmarks.
CoCoGaussian: Leveraging Circle of Confusion for Gaussian Splatting from Defocused Images
Dec 20, 2024



3D Gaussian Splatting (3DGS) has attracted significant attention for its high-quality novel view rendering, inspiring research to address real-world challenges. While conventional methods depend on sharp images for accurate scene reconstruction, real-world scenarios are often affected by defocus blur due to finite depth of field, making it essential to account for realistic 3D scene representation. In this study, we propose CoCoGaussian, a Circle of Confusion-aware Gaussian Splatting that enables precise 3D scene representation using only defocused images. CoCoGaussian addresses the challenge of defocus blur by modeling the Circle of Confusion (CoC) through a physically grounded approach based on the principles of photographic defocus. Exploiting 3D Gaussians, we compute the CoC diameter from depth and learnable aperture information, generating multiple Gaussians to precisely capture the CoC shape. Furthermore, we introduce a learnable scaling factor to enhance robustness and provide more flexibility in handling unreliable depth in scenes with reflective or refractive surfaces. Experiments on both synthetic and real-world datasets demonstrate that CoCoGaussian achieves state-of-the-art performance across multiple benchmarks.
Elevating Flow-Guided Video Inpainting with Reference Generation
Dec 12, 2024
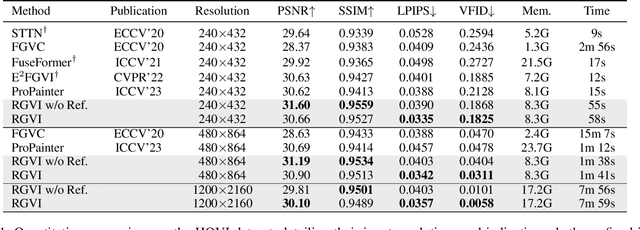
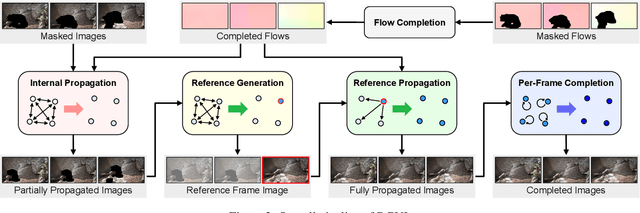
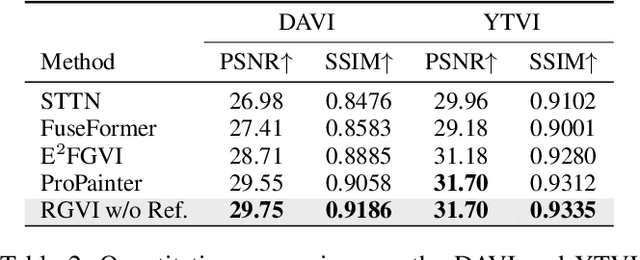
Video inpainting (VI) is a challenging task that requires effective propagation of observable content across frames while simultaneously generating new content not present in the original video. In this study, we propose a robust and practical VI framework that leverages a large generative model for reference generation in combination with an advanced pixel propagation algorithm. Powered by a strong generative model, our method not only significantly enhances frame-level quality for object removal but also synthesizes new content in the missing areas based on user-provided text prompts. For pixel propagation, we introduce a one-shot pixel pulling method that effectively avoids error accumulation from repeated sampling while maintaining sub-pixel precision. To evaluate various VI methods in realistic scenarios, we also propose a high-quality VI benchmark, HQVI, comprising carefully generated videos using alpha matte composition. On public benchmarks and the HQVI dataset, our method demonstrates significantly higher visual quality and metric scores compared to existing solutions. Furthermore, it can process high-resolution videos exceeding 2K resolution with ease, underscoring its superiority for real-world applications.
STATIC : Surface Temporal Affine for TIme Consistency in Video Monocular Depth Estimation
Dec 02, 2024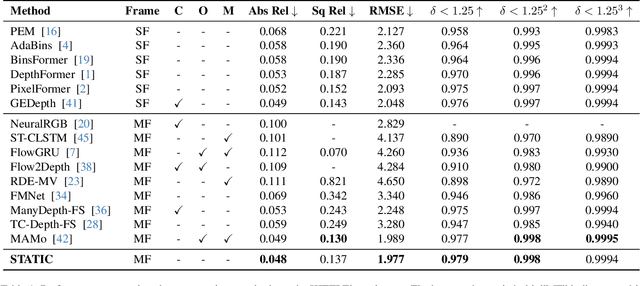


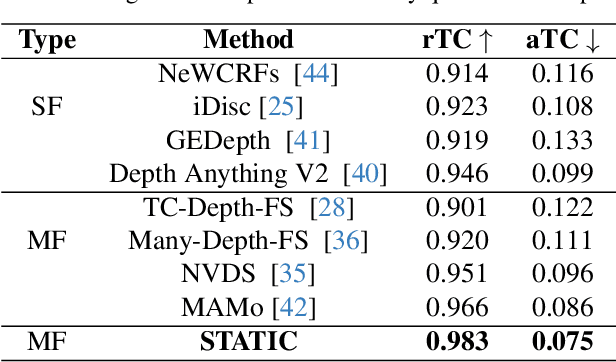
Video monocular depth estimation is essential for applications such as autonomous driving, AR/VR, and robotics. Recent transformer-based single-image monocular depth estimation models perform well on single images but struggle with depth consistency across video frames. Traditional methods aim to improve temporal consistency using multi-frame temporal modules or prior information like optical flow and camera parameters. However, these approaches face issues such as high memory use, reduced performance with dynamic or irregular motion, and limited motion understanding. We propose STATIC, a novel model that independently learns temporal consistency in static and dynamic area without additional information. A difference mask from surface normals identifies static and dynamic area by measuring directional variance. For static area, the Masked Static (MS) module enhances temporal consistency by focusing on stable regions. For dynamic area, the Surface Normal Similarity (SNS) module aligns areas and enhances temporal consistency by measuring feature similarity between frames. A final refinement integrates the independently learned static and dynamic area, enabling STATIC to achieve temporal consistency across the entire sequence. Our method achieves state-of-the-art video depth estimation on the KITTI and NYUv2 datasets without additional information.