 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Analysis Focused on Womens Safety: Can VAD Models Be Enhanced by a Multi-modal Dataset?
May 25, 2026Women's safety and security are paramount for a modern society. Crimes against women occur in daylight as well as in low-light conditions. Often, such events are captured through real-world surveillance cameras that operate at lower resolutions. Despite substantial progress in CV-related research, video anomaly detection (VAD) focused on women's safety has not yet been adequately addressed. Existing video anomaly datasets contain well-lit, high-resolution, close-shot videos, and fail to represent women-centric anomalies such as chain snatching, stalking, inappropriate touch, and other subtle forms of crime against women. To address these problems, we propose the ExtrAnom dataset, a new multi-modal benchmark containing 1001 videos with textual descriptions, 500 normal and 501 anomalous, classified into 5 different types of women-centric crimes. The dataset comprises low-light (8%), low-resolution videos (13%), long-shot (15%), along with daylight (64%) anomalous videos. And it covers anomalous events like stalking (3.9%), chain snatching (17.6%), kidnapping (7.3%), assassinations (2.3%), harassment (18.9%), and normal (50%). Each video is supplemented with 4 textual annotations, including one human-generated and three LLM-generated descriptions, enabling cross-modal and VLM-based validations. The aim of creating a women-centric dataset is to accurately detect the women-centric anomaly patterns, which are possible to observe visually. The dataset supplements the VLMs to accurately generate video-level descriptions. ExtrAnom has been benchmarked against popular unimodal and multi-modal VAD datasets (e.g., XD-Violence, UCF-Crime, and UCA) and SOTA methods. Experiments reveal that the existing datasets are insufficient to train models for detecting women-centric anomalies.
OTT-Vid: Optimal Transport Temporal Token Compression for Video Large Language Models
May 12, 2026As Video Large Language Models (Video-LLMs) scale to longer and more complex videos, their inference cost grows rapidly due to the large volume of visual tokens accumulated across frames. Training-free token compression has emerged as a practical solution to this bottleneck. However, existing temporal compression methods rely primarily on cross-frame token similarity or segmentation heuristics, overlooking each token's semantic role within its frame and failing to adapt compression strength to the compressibility of each frame pair. In this work, we propose OTT-Vid, a transport-derived allocation framework for temporal token compression. Our approach consists of two stages: spatial pruning identifies representative content within each frame, and optimal transport (OT) is then solved between neighboring frames to estimate temporal compressibility. We formulate this OT with non-uniform token mass, which protects semantically important tokens from aggressive compression, and a locality-aware cost that captures both feature and spatial disparities. The resulting transport plan jointly balances token importance and matching cost, while its total cost defines the transport difficulty of each frame pair, which we use to allocate compression budgets dynamically. Experiments on six benchmarks spanning video question answering and temporal grounding show that OTT-Vid preserves 95.8% of VQA and 73.9% of VTG performance while retaining only 10% of tokens, consistently outperforming existing state-of-the-art training-free compression methods.
Effective SAM Combination for Open-Vocabulary Semantic Segmentation
Nov 22, 2024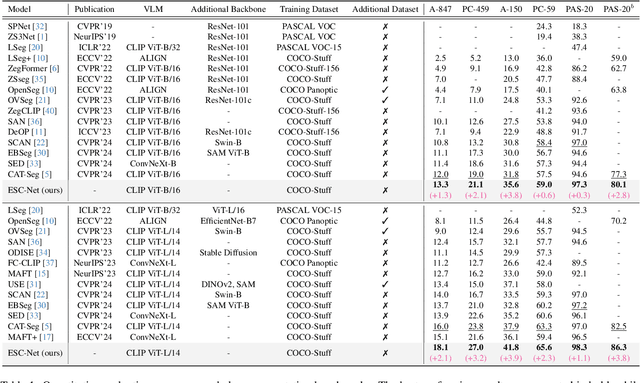
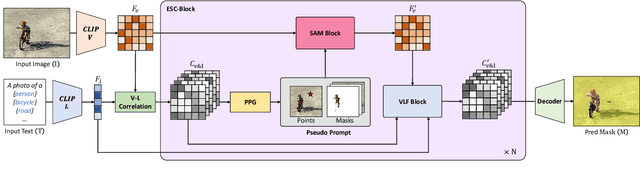
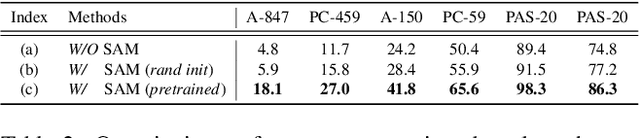

Open-vocabulary semantic segmentation aims to assign pixel-level labels to images across an unlimited range of classes. Traditional methods address this by sequentially connecting a powerful mask proposal generator, such as the Segment Anything Model (SAM), with a pre-trained vision-language model like CLIP. But these two-stage approaches often suffer from high computational costs, memory inefficiencies. In this paper, we propose ESC-Net, a novel one-stage open-vocabulary segmentation model that leverages the SAM decoder blocks for class-agnostic segmentation within an efficient inference framework. By embedding pseudo prompts generated from image-text correlations into SAM's promptable segmentation framework, ESC-Net achieves refined spatial aggregation for accurate mask predictions. ESC-Net achieves superior performance on standard benchmarks, including ADE20K, PASCAL-VOC, and PASCAL-Context, outperforming prior methods in both efficiency and accuracy. Comprehensive ablation studies further demonstrate its robustness across challenging conditions.
Synchronizing Vision and Language: Bidirectional Token-Masking AutoEncoder for Referring Image Segmentation
Nov 29, 2023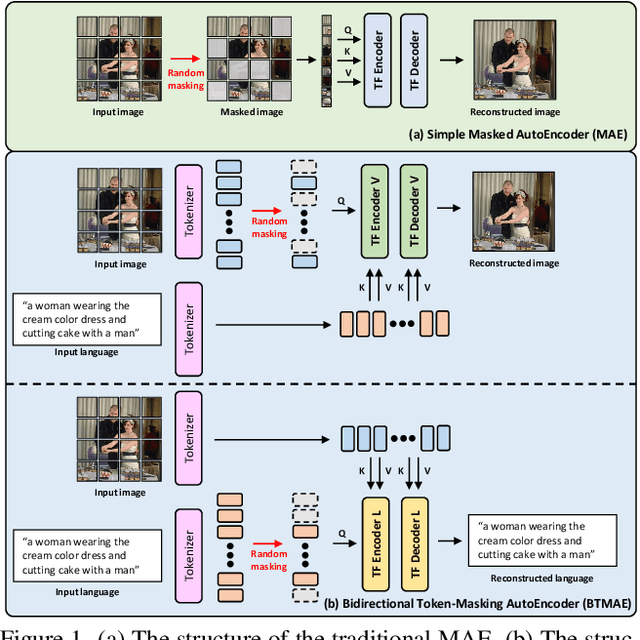
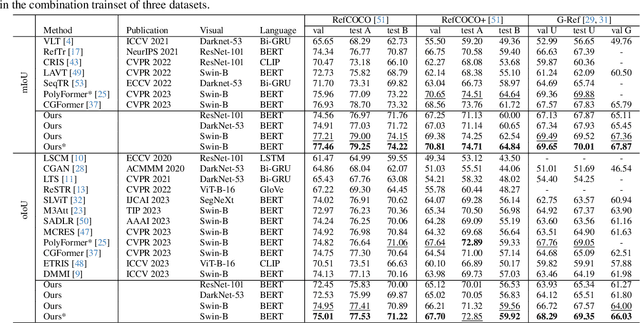
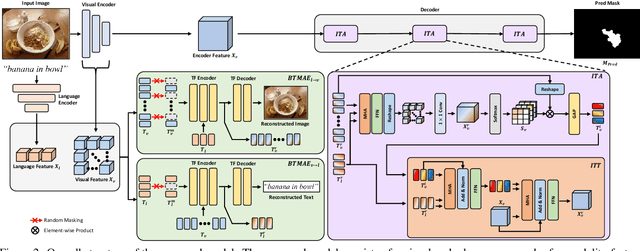
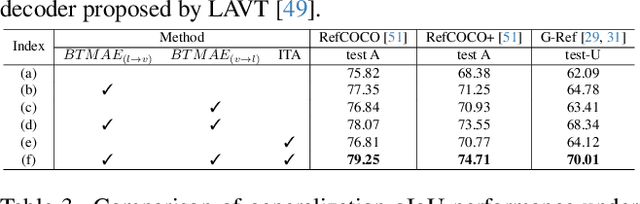
Referring Image Segmentation (RIS) aims to segment target objects expressed in natural language within a scene at the pixel level. Various recent RIS models have achieved state-of-the-art performance by generating contextual tokens to model multimodal features from pretrained encoders and effectively fusing them using transformer-based cross-modal attention. While these methods match language features with image features to effectively identify likely target objects, they often struggle to correctly understand contextual information in complex and ambiguous sentences and scenes. To address this issue, we propose a novel bidirectional token-masking autoencoder (BTMAE) inspired by the masked autoencoder (MAE). The proposed model learns the context of image-to-language and language-to-image by reconstructing missing features in both image and language features at the token level. In other words, this approach involves mutually complementing across the features of images and language, with a focus on enabling the network to understand interconnected deep contextual information between the two modalities. This learning method enhances the robustness of RIS performance in complex sentences and scenes. Our BTMAE achieves state-of-the-art performance on three popular datasets, and we demonstrate the effectiveness of the proposed method through various ablation studies.
DyAnNet: A Scene Dynamicity Guided Self-Trained Video Anomaly Detection Network
Nov 02, 2022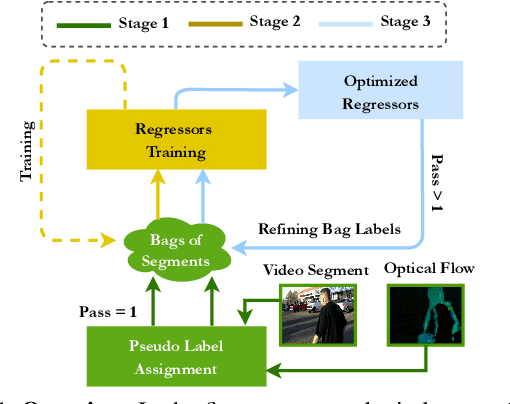
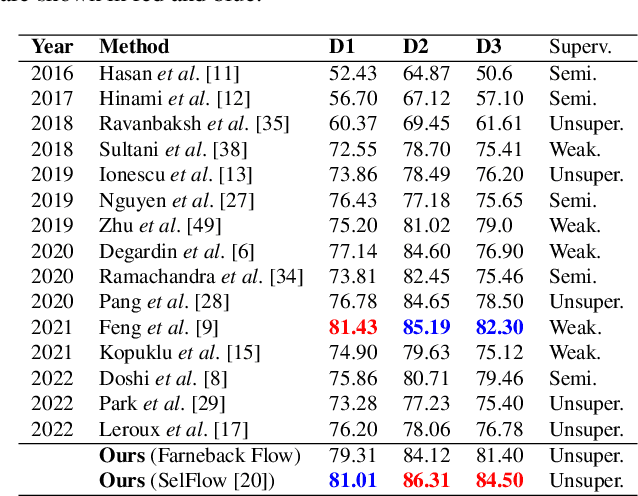
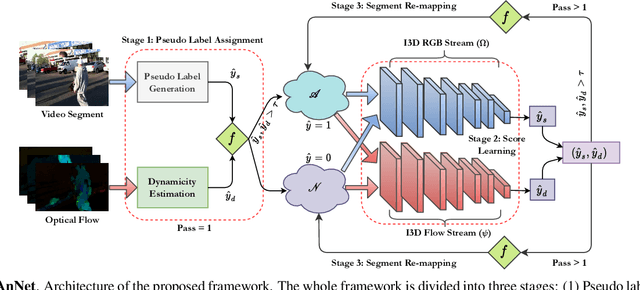
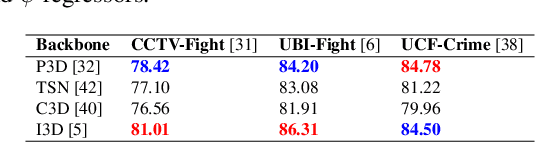
Unsupervised approaches for video anomaly detection may not perform as good as supervised approaches. However, learning unknown types of anomalies using an unsupervised approach is more practical than a supervised approach as annotation is an extra burden. In this paper, we use isolation tree-based unsupervised clustering to partition the deep feature space of the video segments. The RGB- stream generates a pseudo anomaly score and the flow stream generates a pseudo dynamicity score of a video segment. These scores are then fused using a majority voting scheme to generate preliminary bags of positive and negative segments. However, these bags may not be accurate as the scores are generated only using the current segment which does not represent the global behavior of a typical anomalous event. We then use a refinement strategy based on a cross-branch feed-forward network designed using a popular I3D network to refine both scores. The bags are then refined through a segment re-mapping strategy. The intuition of adding the dynamicity score of a segment with the anomaly score is to enhance the quality of the evidence. The method has been evaluated on three popular video anomaly datasets, i.e., UCF-Crime, CCTV-Fights, and UBI-Fights. Experimental results reveal that the proposed framework achieves competitive accuracy as compared to the state-of-the-art video anomaly detection methods.
K-FACE: A Large-Scale KIST Face Database in Consideration with Unconstrained Environments
Mar 03, 2021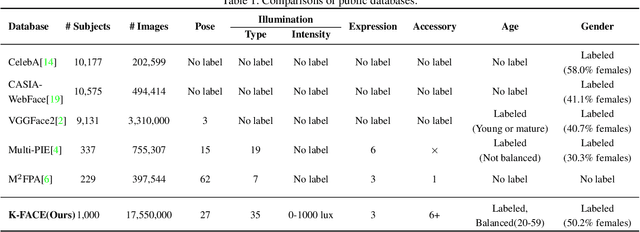
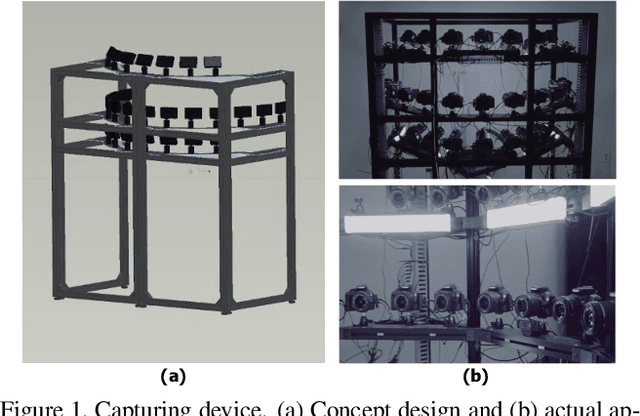
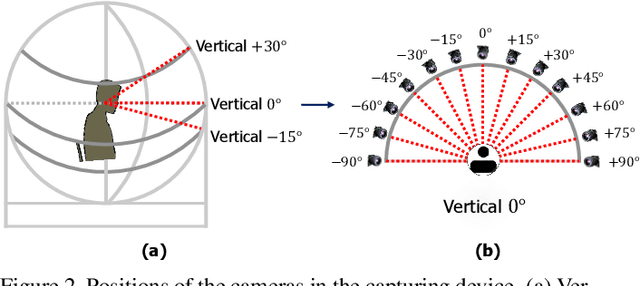
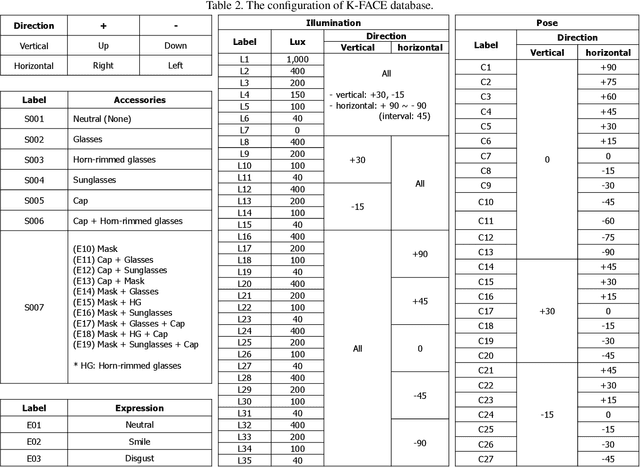
In this paper, we introduce a new large-scale face database from KIST, denoted as K-FACE, and describe a novel capturing device specifically designed to obtain the data. The K-FACE database contains more than 1 million high-quality images of 1,000 subjects selected by considering the ratio of gender and age groups. It includes a variety of attributes, including 27 poses, 35 lighting conditions, three expressions, and occlusions by the combination of five types of accessories. As the K-FACE database is systematically constructed through a hemispherical capturing system with elaborate lighting control and multiple cameras, it is possible to accurately analyze the effects of factors that cause performance degradation, such as poses, lighting changes, and accessories. We consider not only the balance of external environmental factors, such as pose and lighting, but also the balance of personal characteristics such as gender and age group. The gender ratio is the same, while the age groups of subjects are uniformly distributed from the 20s to 50s for both genders. The K-FACE database can be extensively utilized in various vision tasks, such as face recognition, face frontalization, illumination normalization, face age estimation, and three-dimensional face model generation. We expect systematic diversity and uniformity of the K-FACE database to promote these research fields.
Person Re-identification in Videos by Analyzing Spatio-Temporal Tubes
Feb 13, 2019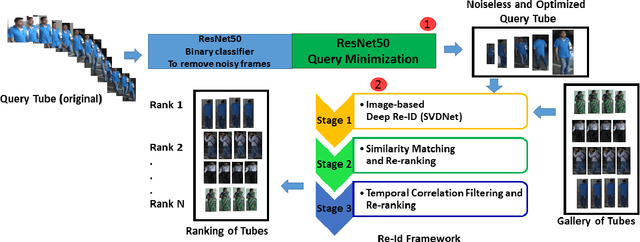
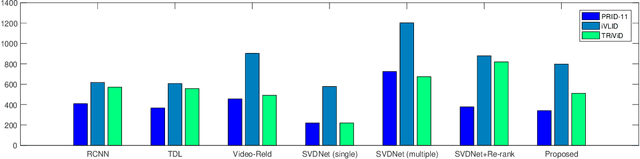
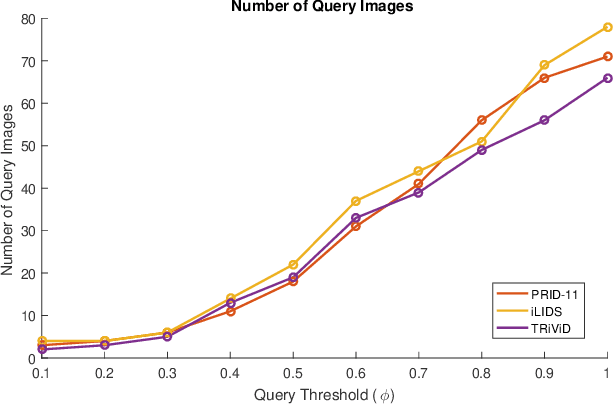
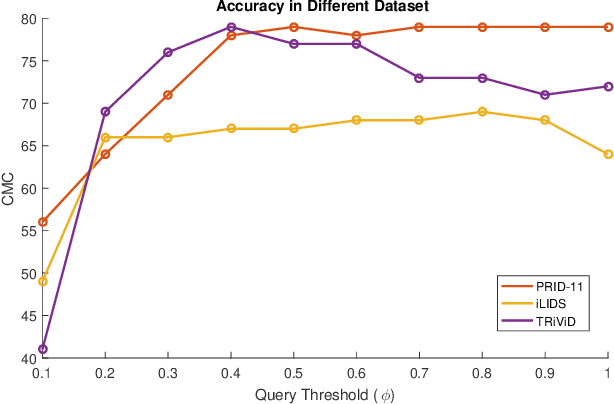
Typical person re-identification frameworks search for k best matches in a gallery of images that are often collected in varying conditions. The gallery may contain image sequences when re-identification is done on videos. However, such a process is time consuming as re-identification has to be carried out multiple times. In this paper, we extract spatio-temporal sequences of frames (referred to as tubes) of moving persons and apply a multi-stage processing to match a given query tube with a gallery of stored tubes recorded through other cameras. Initially, we apply a binary classifier to remove noisy images from the input query tube. In the next step, we use a key-pose detection-based query minimization. This reduces the length of the query tube by removing redundant frames. Finally, a 3-stage hierarchical re-identification framework is used to rank the output tubes as per the matching scores. Experiments with publicly available video re-identification datasets reveal that our framework is better than state-of-the-art methods. It ranks the tubes with an increased CMC accuracy of 6-8% across multiple datasets. Also, our method significantly reduces the number of false positives. A new video re-identification dataset, named Tube-based Reidentification Video Dataset (TRiViD), has been prepared with an aim to help the re-identification research community