 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenCLIP: Generalizing CLIP Prompts for Zero-shot Anomaly Detection
Apr 21, 2025Zero-shot anomaly detection (ZSAD) aims to identify anomalies in unseen categories by leveraging CLIP's zero-shot capabilities to match text prompts with visual features. A key challenge in ZSAD is learning general prompts stably and utilizing them effectively, while maintaining both generalizability and category specificity. Although general prompts have been explored in prior works, achieving their stable optimization and effective deployment remains a significant challenge. In this work, we propose GenCLIP, a novel framework that learns and leverages general prompts more effectively through multi-layer prompting and dual-branch inference. Multi-layer prompting integrates category-specific visual cues from different CLIP layers, enriching general prompts with more comprehensive and robust feature representations. By combining general prompts with multi-layer visual features, our method further enhances its generalization capability. To balance specificity and generalization, we introduce a dual-branch inference strategy, where a vision-enhanced branch captures fine-grained category-specific features, while a query-only branch prioritizes generalization. The complementary outputs from both branches improve the stability and reliability of anomaly detection across unseen categories. Additionally, we propose an adaptive text prompt filtering mechanism, which removes irrelevant or atypical class names not encountered during CLIP's training, ensuring that only meaningful textual inputs contribute to the final vision-language alignment.
CoMoGaussian: Continuous Motion-Aware Gaussian Splatting from Motion-Blurred Images
Mar 07, 20253D Gaussian Splatting (3DGS) has gained significant attention for their high-quality novel view rendering, motivating research to address real-world challenges. A critical issue is the camera motion blur caused by movement during exposure, which hinders accurate 3D scene reconstruction. In this study, we propose CoMoGaussian, a Continuous Motion-Aware Gaussian Splatting that reconstructs precise 3D scenes from motion-blurred images while maintaining real-time rendering speed. Considering the complex motion patterns inherent in real-world camera movements, we predict continuous camera trajectories using neural ordinary differential equations (ODEs). To ensure accurate modeling, we employ rigid body transformations, preserving the shape and size of the object but rely on the discrete integration of sampled frames. To better approximate the continuous nature of motion blur, we introduce a continuous motion refinement (CMR) transformation that refines rigid transformations by incorporating additional learnable parameters. By revisiting fundamental camera theory and leveraging advanced neural ODE techniques, we achieve precise modeling of continuous camera trajectories, leading to improved reconstruction accuracy. Extensive experiments demonstrate state-of-the-art performance both quantitatively and qualitatively on benchmark datasets, which include a wide range of motion blur scenarios, from moderate to extreme blur.
Find First, Track Next: Decoupling Identification and Propagation in Referring Video Object Segmentation
Mar 05, 2025



Referring video object segmentation aims to segment and track a target object in a video using a natural language prompt. Existing methods typically fuse visual and textual features in a highly entangled manner, processing multi-modal information together to generate per-frame masks. However, this approach often struggles with ambiguous target identification, particularly in scenes with multiple similar objects, and fails to ensure consistent mask propagation across frames. To address these limitations, we introduce FindTrack, a novel decoupled framework that separates target identification from mask propagation. FindTrack first adaptively selects a key frame by balancing segmentation confidence and vision-text alignment, establishing a robust reference for the target object. This reference is then utilized by a dedicated propagation module to track and segment the object across the entire video. By decoupling these processes, FindTrack effectively reduces ambiguities in target association and enhances segmentation consistency. We demonstrate that FindTrack outperforms existing methods on public benchmarks.
CoCoGaussian: Leveraging Circle of Confusion for Gaussian Splatting from Defocused Images
Dec 20, 2024



3D Gaussian Splatting (3DGS) has attracted significant attention for its high-quality novel view rendering, inspiring research to address real-world challenges. While conventional methods depend on sharp images for accurate scene reconstruction, real-world scenarios are often affected by defocus blur due to finite depth of field, making it essential to account for realistic 3D scene representation. In this study, we propose CoCoGaussian, a Circle of Confusion-aware Gaussian Splatting that enables precise 3D scene representation using only defocused images. CoCoGaussian addresses the challenge of defocus blur by modeling the Circle of Confusion (CoC) through a physically grounded approach based on the principles of photographic defocus. Exploiting 3D Gaussians, we compute the CoC diameter from depth and learnable aperture information, generating multiple Gaussians to precisely capture the CoC shape. Furthermore, we introduce a learnable scaling factor to enhance robustness and provide more flexibility in handling unreliable depth in scenes with reflective or refractive surfaces. Experiments on both synthetic and real-world datasets demonstrate that CoCoGaussian achieves state-of-the-art performance across multiple benchmarks.
Elevating Flow-Guided Video Inpainting with Reference Generation
Dec 12, 2024
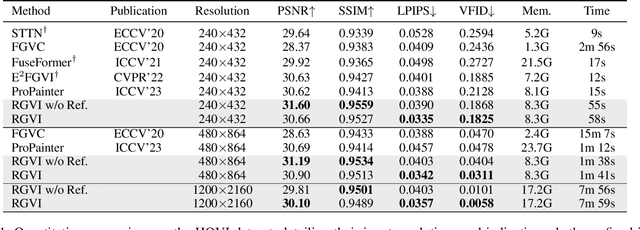
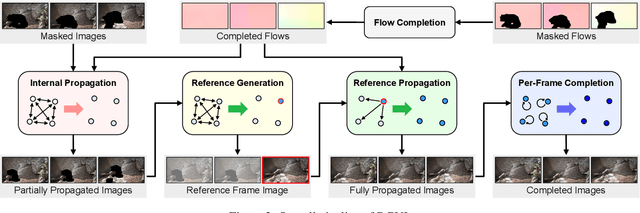
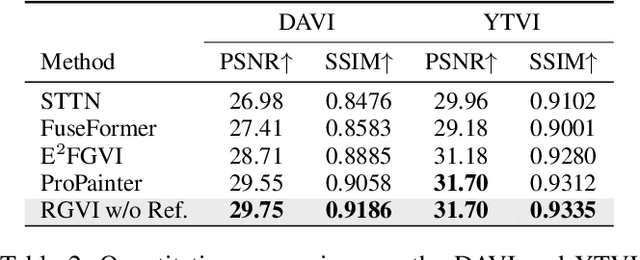
Video inpainting (VI) is a challenging task that requires effective propagation of observable content across frames while simultaneously generating new content not present in the original video. In this study, we propose a robust and practical VI framework that leverages a large generative model for reference generation in combination with an advanced pixel propagation algorithm. Powered by a strong generative model, our method not only significantly enhances frame-level quality for object removal but also synthesizes new content in the missing areas based on user-provided text prompts. For pixel propagation, we introduce a one-shot pixel pulling method that effectively avoids error accumulation from repeated sampling while maintaining sub-pixel precision. To evaluate various VI methods in realistic scenarios, we also propose a high-quality VI benchmark, HQVI, comprising carefully generated videos using alpha matte composition. On public benchmarks and the HQVI dataset, our method demonstrates significantly higher visual quality and metric scores compared to existing solutions. Furthermore, it can process high-resolution videos exceeding 2K resolution with ease, underscoring its superiority for real-world applications.
STATIC : Surface Temporal Affine for TIme Consistency in Video Monocular Depth Estimation
Dec 02, 2024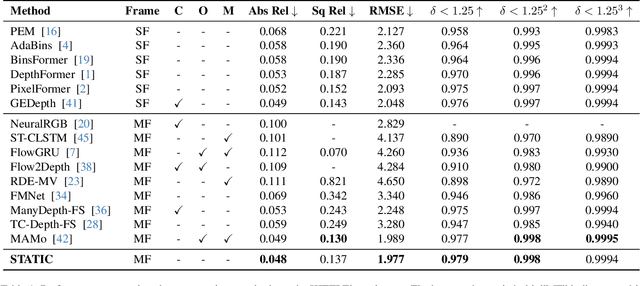


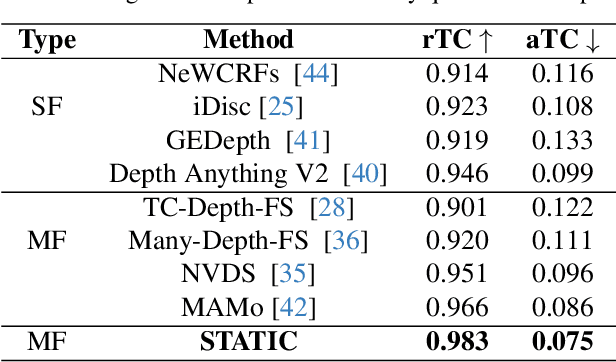
Video monocular depth estimation is essential for applications such as autonomous driving, AR/VR, and robotics. Recent transformer-based single-image monocular depth estimation models perform well on single images but struggle with depth consistency across video frames. Traditional methods aim to improve temporal consistency using multi-frame temporal modules or prior information like optical flow and camera parameters. However, these approaches face issues such as high memory use, reduced performance with dynamic or irregular motion, and limited motion understanding. We propose STATIC, a novel model that independently learns temporal consistency in static and dynamic area without additional information. A difference mask from surface normals identifies static and dynamic area by measuring directional variance. For static area, the Masked Static (MS) module enhances temporal consistency by focusing on stable regions. For dynamic area, the Surface Normal Similarity (SNS) module aligns areas and enhances temporal consistency by measuring feature similarity between frames. A final refinement integrates the independently learned static and dynamic area, enabling STATIC to achieve temporal consistency across the entire sequence. Our method achieves state-of-the-art video depth estimation on the KITTI and NYUv2 datasets without additional information.
Effective SAM Combination for Open-Vocabulary Semantic Segmentation
Nov 22, 2024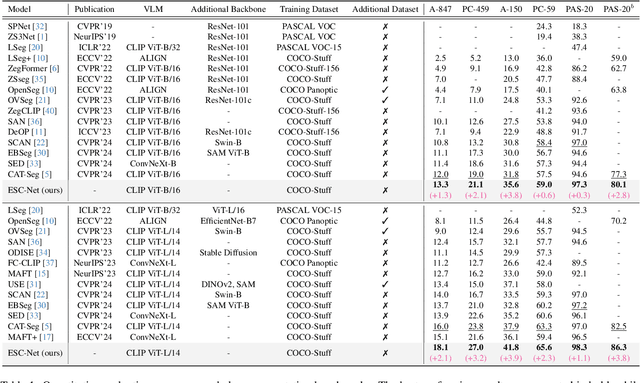
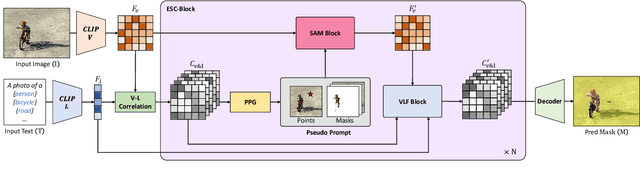
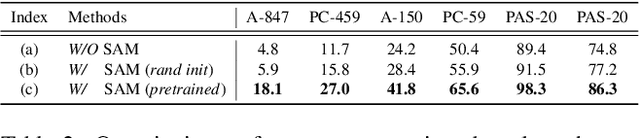

Open-vocabulary semantic segmentation aims to assign pixel-level labels to images across an unlimited range of classes. Traditional methods address this by sequentially connecting a powerful mask proposal generator, such as the Segment Anything Model (SAM), with a pre-trained vision-language model like CLIP. But these two-stage approaches often suffer from high computational costs, memory inefficiencies. In this paper, we propose ESC-Net, a novel one-stage open-vocabulary segmentation model that leverages the SAM decoder blocks for class-agnostic segmentation within an efficient inference framework. By embedding pseudo prompts generated from image-text correlations into SAM's promptable segmentation framework, ESC-Net achieves refined spatial aggregation for accurate mask predictions. ESC-Net achieves superior performance on standard benchmarks, including ADE20K, PASCAL-VOC, and PASCAL-Context, outperforming prior methods in both efficiency and accuracy. Comprehensive ablation studies further demonstrate its robustness across challenging conditions.
Transforming Static Images Using Generative Models for Video Salient Object Detection
Nov 21, 2024



In many video processing tasks, leveraging large-scale image datasets is a common strategy, as image data is more abundant and facilitates comprehensive knowledge transfer. A typical approach for simulating video from static images involves applying spatial transformations, such as affine transformations and spline warping, to create sequences that mimic temporal progression. However, in tasks like video salient object detection, where both appearance and motion cues are critical, these basic image-to-video techniques fail to produce realistic optical flows that capture the independent motion properties of each object. In this study, we show that image-to-video diffusion models can generate realistic transformations of static images while understanding the contextual relationships between image components. This ability allows the model to generate plausible optical flows, preserving semantic integrity while reflecting the independent motion of scene elements. By augmenting individual images in this way, we create large-scale image-flow pairs that significantly enhance model training. Our approach achieves state-of-the-art performance across all public benchmark datasets, outperforming existing approaches.
Video Diffusion Models are Strong Video Inpainter
Aug 21, 2024



Propagation-based video inpainting using optical flow at the pixel or feature level has recently garnered significant attention. However, it has limitations such as the inaccuracy of optical flow prediction and the propagation of noise over time. These issues result in non-uniform noise and time consistency problems throughout the video, which are particularly pronounced when the removed area is large and involves substantial movement. To address these issues, we propose a novel First Frame Filling Video Diffusion Inpainting model (FFF-VDI). We design FFF-VDI inspired by the capabilities of pre-trained image-to-video diffusion models that can transform the first frame image into a highly natural video. To apply this to the video inpainting task, we propagate the noise latent information of future frames to fill the masked areas of the first frame's noise latent code. Next, we fine-tune the pre-trained image-to-video diffusion model to generate the inpainted video. The proposed model addresses the limitations of existing methods that rely on optical flow quality, producing much more natural and temporally consistent videos. This proposed approach is the first to effectively integrate image-to-video diffusion models into video inpainting tasks. Through various comparative experiments, we demonstrate that the proposed model can robustly handle diverse inpainting types with high quality.
CRiM-GS: Continuous Rigid Motion-Aware Gaussian Splatting from Motion Blur Images
Jul 04, 2024



Neural radiance fields (NeRFs) have received significant attention due to their high-quality novel view rendering ability, prompting research to address various real-world cases. One critical challenge is the camera motion blur caused by camera movement during exposure time, which prevents accurate 3D scene reconstruction. In this study, we propose continuous rigid motion-aware gaussian splatting (CRiM-GS) to reconstruct accurate 3D scene from blurry images with real-time rendering speed. Considering the actual camera motion blurring process, which consists of complex motion patterns, we predict the continuous movement of the camera based on neural ordinary differential equations (ODEs). Specifically, we leverage rigid body transformations to model the camera motion with proper regularization, preserving the shape and size of the object. Furthermore, we introduce a continuous deformable 3D transformation in the \textit{SE(3)} field to adapt the rigid body transformation to real-world problems by ensuring a higher degree of freedom. By revisiting fundamental camera theory and employing advanced neural network training techniques, we achieve accurate modeling of continuous camera trajectories. We conduct extensive experiments, demonstrating state-of-the-art performance both quantitatively and qualitatively on benchmark datasets.