 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOTT-Vid: Optimal Transport Temporal Token Compression for Video Large Language Models
May 12, 2026As Video Large Language Models (Video-LLMs) scale to longer and more complex videos, their inference cost grows rapidly due to the large volume of visual tokens accumulated across frames. Training-free token compression has emerged as a practical solution to this bottleneck. However, existing temporal compression methods rely primarily on cross-frame token similarity or segmentation heuristics, overlooking each token's semantic role within its frame and failing to adapt compression strength to the compressibility of each frame pair. In this work, we propose OTT-Vid, a transport-derived allocation framework for temporal token compression. Our approach consists of two stages: spatial pruning identifies representative content within each frame, and optimal transport (OT) is then solved between neighboring frames to estimate temporal compressibility. We formulate this OT with non-uniform token mass, which protects semantically important tokens from aggressive compression, and a locality-aware cost that captures both feature and spatial disparities. The resulting transport plan jointly balances token importance and matching cost, while its total cost defines the transport difficulty of each frame pair, which we use to allocate compression budgets dynamically. Experiments on six benchmarks spanning video question answering and temporal grounding show that OTT-Vid preserves 95.8% of VQA and 73.9% of VTG performance while retaining only 10% of tokens, consistently outperforming existing state-of-the-art training-free compression methods.
CMTM: Cross-Modal Token Modulation for Unsupervised Video Object Segmentation
Apr 16, 2026Recent advances in unsupervised video object segmentation have highlighted the potential of two-stream architectures that integrate appearance and motion cues. However, fully leveraging these complementary sources of information requires effectively modeling their interdependencies. In this paper, we introduce cross-modality token modulation, a novel approach designed to strengthen the interaction between appearance and motion cues. Our method establishes dense connections between tokens from each modality, enabling efficient intra-modal and inter-modal information propagation through relation transformer blocks. To improve learning efficiency, we incorporate a token masking strategy that addresses the limitations of relying solely on increased model complexity. Our approach achieves state-of-the-art performance across all public benchmarks, outperforming existing methods.
MoRGS: Efficient Per-Gaussian Motion Reasoning for Streamable Dynamic 3D Scenes
Mar 26, 2026Online reconstruction of dynamic scenes aims to learn from streaming multi-view inputs under low-latency constraints. The fast training and real-time rendering capabilities of 3D Gaussian Splatting have made on-the-fly reconstruction practically feasible, enabling online 4D reconstruction. However, existing online approaches, despite their efficiency and visual quality, fail to learn per-Gaussian motion that reflects true scene dynamics. Without explicit motion cues, appearance and motion are optimized solely under photometric loss, causing per-Gaussian motion to chase pixel residuals rather than true 3D motion. To address this, we propose MoRGS, an efficient online per-Gaussian motion reasoning framework that explicitly models per-Gaussian motion to improve 4D reconstruction quality. Specifically, we leverage optical flow on a sparse set of key views as lightweight motion cues that regularize per-Gaussian motion beyond photometric supervision. To compensate for the sparsity of flow supervision, we learn a per-Gaussian motion offset field that reconciles discrepancies between projected 3D motion and observed flow across views and time. In addition, we introduce a per-Gaussian motion confidence that separates dynamic from static Gaussians and weights Gaussian attribute residual updates, thereby suppressing redundant motion in static regions for better temporal consistency and accelerating the modeling of large motions. Extensive experiments demonstrate that MoRGS achieves state-of-the-art reconstruction quality and motion fidelity among online methods, while maintaining streamable performance.
Revisiting Weakly-Supervised Video Scene Graph Generation via Pair Affinity Learning
Mar 23, 2026Weakly-supervised video scene graph generation (WS-VSGG) aims to parse video content into structured relational triplets without bounding box annotations and with only sparse temporal labeling, significantly reducing annotation costs. Without ground-truth bounding boxes, these methods rely on off-the-shelf detectors to generate object proposals, yet largely overlook a fundamental discrepancy from fullysupervised pipelines. Fully-supervised detectors implicitly filter out noninteractive objects, while off-the-shelf detectors indiscriminately detect all visible objects, overwhelming relation models with noisy pairs.We address this by introducing a learnable pair affinity that estimates the likelihood of interaction between subject-object pairs. Through Pair Affinity Learning and Scoring (PALS), pair affinity is incorporated into inferencetime ranking and further integrated into contextual reasoning through Pair Affinity Modulation (PAM), enabling the model to suppress noninteractive pairs and focus on relationally meaningful ones. To provide cleaner supervision for pair affinity learning, we further propose Relation- Aware Matching (RAM), which leverages vision-language grounding to resolve class-level ambiguity in pseudo-label generation. Extensive experiments on Action Genome demonstrate that our approach consistently yields substantial improvements across different baselines and backbones, achieving state-of-the-art WS-VSGG performance.
Motion-Specific Battery Health Assessment for Quadrotors Using High-Fidelity Battery Models
Mar 13, 2026Quadrotor endurance is ultimately limited by battery behavior, yet most energy aware planning treats the battery as a simple energy reservoir and overlooks how flight motions induce dynamic current loads that accelerate battery degradation. This work presents an end to end framework for motion aware battery health assessment in quadrotors. We first design a wide range current sensing module to capture motion specific current profiles during real flights, preserving transient features. In parallel, a high fidelity battery model is calibrated using reference performance tests and a metaheuristic based on a degradation coupled electrochemical model.By simulating measured flight loads in the calibrated model, we systematically resolve how different flight motions translate into degradation modes loss of lithium inventory and loss of active material as well as internal side reactions. The results demonstrate that even when two flight profiles consume the same average energy, their transient load structures can drive different degradation pathways, emphasizing the need for motion-aware battery management that balances efficiency with battery degradation.
GenCLIP: Generalizing CLIP Prompts for Zero-shot Anomaly Detection
Apr 21, 2025Zero-shot anomaly detection (ZSAD) aims to identify anomalies in unseen categories by leveraging CLIP's zero-shot capabilities to match text prompts with visual features. A key challenge in ZSAD is learning general prompts stably and utilizing them effectively, while maintaining both generalizability and category specificity. Although general prompts have been explored in prior works, achieving their stable optimization and effective deployment remains a significant challenge. In this work, we propose GenCLIP, a novel framework that learns and leverages general prompts more effectively through multi-layer prompting and dual-branch inference. Multi-layer prompting integrates category-specific visual cues from different CLIP layers, enriching general prompts with more comprehensive and robust feature representations. By combining general prompts with multi-layer visual features, our method further enhances its generalization capability. To balance specificity and generalization, we introduce a dual-branch inference strategy, where a vision-enhanced branch captures fine-grained category-specific features, while a query-only branch prioritizes generalization. The complementary outputs from both branches improve the stability and reliability of anomaly detection across unseen categories. Additionally, we propose an adaptive text prompt filtering mechanism, which removes irrelevant or atypical class names not encountered during CLIP's training, ensuring that only meaningful textual inputs contribute to the final vision-language alignment.
CoMoGaussian: Continuous Motion-Aware Gaussian Splatting from Motion-Blurred Images
Mar 07, 20253D Gaussian Splatting (3DGS) has gained significant attention for their high-quality novel view rendering, motivating research to address real-world challenges. A critical issue is the camera motion blur caused by movement during exposure, which hinders accurate 3D scene reconstruction. In this study, we propose CoMoGaussian, a Continuous Motion-Aware Gaussian Splatting that reconstructs precise 3D scenes from motion-blurred images while maintaining real-time rendering speed. Considering the complex motion patterns inherent in real-world camera movements, we predict continuous camera trajectories using neural ordinary differential equations (ODEs). To ensure accurate modeling, we employ rigid body transformations, preserving the shape and size of the object but rely on the discrete integration of sampled frames. To better approximate the continuous nature of motion blur, we introduce a continuous motion refinement (CMR) transformation that refines rigid transformations by incorporating additional learnable parameters. By revisiting fundamental camera theory and leveraging advanced neural ODE techniques, we achieve precise modeling of continuous camera trajectories, leading to improved reconstruction accuracy. Extensive experiments demonstrate state-of-the-art performance both quantitatively and qualitatively on benchmark datasets, which include a wide range of motion blur scenarios, from moderate to extreme blur.
Sparse-DeRF: Deblurred Neural Radiance Fields from Sparse View
Jul 09, 2024



Recent studies construct deblurred neural radiance fields (DeRF) using dozens of blurry images, which are not practical scenarios if only a limited number of blurry images are available. This paper focuses on constructing DeRF from sparse-view for more pragmatic real-world scenarios. As observed in our experiments, establishing DeRF from sparse views proves to be a more challenging problem due to the inherent complexity arising from the simultaneous optimization of blur kernels and NeRF from sparse view. Sparse-DeRF successfully regularizes the complicated joint optimization, presenting alleviated overfitting artifacts and enhanced quality on radiance fields. The regularization consists of three key components: Surface smoothness, helps the model accurately predict the scene structure utilizing unseen and additional hidden rays derived from the blur kernel based on statistical tendencies of real-world; Modulated gradient scaling, helps the model adjust the amount of the backpropagated gradient according to the arrangements of scene objects; Perceptual distillation improves the perceptual quality by overcoming the ill-posed multi-view inconsistency of image deblurring and distilling the pre-filtered information, compensating for the lack of clean information in blurry images. We demonstrate the effectiveness of the Sparse-DeRF with extensive quantitative and qualitative experimental results by training DeRF from 2-view, 4-view, and 6-view blurry images.
CRiM-GS: Continuous Rigid Motion-Aware Gaussian Splatting from Motion Blur Images
Jul 04, 2024



Neural radiance fields (NeRFs) have received significant attention due to their high-quality novel view rendering ability, prompting research to address various real-world cases. One critical challenge is the camera motion blur caused by camera movement during exposure time, which prevents accurate 3D scene reconstruction. In this study, we propose continuous rigid motion-aware gaussian splatting (CRiM-GS) to reconstruct accurate 3D scene from blurry images with real-time rendering speed. Considering the actual camera motion blurring process, which consists of complex motion patterns, we predict the continuous movement of the camera based on neural ordinary differential equations (ODEs). Specifically, we leverage rigid body transformations to model the camera motion with proper regularization, preserving the shape and size of the object. Furthermore, we introduce a continuous deformable 3D transformation in the \textit{SE(3)} field to adapt the rigid body transformation to real-world problems by ensuring a higher degree of freedom. By revisiting fundamental camera theory and employing advanced neural network training techniques, we achieve accurate modeling of continuous camera trajectories. We conduct extensive experiments, demonstrating state-of-the-art performance both quantitatively and qualitatively on benchmark datasets.
FIMP: Future Interaction Modeling for Multi-Agent Motion Prediction
Jan 29, 2024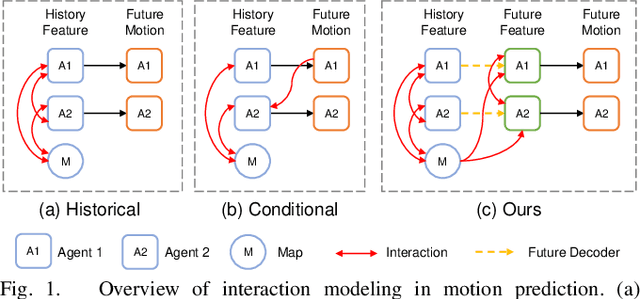
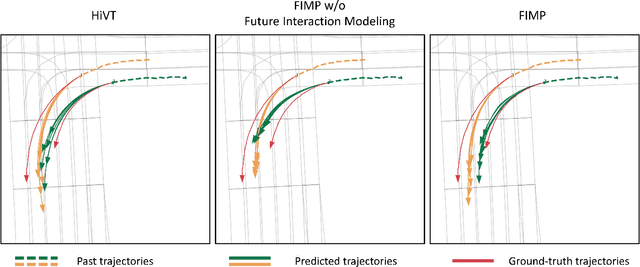
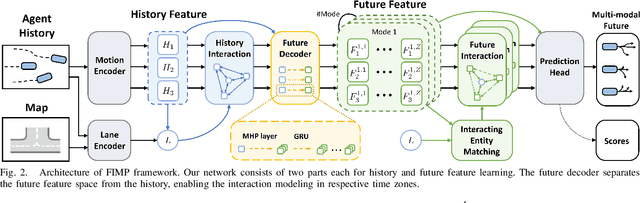
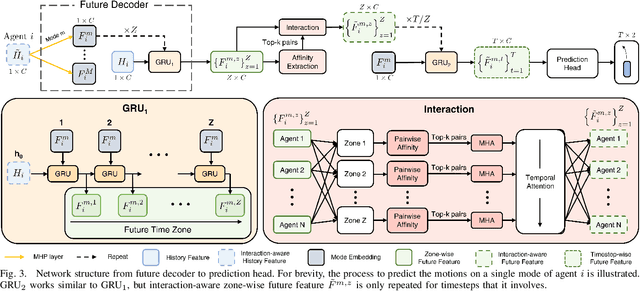
Multi-agent motion prediction is a crucial concern in autonomous driving, yet it remains a challenge owing to the ambiguous intentions of dynamic agents and their intricate interactions. Existing studies have attempted to capture interactions between road entities by using the definite data in history timesteps, as future information is not available and involves high uncertainty. However, without sufficient guidance for capturing future states of interacting agents, they frequently produce unrealistic trajectory overlaps. In this work, we propose Future Interaction modeling for Motion Prediction (FIMP), which captures potential future interactions in an end-to-end manner. FIMP adopts a future decoder that implicitly extracts the potential future information in an intermediate feature-level, and identifies the interacting entity pairs through future affinity learning and top-k filtering strategy. Experiments show that our future interaction modeling improves the performance remarkably, leading to superior performance on the Argoverse motion forecasting benchmark.