 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOTT-Vid: Optimal Transport Temporal Token Compression for Video Large Language Models
May 12, 2026As Video Large Language Models (Video-LLMs) scale to longer and more complex videos, their inference cost grows rapidly due to the large volume of visual tokens accumulated across frames. Training-free token compression has emerged as a practical solution to this bottleneck. However, existing temporal compression methods rely primarily on cross-frame token similarity or segmentation heuristics, overlooking each token's semantic role within its frame and failing to adapt compression strength to the compressibility of each frame pair. In this work, we propose OTT-Vid, a transport-derived allocation framework for temporal token compression. Our approach consists of two stages: spatial pruning identifies representative content within each frame, and optimal transport (OT) is then solved between neighboring frames to estimate temporal compressibility. We formulate this OT with non-uniform token mass, which protects semantically important tokens from aggressive compression, and a locality-aware cost that captures both feature and spatial disparities. The resulting transport plan jointly balances token importance and matching cost, while its total cost defines the transport difficulty of each frame pair, which we use to allocate compression budgets dynamically. Experiments on six benchmarks spanning video question answering and temporal grounding show that OTT-Vid preserves 95.8% of VQA and 73.9% of VTG performance while retaining only 10% of tokens, consistently outperforming existing state-of-the-art training-free compression methods.
CMTM: Cross-Modal Token Modulation for Unsupervised Video Object Segmentation
Apr 16, 2026Recent advances in unsupervised video object segmentation have highlighted the potential of two-stream architectures that integrate appearance and motion cues. However, fully leveraging these complementary sources of information requires effectively modeling their interdependencies. In this paper, we introduce cross-modality token modulation, a novel approach designed to strengthen the interaction between appearance and motion cues. Our method establishes dense connections between tokens from each modality, enabling efficient intra-modal and inter-modal information propagation through relation transformer blocks. To improve learning efficiency, we incorporate a token masking strategy that addresses the limitations of relying solely on increased model complexity. Our approach achieves state-of-the-art performance across all public benchmarks, outperforming existing methods.
Seen-to-Scene: Keep the Seen, Generate the Unseen for Video Outpainting
Apr 16, 2026Video outpainting aims to expand the visible content of a video beyond the original frame boundaries while preserving spatial fidelity and temporal coherence across frames. Existing methods primarily rely on large-scale generative models, such as diffusion models. However, generationbased approaches suffer from implicit temporal modeling and limited spatial context. These limitations lead to intraframe and inter-frame inconsistencies, which become particularly pronounced in dynamic scenes and large outpainting scenarios. To overcome these challenges, we propose Seen-to-Scene, a novel framework that unifies propagationbased and generation-based paradigms for video outpainting. Specifically, Seen-to-Scene leverages flow-based propagation with a flow completion network pre-trained for video inpainting, which is fine-tuned in an end-to-end manner to bridge the domain gap and reconstruct coherent motion fields. To further improve the efficiency and reliability of propagation, we introduce a reference-guided latent propagation that effectively propagates source content across frames. Extensive experiments demonstrate that our method achieves superior temporal coherence and visual realism with efficient inference, surpassing even prior state-of-the-art methods that require input-specific adaptation.
Revisiting Weakly-Supervised Video Scene Graph Generation via Pair Affinity Learning
Mar 23, 2026Weakly-supervised video scene graph generation (WS-VSGG) aims to parse video content into structured relational triplets without bounding box annotations and with only sparse temporal labeling, significantly reducing annotation costs. Without ground-truth bounding boxes, these methods rely on off-the-shelf detectors to generate object proposals, yet largely overlook a fundamental discrepancy from fullysupervised pipelines. Fully-supervised detectors implicitly filter out noninteractive objects, while off-the-shelf detectors indiscriminately detect all visible objects, overwhelming relation models with noisy pairs.We address this by introducing a learnable pair affinity that estimates the likelihood of interaction between subject-object pairs. Through Pair Affinity Learning and Scoring (PALS), pair affinity is incorporated into inferencetime ranking and further integrated into contextual reasoning through Pair Affinity Modulation (PAM), enabling the model to suppress noninteractive pairs and focus on relationally meaningful ones. To provide cleaner supervision for pair affinity learning, we further propose Relation- Aware Matching (RAM), which leverages vision-language grounding to resolve class-level ambiguity in pseudo-label generation. Extensive experiments on Action Genome demonstrate that our approach consistently yields substantial improvements across different baselines and backbones, achieving state-of-the-art WS-VSGG performance.
MonoCLUE : Object-Aware Clustering Enhances Monocular 3D Object Detection
Nov 11, 2025Monocular 3D object detection offers a cost-effective solution for autonomous driving but suffers from ill-posed depth and limited field of view. These constraints cause a lack of geometric cues and reduced accuracy in occluded or truncated scenes. While recent approaches incorporate additional depth information to address geometric ambiguity, they overlook the visual cues crucial for robust recognition. We propose MonoCLUE, which enhances monocular 3D detection by leveraging both local clustering and generalized scene memory of visual features. First, we perform K-means clustering on visual features to capture distinct object-level appearance parts (e.g., bonnet, car roof), improving detection of partially visible objects. The clustered features are propagated across regions to capture objects with similar appearances. Second, we construct a generalized scene memory by aggregating clustered features across images, providing consistent representations that generalize across scenes. This improves object-level feature consistency, enabling stable detection across varying environments. Lastly, we integrate both local cluster features and generalized scene memory into object queries, guiding attention toward informative regions. Exploiting a unified local clustering and generalized scene memory strategy, MonoCLUE enables robust monocular 3D detection under occlusion and limited visibility, achieving state-of-the-art performance on the KITTI benchmark.
CoMoGaussian: Continuous Motion-Aware Gaussian Splatting from Motion-Blurred Images
Mar 07, 20253D Gaussian Splatting (3DGS) has gained significant attention for their high-quality novel view rendering, motivating research to address real-world challenges. A critical issue is the camera motion blur caused by movement during exposure, which hinders accurate 3D scene reconstruction. In this study, we propose CoMoGaussian, a Continuous Motion-Aware Gaussian Splatting that reconstructs precise 3D scenes from motion-blurred images while maintaining real-time rendering speed. Considering the complex motion patterns inherent in real-world camera movements, we predict continuous camera trajectories using neural ordinary differential equations (ODEs). To ensure accurate modeling, we employ rigid body transformations, preserving the shape and size of the object but rely on the discrete integration of sampled frames. To better approximate the continuous nature of motion blur, we introduce a continuous motion refinement (CMR) transformation that refines rigid transformations by incorporating additional learnable parameters. By revisiting fundamental camera theory and leveraging advanced neural ODE techniques, we achieve precise modeling of continuous camera trajectories, leading to improved reconstruction accuracy. Extensive experiments demonstrate state-of-the-art performance both quantitatively and qualitatively on benchmark datasets, which include a wide range of motion blur scenarios, from moderate to extreme blur.
Find First, Track Next: Decoupling Identification and Propagation in Referring Video Object Segmentation
Mar 05, 2025



Referring video object segmentation aims to segment and track a target object in a video using a natural language prompt. Existing methods typically fuse visual and textual features in a highly entangled manner, processing multi-modal information together to generate per-frame masks. However, this approach often struggles with ambiguous target identification, particularly in scenes with multiple similar objects, and fails to ensure consistent mask propagation across frames. To address these limitations, we introduce FindTrack, a novel decoupled framework that separates target identification from mask propagation. FindTrack first adaptively selects a key frame by balancing segmentation confidence and vision-text alignment, establishing a robust reference for the target object. This reference is then utilized by a dedicated propagation module to track and segment the object across the entire video. By decoupling these processes, FindTrack effectively reduces ambiguities in target association and enhances segmentation consistency. We demonstrate that FindTrack outperforms existing methods on public benchmarks.
CoCoGaussian: Leveraging Circle of Confusion for Gaussian Splatting from Defocused Images
Dec 20, 2024



3D Gaussian Splatting (3DGS) has attracted significant attention for its high-quality novel view rendering, inspiring research to address real-world challenges. While conventional methods depend on sharp images for accurate scene reconstruction, real-world scenarios are often affected by defocus blur due to finite depth of field, making it essential to account for realistic 3D scene representation. In this study, we propose CoCoGaussian, a Circle of Confusion-aware Gaussian Splatting that enables precise 3D scene representation using only defocused images. CoCoGaussian addresses the challenge of defocus blur by modeling the Circle of Confusion (CoC) through a physically grounded approach based on the principles of photographic defocus. Exploiting 3D Gaussians, we compute the CoC diameter from depth and learnable aperture information, generating multiple Gaussians to precisely capture the CoC shape. Furthermore, we introduce a learnable scaling factor to enhance robustness and provide more flexibility in handling unreliable depth in scenes with reflective or refractive surfaces. Experiments on both synthetic and real-world datasets demonstrate that CoCoGaussian achieves state-of-the-art performance across multiple benchmarks.
Does Low Spoilage Under Cold Conditions Foster Cultural Complexity During the Foraging Era? -- A Theoretical and Computational Inquiry
Dec 12, 2024Human cultural complexity did not arise in a vacuum. Scholars in the humanities and social sciences have long debated how ecological factors, such as climate and resource availability, enabled early hunter-gatherers to allocate time and energy beyond basic subsistence tasks. This paper presents a formal, interdisciplinary approach that integrates theoretical modeling with computational methods to examine whether conditions that allow lower spoilage of stored food, often associated with colder climates and abundant large fauna, could indirectly foster the emergence of cultural complexity. Our contribution is twofold. First, we propose a mathematical framework that relates spoilage rates, yield levels, resource management skills, and cultural activities. Under this framework, we prove that lower spoilage and adequate yields reduce the frequency of hunting, thus freeing substantial time for cultural pursuits. Second, we implement a reinforcement learning simulation, inspired by engineering optimization techniques, to validate the theoretical predictions. By training agents in different $(Y,p)$ environments, where $Y$ is yield and $p$ is the probability of daily spoilage, we observe patterns consistent with the theoretical model: stable conditions with lower spoilage strongly correlate with increased cultural complexity. While we do not claim to replicate prehistoric social realities directly, our results suggest that ecologically stable niches provided a milieu in which cultural forms could germinate and evolve. This study, therefore, offers an integrative perspective that unites humanistic inquiries into the origins of culture with the formal rigor and exploratory power of computational modeling.
STATIC : Surface Temporal Affine for TIme Consistency in Video Monocular Depth Estimation
Dec 02, 2024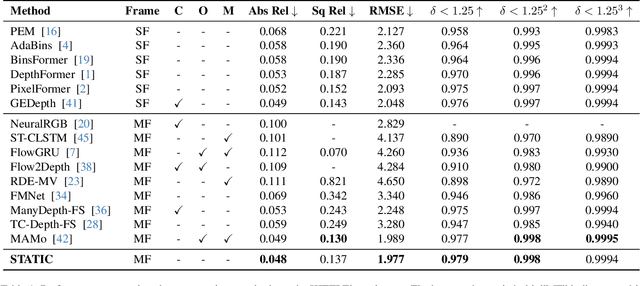


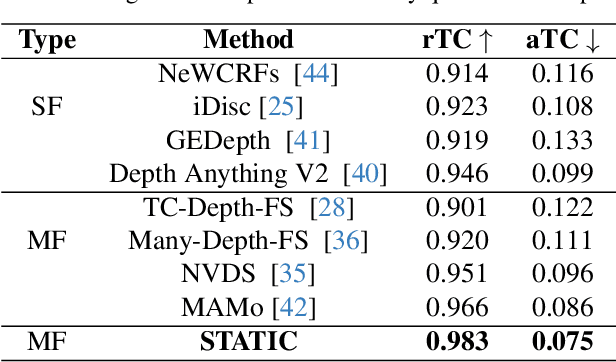
Video monocular depth estimation is essential for applications such as autonomous driving, AR/VR, and robotics. Recent transformer-based single-image monocular depth estimation models perform well on single images but struggle with depth consistency across video frames. Traditional methods aim to improve temporal consistency using multi-frame temporal modules or prior information like optical flow and camera parameters. However, these approaches face issues such as high memory use, reduced performance with dynamic or irregular motion, and limited motion understanding. We propose STATIC, a novel model that independently learns temporal consistency in static and dynamic area without additional information. A difference mask from surface normals identifies static and dynamic area by measuring directional variance. For static area, the Masked Static (MS) module enhances temporal consistency by focusing on stable regions. For dynamic area, the Surface Normal Similarity (SNS) module aligns areas and enhances temporal consistency by measuring feature similarity between frames. A final refinement integrates the independently learned static and dynamic area, enabling STATIC to achieve temporal consistency across the entire sequence. Our method achieves state-of-the-art video depth estimation on the KITTI and NYUv2 datasets without additional information.