 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideo Diffusion Models are Strong Video Inpainter
Aug 21, 2024



Propagation-based video inpainting using optical flow at the pixel or feature level has recently garnered significant attention. However, it has limitations such as the inaccuracy of optical flow prediction and the propagation of noise over time. These issues result in non-uniform noise and time consistency problems throughout the video, which are particularly pronounced when the removed area is large and involves substantial movement. To address these issues, we propose a novel First Frame Filling Video Diffusion Inpainting model (FFF-VDI). We design FFF-VDI inspired by the capabilities of pre-trained image-to-video diffusion models that can transform the first frame image into a highly natural video. To apply this to the video inpainting task, we propagate the noise latent information of future frames to fill the masked areas of the first frame's noise latent code. Next, we fine-tune the pre-trained image-to-video diffusion model to generate the inpainted video. The proposed model addresses the limitations of existing methods that rely on optical flow quality, producing much more natural and temporally consistent videos. This proposed approach is the first to effectively integrate image-to-video diffusion models into video inpainting tasks. Through various comparative experiments, we demonstrate that the proposed model can robustly handle diverse inpainting types with high quality.
DP-NeRF: Deblurred Neural Radiance Field with Physical Scene Priors
Dec 02, 2022



Neural Radiance Field(NeRF) has exhibited outstanding three-dimensional(3D) reconstruction quality via the novel view synthesis from multi-view images and paired calibrated camera parameters. However, previous NeRF-based systems have been demonstrated under strictly controlled settings, with little attention paid to less ideal scenarios, including with the presence of noise such as exposure, illumination changes, and blur. In particular, though blur frequently occurs in real situations, NeRF that can handle blurred images has received little attention. The few studies that have investigated NeRF for blurred images have not considered geometric and appearance consistency in 3D space, which is one of the most important factors in 3D reconstruction. This leads to inconsistency and the degradation of the perceptual quality of the constructed scene. Hence, this paper proposes a DP-NeRF, a novel clean NeRF framework for blurred images, which is constrained with two physical priors. These priors are derived from the actual blurring process during image acquisition by the camera. DP-NeRF proposes rigid blurring kernel to impose 3D consistency utilizing the physical priors and adaptive weight proposal to refine the color composition error in consideration of the relationship between depth and blur. We present extensive experimental results for synthetic and real scenes with two types of blur: camera motion blur and defocus blur. The results demonstrate that DP-NeRF successfully improves the perceptual quality of the constructed NeRF ensuring 3D geometric and appearance consistency. We further demonstrate the effectiveness of our model with comprehensive ablation analysis.
Expanded Adaptive Scaling Normalization for End to End Image Compression
Aug 05, 2022Recently, learning-based image compression methods that utilize convolutional neural layers have been developed rapidly. Rescaling modules such as batch normalization which are often used in convolutional neural networks do not operate adaptively for the various inputs. Therefore, Generalized Divisible Normalization(GDN) has been widely used in image compression to rescale the input features adaptively across both spatial and channel axes. However, the representation power or degree of freedom of GDN is severely limited. Additionally, GDN cannot consider the spatial correlation of an image. To handle the limitations of GDN, we construct an expanded form of the adaptive scaling module, named Expanded Adaptive Scaling Normalization(EASN). First, we exploit the swish function to increase the representation ability. Then, we increase the receptive field to make the adaptive rescaling module consider the spatial correlation. Furthermore, we introduce an input mapping function to give the module a higher degree of freedom. We demonstrate how our EASN works in an image compression network using the visualization results of the feature map, and we conduct extensive experiments to show that our EASN increases the rate-distortion performance remarkably, and even outperforms the VVC intra at a high bit rate.
Beyond Natural Motion: Exploring Discontinuity for Video Frame Interpolation
Feb 17, 2022



Video interpolation is the task that synthesizes the intermediate frame given two consecutive frames. Most of the previous studies have focused on appropriate frame warping operations and refinement modules for the warped frames. These studies have been conducted on natural videos having only continuous motions. However, many practical videos contain a lot of discontinuous motions, such as chat windows, watermarks, GUI elements, or subtitles. We propose three techniques to expand the concept of transition between two consecutive frames to address these issues. First is a new architecture that can separate continuous and discontinuous motion areas. We also propose a novel data augmentation strategy called figure-text mixing (FTM) to make our model learn more general scenarios. Finally, we propose loss functions to give supervisions of the discontinuous motion areas with the data augmentation. We collected a special dataset consisting of some mobile games and chatting videos. We show that our method significantly improves the interpolation qualities of the videos on the special dataset. Moreover, our model outperforms the state-of-the-art methods for natural video datasets containing only continuous motions, such as DAVIS and UCF101.
Test-Time Adaptation for Out-of-distributed Image Inpainting
Feb 02, 2021
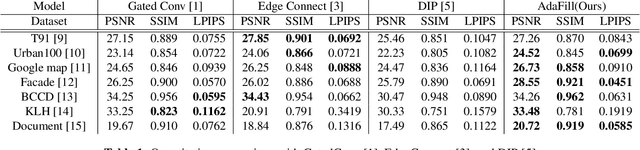
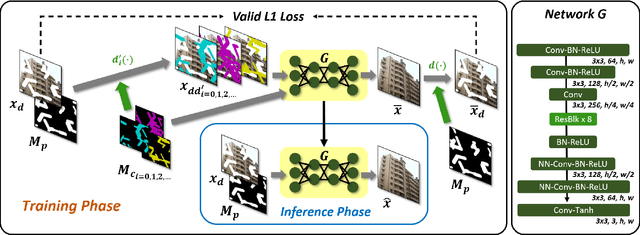
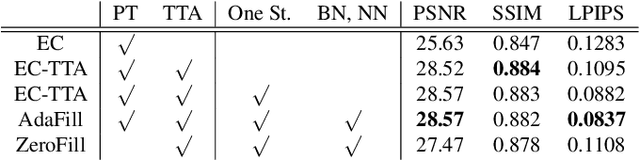
Deep learning-based image inpainting algorithms have shown great performance via powerful learned prior from the numerous external natural images. However, they show unpleasant results on the test image whose distribution is far from the that of training images because their models are biased toward the training images. In this paper, we propose a simple image inpainting algorithm with test-time adaptation named AdaFill. Given a single out-of-distributed test image, our goal is to complete hole region more naturally than the pre-trained inpainting models. To achieve this goal, we treat remained valid regions of the test image as another training cues because natural images have strong internal similarities. From this test-time adaptation, our network can exploit externally learned image priors from the pre-trained features as well as the internal prior of the test image explicitly. Experimental results show that AdaFill outperforms other models on the various out-of-distribution test images. Furthermore, the model named ZeroFill, that are not pre-trained also sometimes outperforms the pre-trained models.