 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExpanded Adaptive Scaling Normalization for End to End Image Compression
Aug 05, 2022Recently, learning-based image compression methods that utilize convolutional neural layers have been developed rapidly. Rescaling modules such as batch normalization which are often used in convolutional neural networks do not operate adaptively for the various inputs. Therefore, Generalized Divisible Normalization(GDN) has been widely used in image compression to rescale the input features adaptively across both spatial and channel axes. However, the representation power or degree of freedom of GDN is severely limited. Additionally, GDN cannot consider the spatial correlation of an image. To handle the limitations of GDN, we construct an expanded form of the adaptive scaling module, named Expanded Adaptive Scaling Normalization(EASN). First, we exploit the swish function to increase the representation ability. Then, we increase the receptive field to make the adaptive rescaling module consider the spatial correlation. Furthermore, we introduce an input mapping function to give the module a higher degree of freedom. We demonstrate how our EASN works in an image compression network using the visualization results of the feature map, and we conduct extensive experiments to show that our EASN increases the rate-distortion performance remarkably, and even outperforms the VVC intra at a high bit rate.
Beyond Natural Motion: Exploring Discontinuity for Video Frame Interpolation
Feb 17, 2022



Video interpolation is the task that synthesizes the intermediate frame given two consecutive frames. Most of the previous studies have focused on appropriate frame warping operations and refinement modules for the warped frames. These studies have been conducted on natural videos having only continuous motions. However, many practical videos contain a lot of discontinuous motions, such as chat windows, watermarks, GUI elements, or subtitles. We propose three techniques to expand the concept of transition between two consecutive frames to address these issues. First is a new architecture that can separate continuous and discontinuous motion areas. We also propose a novel data augmentation strategy called figure-text mixing (FTM) to make our model learn more general scenarios. Finally, we propose loss functions to give supervisions of the discontinuous motion areas with the data augmentation. We collected a special dataset consisting of some mobile games and chatting videos. We show that our method significantly improves the interpolation qualities of the videos on the special dataset. Moreover, our model outperforms the state-of-the-art methods for natural video datasets containing only continuous motions, such as DAVIS and UCF101.
Smoother Network Tuning and Interpolation for Continuous-level Image Processing
Oct 05, 2020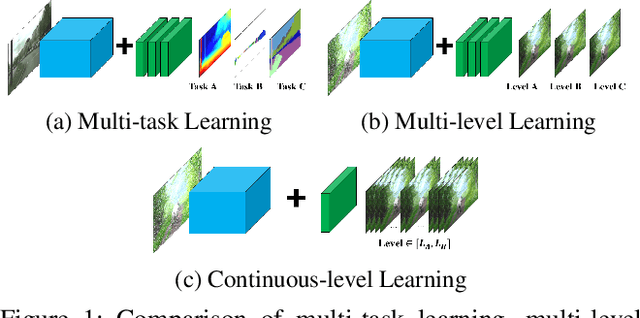
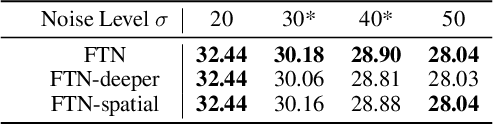
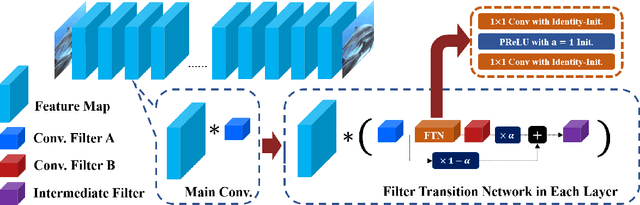
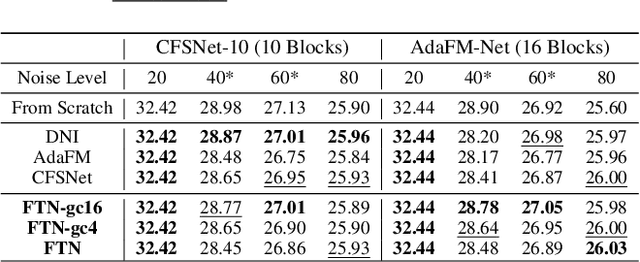
In Convolutional Neural Network (CNN) based image processing, most studies propose networks that are optimized to single-level (or single-objective); thus, they underperform on other levels and must be retrained for delivery of optimal performance. Using multiple models to cover multiple levels involves very high computational costs. To solve these problems, recent approaches train networks on two different levels and propose their own interpolation methods to enable arbitrary intermediate levels. However, many of them fail to generalize or have certain side effects in practical usage. In this paper, we define these frameworks as network tuning and interpolation and propose a novel module for continuous-level learning, called Filter Transition Network (FTN). This module is a structurally smoother module than existing ones. Therefore, the frameworks with FTN generalize well across various tasks and networks and cause fewer undesirable side effects. For stable learning of FTN, we additionally propose a method to initialize non-linear neural network layers with identity mappings. Extensive results for various image processing tasks indicate that the performance of FTN is comparable in multiple continuous levels, and is significantly smoother and lighter than that of other frameworks.
Enhanced Standard Compatible Image Compression Framework based on Auxiliary Codec Networks
Sep 30, 2020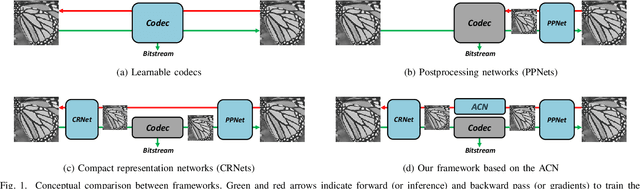
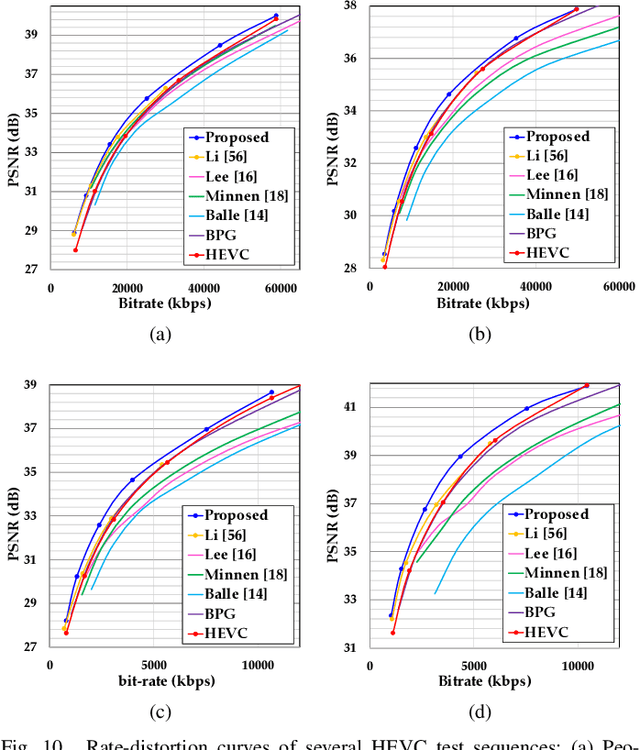
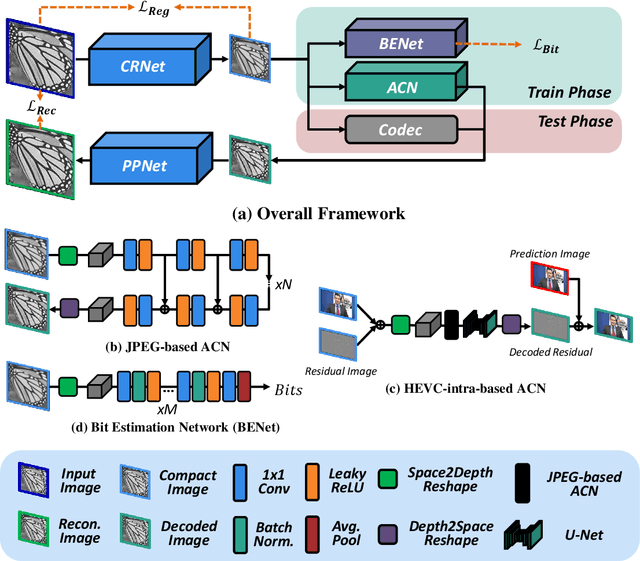
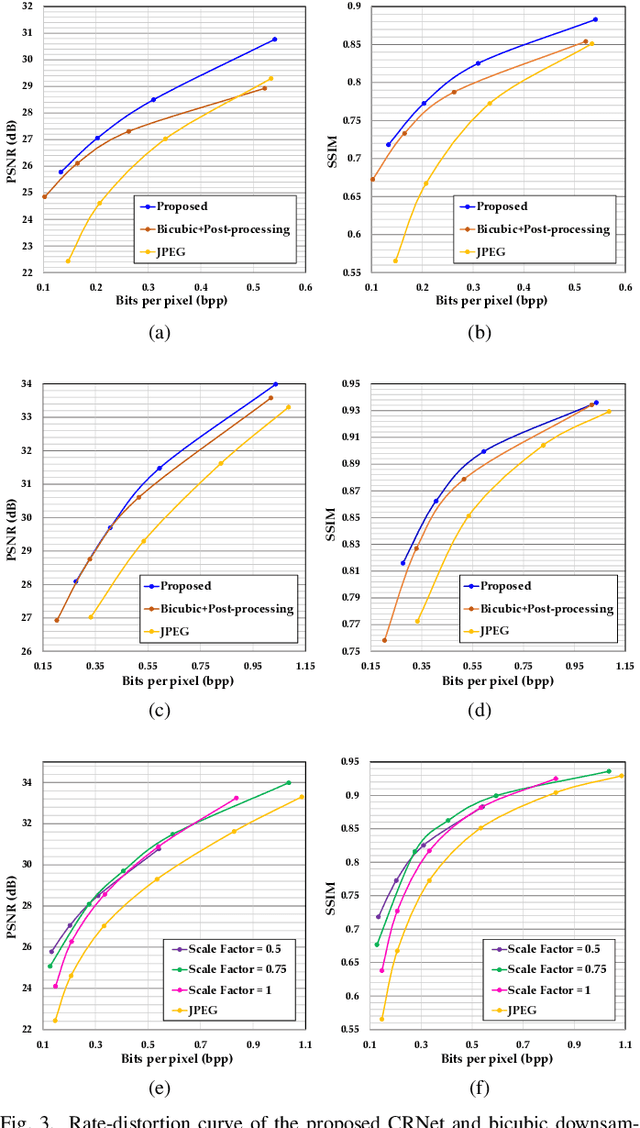
To enhance image compression performance, recent deep neural network-based research can be divided into three categories: a learnable codec, a postprocessing network, and a compact representation network. The learnable codec has been designed for an end-to-end learning beyond the conventional compression modules. The postprocessing network increases the quality of decoded images using an example-based learning. The compact representation network is learned to reduce the capacity of an input image to reduce the bitrate while keeping the quality of the decoded image. However, these approaches are not compatible with the existing codecs or not optimal to increase the coding efficiency. Specifically, it is difficult to achieve optimal learning in the previous studies using the compact representation network, due to the inaccurate consideration of the codecs. In this paper, we propose a novel standard compatible image compression framework based on Auxiliary Codec Networks (ACNs). ACNs are designed to imitate image degradation operations of the existing codec, which delivers more accurate gradients to the compact representation network. Therefore, the compact representation and the postprocessing networks can be learned effectively and optimally. We demonstrate that our proposed framework based on JPEG and High Efficiency Video Coding (HEVC) standard substantially outperforms existing image compression algorithms in a standard compatible manner.
Regularized Adaptation for Stable and Efficient Continuous-Level Learning on Image Processing Networks
Mar 12, 2020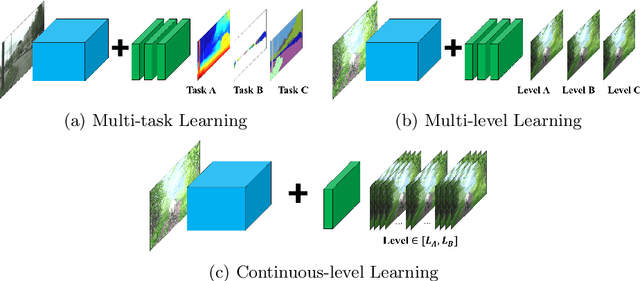

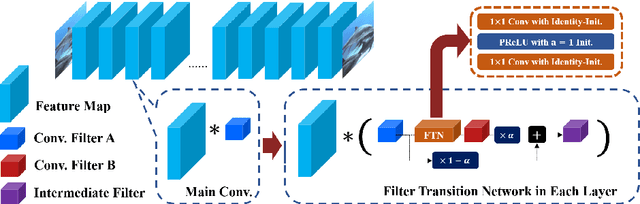

In Convolutional Neural Network (CNN) based image processing, most of the studies propose networks that are optimized for a single-level (or a single-objective); thus, they underperform on other levels and must be retrained for delivery of optimal performance. Using multiple models to cover multiple levels involves very high computational costs. To solve these problems, recent approaches train the networks on two different levels and propose their own interpolation methods to enable the arbitrary intermediate levels. However, many of them fail to adapt hard tasks or interpolate smoothly, or the others still require large memory and computational cost. In this paper, we propose a novel continuous-level learning framework using a Filter Transition Network (FTN) which is a non-linear module that easily adapt to new levels, and is regularized to prevent undesirable side-effects. Additionally, for stable learning of FTN, we newly propose a method to initialize non-linear CNNs with identity mappings. Furthermore, FTN is extremely lightweight module since it is a data-independent module, which means it is not affected by the spatial resolution of the inputs. Extensive results for various image processing tasks indicate that the performance of FTN is stable in terms of adaptation and interpolation, and comparable to that of the other heavy frameworks.