 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTT: Stateful Tracking with Transformers for Autonomous Driving
Apr 30, 2024Tracking objects in three-dimensional space is critical for autonomous driving. To ensure safety while driving, the tracker must be able to reliably track objects across frames and accurately estimate their states such as velocity and acceleration in the present. Existing works frequently focus on the association task while either neglecting the model performance on state estimation or deploying complex heuristics to predict the states. In this paper, we propose STT, a Stateful Tracking model built with Transformers, that can consistently track objects in the scenes while also predicting their states accurately. STT consumes rich appearance, geometry, and motion signals through long term history of detections and is jointly optimized for both data association and state estimation tasks. Since the standard tracking metrics like MOTA and MOTP do not capture the combined performance of the two tasks in the wider spectrum of object states, we extend them with new metrics called S-MOTA and MOTPS that address this limitation. STT achieves competitive real-time performance on the Waymo Open Dataset.
One-Shot Video Inpainting
Feb 28, 2023Recently, removing objects from videos and filling in the erased regions using deep video inpainting (VI) algorithms has attracted considerable attention. Usually, a video sequence and object segmentation masks for all frames are required as the input for this task. However, in real-world applications, providing segmentation masks for all frames is quite difficult and inefficient. Therefore, we deal with VI in a one-shot manner, which only takes the initial frame's object mask as its input. Although we can achieve that using naive combinations of video object segmentation (VOS) and VI methods, they are sub-optimal and generally cause critical errors. To address that, we propose a unified pipeline for one-shot video inpainting (OSVI). By jointly learning mask prediction and video completion in an end-to-end manner, the results can be optimal for the entire task instead of each separate module. Additionally, unlike the two stage methods that use the predicted masks as ground truth cues, our method is more reliable because the predicted masks can be used as the network's internal guidance. On the synthesized datasets for OSVI, our proposed method outperforms all others both quantitatively and qualitatively.
Expanded Adaptive Scaling Normalization for End to End Image Compression
Aug 05, 2022Recently, learning-based image compression methods that utilize convolutional neural layers have been developed rapidly. Rescaling modules such as batch normalization which are often used in convolutional neural networks do not operate adaptively for the various inputs. Therefore, Generalized Divisible Normalization(GDN) has been widely used in image compression to rescale the input features adaptively across both spatial and channel axes. However, the representation power or degree of freedom of GDN is severely limited. Additionally, GDN cannot consider the spatial correlation of an image. To handle the limitations of GDN, we construct an expanded form of the adaptive scaling module, named Expanded Adaptive Scaling Normalization(EASN). First, we exploit the swish function to increase the representation ability. Then, we increase the receptive field to make the adaptive rescaling module consider the spatial correlation. Furthermore, we introduce an input mapping function to give the module a higher degree of freedom. We demonstrate how our EASN works in an image compression network using the visualization results of the feature map, and we conduct extensive experiments to show that our EASN increases the rate-distortion performance remarkably, and even outperforms the VVC intra at a high bit rate.
Beyond Natural Motion: Exploring Discontinuity for Video Frame Interpolation
Feb 17, 2022



Video interpolation is the task that synthesizes the intermediate frame given two consecutive frames. Most of the previous studies have focused on appropriate frame warping operations and refinement modules for the warped frames. These studies have been conducted on natural videos having only continuous motions. However, many practical videos contain a lot of discontinuous motions, such as chat windows, watermarks, GUI elements, or subtitles. We propose three techniques to expand the concept of transition between two consecutive frames to address these issues. First is a new architecture that can separate continuous and discontinuous motion areas. We also propose a novel data augmentation strategy called figure-text mixing (FTM) to make our model learn more general scenarios. Finally, we propose loss functions to give supervisions of the discontinuous motion areas with the data augmentation. We collected a special dataset consisting of some mobile games and chatting videos. We show that our method significantly improves the interpolation qualities of the videos on the special dataset. Moreover, our model outperforms the state-of-the-art methods for natural video datasets containing only continuous motions, such as DAVIS and UCF101.
Predicting post-operative right ventricular failure using video-based deep learning
Feb 28, 2021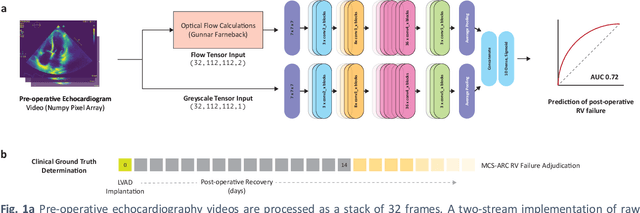
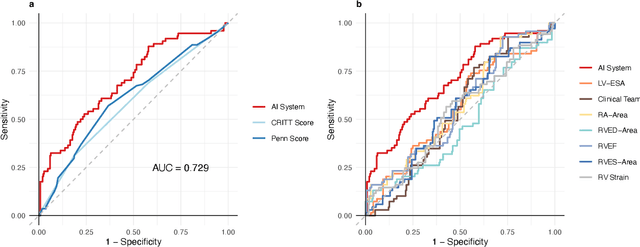
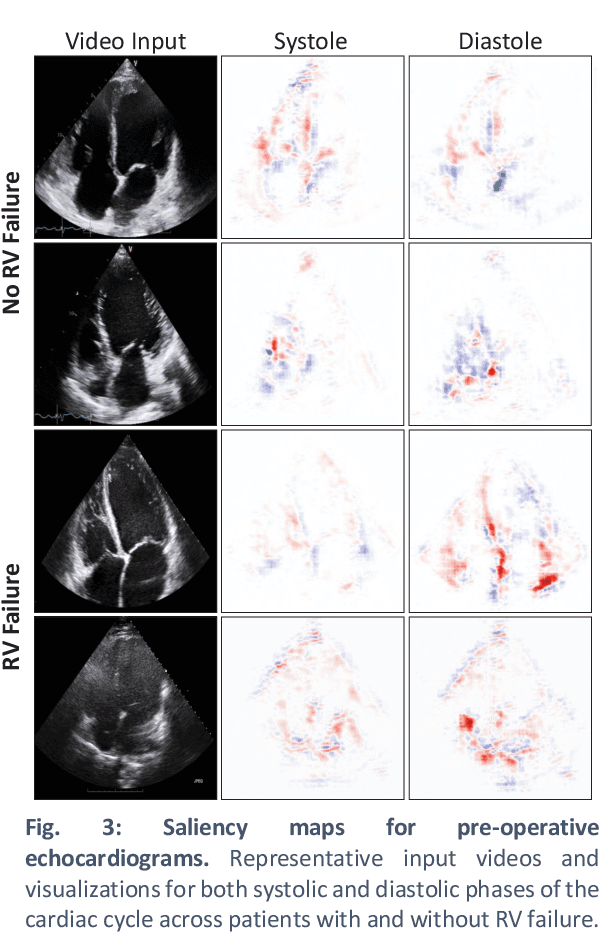
Non-invasive and cost effective in nature, the echocardiogram allows for a comprehensive assessment of the cardiac musculature and valves. Despite progressive improvements over the decades, the rich temporally resolved data in echocardiography videos remain underutilized. Human reads of echocardiograms reduce the complex patterns of cardiac wall motion, to a small list of measurements of heart function. Furthermore, all modern echocardiography artificial intelligence (AI) systems are similarly limited by design - automating measurements of the same reductionist metrics rather than utilizing the wealth of data embedded within each echo study. This underutilization is most evident in situations where clinical decision making is guided by subjective assessments of disease acuity, and tools that predict disease onset within clinically actionable timeframes are unavailable. Predicting the likelihood of developing post-operative right ventricular failure (RV failure) in the setting of mechanical circulatory support is one such clinical example. To address this, we developed a novel video AI system trained to predict post-operative right ventricular failure (RV failure), using the full spatiotemporal density of information from pre-operative echocardiography scans. We achieve an AUC of 0.729, specificity of 52% at 80% sensitivity and 46% sensitivity at 80% specificity. Furthermore, we show that our ML system significantly outperforms a team of human experts tasked with predicting RV failure on independent clinical evaluation. Finally, the methods we describe are generalizable to any cardiac clinical decision support application where treatment or patient selection is guided by qualitative echocardiography assessments.
Test-Time Adaptation for Out-of-distributed Image Inpainting
Feb 02, 2021
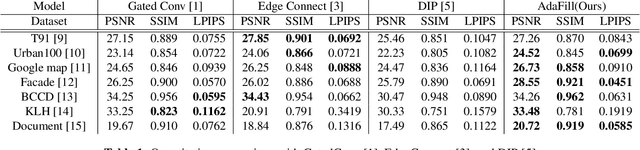
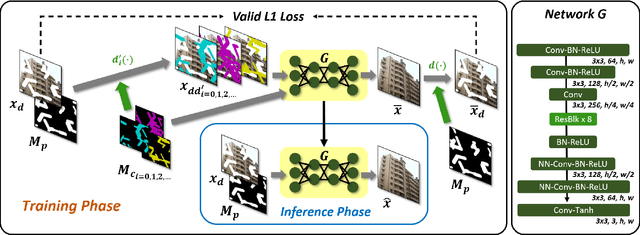
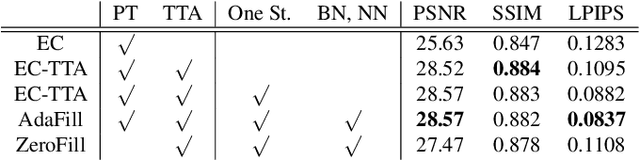
Deep learning-based image inpainting algorithms have shown great performance via powerful learned prior from the numerous external natural images. However, they show unpleasant results on the test image whose distribution is far from the that of training images because their models are biased toward the training images. In this paper, we propose a simple image inpainting algorithm with test-time adaptation named AdaFill. Given a single out-of-distributed test image, our goal is to complete hole region more naturally than the pre-trained inpainting models. To achieve this goal, we treat remained valid regions of the test image as another training cues because natural images have strong internal similarities. From this test-time adaptation, our network can exploit externally learned image priors from the pre-trained features as well as the internal prior of the test image explicitly. Experimental results show that AdaFill outperforms other models on the various out-of-distribution test images. Furthermore, the model named ZeroFill, that are not pre-trained also sometimes outperforms the pre-trained models.
Extrapolative-Interpolative Cycle-Consistency Learning for Video Frame Extrapolation
May 27, 2020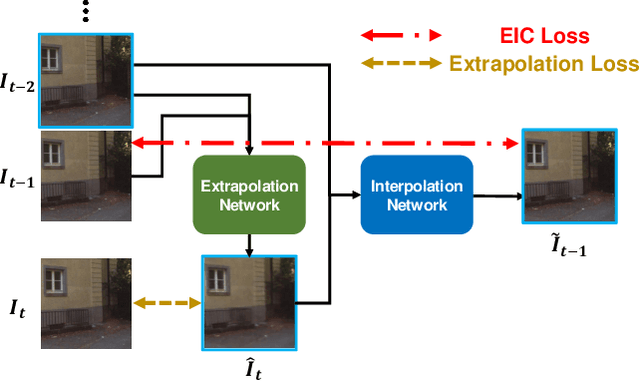

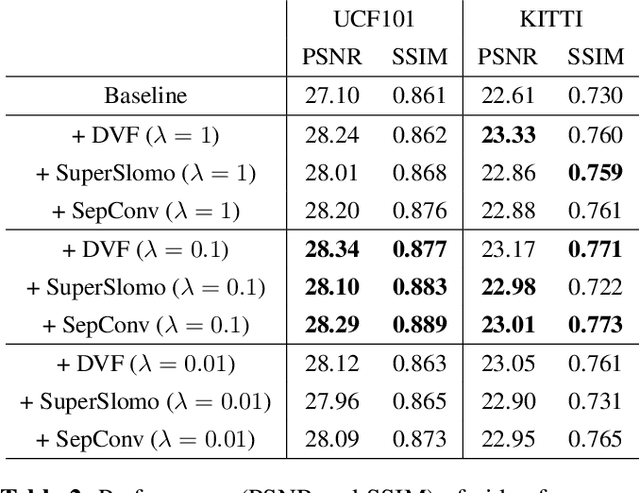

Video frame extrapolation is a task to predict future frames when the past frames are given. Unlike previous studies that usually have been focused on the design of modules or construction of networks, we propose a novel Extrapolative-Interpolative Cycle (EIC) loss using pre-trained frame interpolation module to improve extrapolation performance. Cycle-consistency loss has been used for stable prediction between two function spaces in many visual tasks. We formulate this cycle-consistency using two mapping functions; frame extrapolation and interpolation. Since it is easier to predict intermediate frames than to predict future frames in terms of the object occlusion and motion uncertainty, interpolation module can give guidance signal effectively for training the extrapolation function. EIC loss can be applied to any existing extrapolation algorithms and guarantee consistent prediction in the short future as well as long future frames. Experimental results show that simply adding EIC loss to the existing baseline increases extrapolation performance on both UCF101 and KITTI datasets.