 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLabOSBench: Benchmarking Computer Use Agents for Scientific Instrument Control
Jun 15, 2026Current computer-use benchmarks primarily focus on software operation tasks in virtualized systems, whereas scientific instrumentation scenarios require coordinated control over complex interfaces, and feedback-driven parameter adjustment. However, directly evaluating agents on physical high-precision instruments is impractical due to high cost, safety risks, limited accessibility, and difficulty in ensuring reproducible evaluation. This motivates the need for a simulated yet realistic testbed that preserves the operational challenges of scientific instruments while enabling scalable and safe benchmarking. To this end, we introduce LabOSBench, a challenging benchmark for multimodal GUI agents built on a suite of web-based scientific-instrument simulators. Operating directly via a browser, LabOSBench avoids resource-heavy OS virtualization while supporting flexible task configuration and execution-based evaluation. Specifically, LabOSBench constructs 96 subtasks across eight instrument simulators, covering workflows from sample loading, alignment, parameter tuning, and data acquisition to result inspection. We evaluate general-purpose vision-language models, specialized GUI agent models, and advanced agentic frameworks at both subtask and end-to-end levels. Our experiments reveal that while existing agents can complete many structured GUI subtasks, they still struggle with feedback-driven operations and long-horizon workflow execution. Overall, LabOSBench provides a reproducible, low-cost testbed for advancing computer-using agents toward scientific-instrument control.
Owl-AuraID 1.0: An Intelligent System for Autonomous Scientific Instrumentation and Scientific Data Analysis
Mar 31, 2026Scientific discovery increasingly depends on high-throughput characterization, yet automation is hindered by proprietary GUIs and the limited generalizability of existing API-based systems. We present Owl-AuraID, a software-hardware collaborative embodied agent system that adopts a GUI-native paradigm to operate instruments through the same interfaces as human experts. Its skill-centric framework integrates Type-1 (GUI operation) and Type-2 (data analysis) skills into end-to-end workflows, connecting physical sample handling with scientific interpretation. Owl-AuraID demonstrates broad coverage across ten categories of precision instruments and diverse workflows, including multimodal spectral analysis, microscopic imaging, and crystallographic analysis, supporting modalities such as FTIR, NMR, AFM, and TGA. Overall, Owl-AuraID provides a practical, extensible foundation for autonomous laboratories and illustrates a path toward evolving laboratory intelligence through reusable operational and analytical skills. The code are available at https://github.com/OpenOwlab/AuraID.
SciEvalKit: An Open-source Evaluation Toolkit for Scientific General Intelligence
Dec 30, 2025We introduce SciEvalKit, a unified benchmarking toolkit designed to evaluate AI models for science across a broad range of scientific disciplines and task capabilities. Unlike general-purpose evaluation platforms, SciEvalKit focuses on the core competencies of scientific intelligence, including Scientific Multimodal Perception, Scientific Multimodal Reasoning, Scientific Multimodal Understanding, Scientific Symbolic Reasoning, Scientific Code Generation, Science Hypothesis Generation and Scientific Knowledge Understanding. It supports six major scientific domains, spanning from physics and chemistry to astronomy and materials science. SciEvalKit builds a foundation of expert-grade scientific benchmarks, curated from real-world, domain-specific datasets, ensuring that tasks reflect authentic scientific challenges. The toolkit features a flexible, extensible evaluation pipeline that enables batch evaluation across models and datasets, supports custom model and dataset integration, and provides transparent, reproducible, and comparable results. By bridging capability-based evaluation and disciplinary diversity, SciEvalKit offers a standardized yet customizable infrastructure to benchmark the next generation of scientific foundation models and intelligent agents. The toolkit is open-sourced and actively maintained to foster community-driven development and progress in AI4Science.
CPRet: A Dataset, Benchmark, and Model for Retrieval in Competitive Programming
May 19, 2025Competitive programming benchmarks are widely used in scenarios such as programming contests and large language model assessments. However, the growing presence of duplicate or highly similar problems raises concerns not only about competition fairness, but also about the validity of competitive programming as a benchmark for model evaluation. In this paper, we propose a new problem -- similar question retrieval -- to address this issue. Due to the lack of both data and models, solving this problem is challenging. To this end, we introduce CPRet, a retrieval-oriented benchmark suite for competitive programming, covering four retrieval tasks: two code-centric (i.e., Text-to-Code and Code-to-Code) and two newly proposed problem-centric tasks (i.e., Problem-to-Duplicate and Simplified-to-Full), built from a combination of automatically crawled problem-solution data and manually curated annotations. Our contribution includes both high-quality training data and temporally separated test sets for reliable evaluation. In addition, we develop two task-specialized retrievers based on this dataset: CPRetriever-Code, trained with a novel Group-InfoNCE loss for problem-code alignment, and CPRetriever-Prob, fine-tuned for identifying problem-level similarity. Both models achieve strong results and are open-sourced for local use. Finally, we analyze LiveCodeBench and find that high-similarity problems inflate model pass rates and reduce differentiation, underscoring the need for similarity-aware evaluation in future benchmarks. Code and data are available at: https://github.com/coldchair/CPRet
STT: Stateful Tracking with Transformers for Autonomous Driving
Apr 30, 2024Tracking objects in three-dimensional space is critical for autonomous driving. To ensure safety while driving, the tracker must be able to reliably track objects across frames and accurately estimate their states such as velocity and acceleration in the present. Existing works frequently focus on the association task while either neglecting the model performance on state estimation or deploying complex heuristics to predict the states. In this paper, we propose STT, a Stateful Tracking model built with Transformers, that can consistently track objects in the scenes while also predicting their states accurately. STT consumes rich appearance, geometry, and motion signals through long term history of detections and is jointly optimized for both data association and state estimation tasks. Since the standard tracking metrics like MOTA and MOTP do not capture the combined performance of the two tasks in the wider spectrum of object states, we extend them with new metrics called S-MOTA and MOTPS that address this limitation. STT achieves competitive real-time performance on the Waymo Open Dataset.
Depth Estimation Matters Most: Improving Per-Object Depth Estimation for Monocular 3D Detection and Tracking
Jun 08, 2022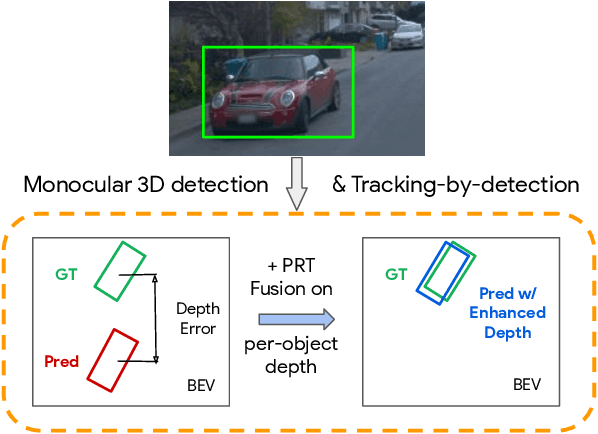
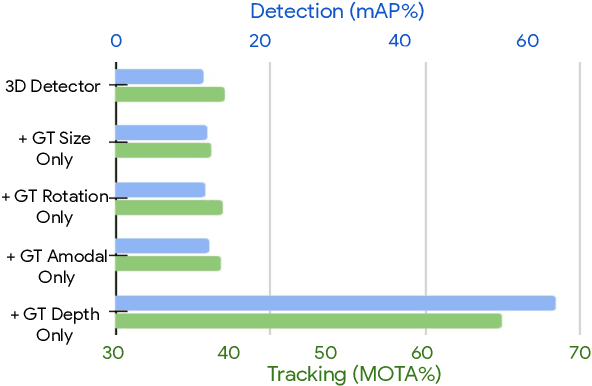
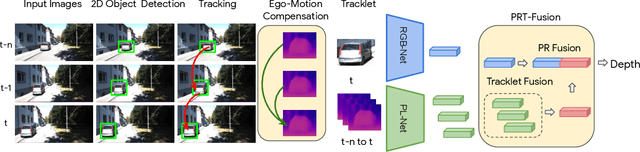
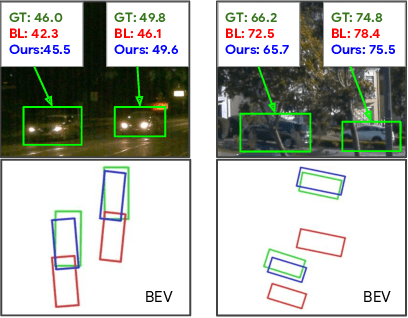
Monocular image-based 3D perception has become an active research area in recent years owing to its applications in autonomous driving. Approaches to monocular 3D perception including detection and tracking, however, often yield inferior performance when compared to LiDAR-based techniques. Through systematic analysis, we identified that per-object depth estimation accuracy is a major factor bounding the performance. Motivated by this observation, we propose a multi-level fusion method that combines different representations (RGB and pseudo-LiDAR) and temporal information across multiple frames for objects (tracklets) to enhance per-object depth estimation. Our proposed fusion method achieves the state-of-the-art performance of per-object depth estimation on the Waymo Open Dataset, the KITTI detection dataset, and the KITTI MOT dataset. We further demonstrate that by simply replacing estimated depth with fusion-enhanced depth, we can achieve significant improvements in monocular 3D perception tasks, including detection and tracking.
Federated Cross Learning for Medical Image Segmentation
Apr 05, 2022
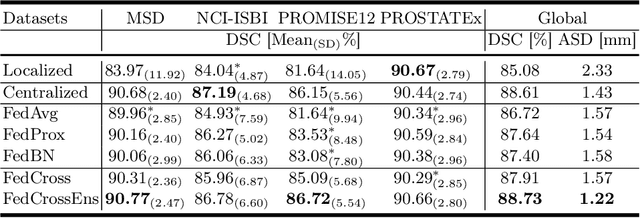

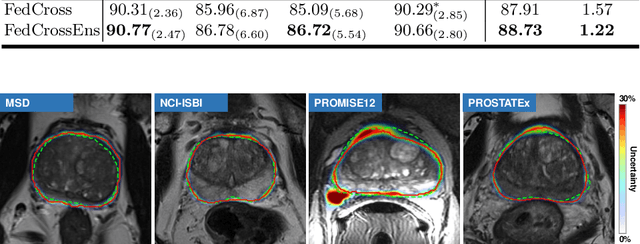
Federated learning (FL) can collaboratively train deep learning models using isolated patient data owned by different hospitals for various clinical applications, including medical image segmentation. However, a major problem of FL is its performance degradation when dealing with the data that are not independently and identically distributed (non-iid), which is often the case in medical images. In this paper, we first conduct a theoretical analysis on the FL algorithm to reveal the problem of model aggregation during training on non-iid data. With the insights gained through the analysis, we propose a simple and yet effective method, federated cross learning (FedCross), to tackle this challenging problem. Unlike the conventional FL methods that combine multiple individually trained local models on a server node, our FedCross sequentially trains the global model across different clients in a round-robin manner, and thus the entire training procedure does not involve any model aggregation steps. To further improve its performance to be comparable with the centralized learning method, we combine the FedCross with an ensemble learning mechanism to compose a federated cross ensemble learning (FedCrossEns) method. Finally, we conduct extensive experiments using a set of public datasets. The experimental results show that the proposed FedCross training strategy outperforms the mainstream FL methods on non-iid data. In addition to improving the segmentation performance, our FedCrossEns can further provide a quantitative estimation of the model uncertainty, demonstrating the effectiveness and clinical significance of our designs. Source code will be made publicly available after paper publication.
SkullEngine: A Multi-stage CNN Framework for Collaborative CBCT Image Segmentation and Landmark Detection
Oct 07, 2021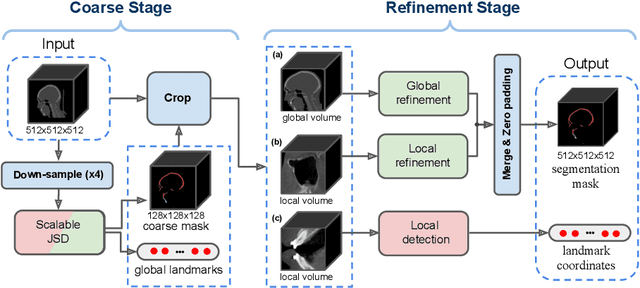

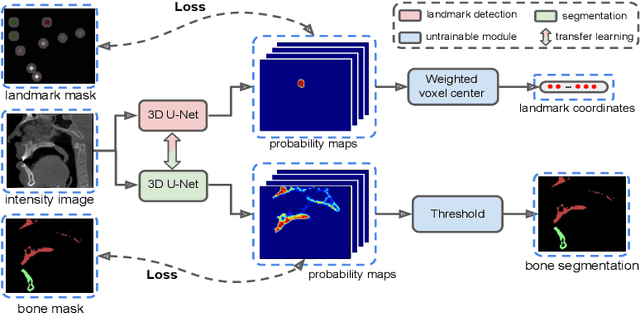

We propose a multi-stage coarse-to-fine CNN-based framework, called SkullEngine, for high-resolution segmentation and large-scale landmark detection through a collaborative, integrated, and scalable JSD model and three segmentation and landmark detection refinement models. We evaluated our framework on a clinical dataset consisting of 170 CBCT/CT images for the task of segmenting 2 bones (midface and mandible) and detecting 175 clinically common landmarks on bones, teeth, and soft tissues.