 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOncoReg: Medical Image Registration for Oncological Challenges
Apr 01, 2025In modern cancer research, the vast volume of medical data generated is often underutilised due to challenges related to patient privacy. The OncoReg Challenge addresses this issue by enabling researchers to develop and validate image registration methods through a two-phase framework that ensures patient privacy while fostering the development of more generalisable AI models. Phase one involves working with a publicly available dataset, while phase two focuses on training models on a private dataset within secure hospital networks. OncoReg builds upon the foundation established by the Learn2Reg Challenge by incorporating the registration of interventional cone-beam computed tomography (CBCT) with standard planning fan-beam CT (FBCT) images in radiotherapy. Accurate image registration is crucial in oncology, particularly for dynamic treatment adjustments in image-guided radiotherapy, where precise alignment is necessary to minimise radiation exposure to healthy tissues while effectively targeting tumours. This work details the methodology and data behind the OncoReg Challenge and provides a comprehensive analysis of the competition entries and results. Findings reveal that feature extraction plays a pivotal role in this registration task. A new method emerging from this challenge demonstrated its versatility, while established approaches continue to perform comparably to newer techniques. Both deep learning and classical approaches still play significant roles in image registration, with the combination of methods - particularly in feature extraction - proving most effective.
Chest X-ray Foundation Model with Global and Local Representations Integration
Feb 07, 2025Chest X-ray (CXR) is the most frequently ordered imaging test, supporting diverse clinical tasks from thoracic disease detection to postoperative monitoring. However, task-specific classification models are limited in scope, require costly labeled data, and lack generalizability to out-of-distribution datasets. To address these challenges, we introduce CheXFound, a self-supervised vision foundation model that learns robust CXR representations and generalizes effectively across a wide range of downstream tasks. We pretrain CheXFound on a curated CXR-1M dataset, comprising over one million unique CXRs from publicly available sources. We propose a Global and Local Representations Integration (GLoRI) module for downstream adaptations, by incorporating disease-specific local features with global image features for enhanced performance in multilabel classification. Our experimental results show that CheXFound outperforms state-of-the-art models in classifying 40 disease findings across different prevalence levels on the CXR-LT 24 dataset and exhibits superior label efficiency on downstream tasks with limited training data. Additionally, CheXFound achieved significant improvements on new tasks with out-of-distribution datasets, including opportunistic cardiovascular disease risk estimation and mortality prediction. These results highlight CheXFound's strong generalization capabilities, enabling diverse adaptations with improved label efficiency. The project source code is publicly available at https://github.com/RPIDIAL/CheXFound.
General Purpose Image Encoder DINOv2 for Medical Image Registration
Feb 24, 2024



Existing medical image registration algorithms rely on either dataset specific training or local texture-based features to align images. The former cannot be reliably implemented without large modality-specific training datasets, while the latter lacks global semantics thus could be easily trapped at local minima. In this paper, we present a training-free deformable image registration method, DINO-Reg, leveraging a general purpose image encoder DINOv2 for image feature extraction. The DINOv2 encoder was trained using the ImageNet data containing natural images. We used the pretrained DINOv2 without any finetuning. Our method feeds the DINOv2 encoded features into a discrete optimizer to find the optimal deformable registration field. We conducted a series of experiments to understand the behavior and role of such a general purpose image encoder in the application of image registration. Combined with handcrafted features, our method won the first place in the recent OncoReg Challenge. To our knowledge, this is the first application of general vision foundation models in medical image registration.
Soft-tissue Driven Craniomaxillofacial Surgical Planning
Jul 20, 2023In CMF surgery, the planning of bony movement to achieve a desired facial outcome is a challenging task. Current bone driven approaches focus on normalizing the bone with the expectation that the facial appearance will be corrected accordingly. However, due to the complex non-linear relationship between bony structure and facial soft-tissue, such bone-driven methods are insufficient to correct facial deformities. Despite efforts to simulate facial changes resulting from bony movement, surgical planning still relies on iterative revisions and educated guesses. To address these issues, we propose a soft-tissue driven framework that can automatically create and verify surgical plans. Our framework consists of a bony planner network that estimates the bony movements required to achieve the desired facial outcome and a facial simulator network that can simulate the possible facial changes resulting from the estimated bony movement plans. By combining these two models, we can verify and determine the final bony movement required for planning. The proposed framework was evaluated using a clinical dataset, and our experimental results demonstrate that the soft-tissue driven approach greatly improves the accuracy and efficacy of surgical planning when compared to the conventional bone-driven approach.
Distance Map Supervised Landmark Localization for MR-TRUS Registration
Oct 11, 2022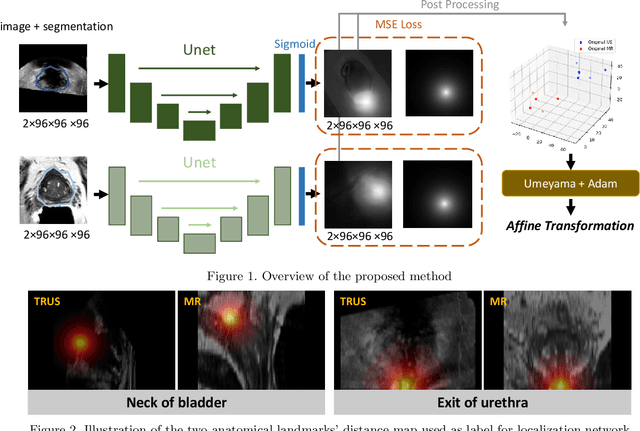
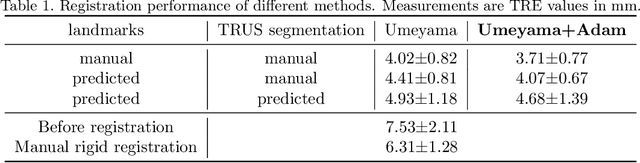

In this work, we propose to explicitly use the landmarks of prostate to guide the MR-TRUS image registration. We first train a deep neural network to automatically localize a set of meaningful landmarks, and then directly generate the affine registration matrix from the location of these landmarks. For landmark localization, instead of directly training a network to predict the landmark coordinates, we propose to regress a full-resolution distance map of the landmark, which is demonstrated effective in avoiding statistical bias to unsatisfactory performance and thus improving performance. We then use the predicted landmarks to generate the affine transformation matrix, which outperforms the clinicians' manual rigid registration by a significant margin in terms of TRE.
Deep Learning-based Facial Appearance Simulation Driven by Surgically Planned Craniomaxillofacial Bony Movement
Oct 04, 2022Simulating facial appearance change following bony movement is a critical step in orthognathic surgical planning for patients with jaw deformities. Conventional biomechanics-based methods such as the finite-element method (FEM) are labor intensive and computationally inefficient. Deep learning-based approaches can be promising alternatives due to their high computational efficiency and strong modeling capability. However, the existing deep learning-based method ignores the physical correspondence between facial soft tissue and bony segments and thus is significantly less accurate compared to FEM. In this work, we propose an Attentive Correspondence assisted Movement Transformation network (ACMT-Net) to estimate the facial appearance by transforming the bony movement to facial soft tissue through a point-to-point attentive correspondence matrix. Experimental results on patients with jaw deformity show that our proposed method can achieve comparable facial change prediction accuracy compared with the state-of-the-art FEM-based approach with significantly improved computational efficiency.
Federated Multi-organ Segmentation with Partially Labeled Data
Jun 14, 2022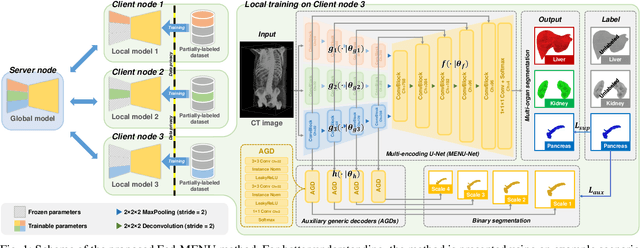
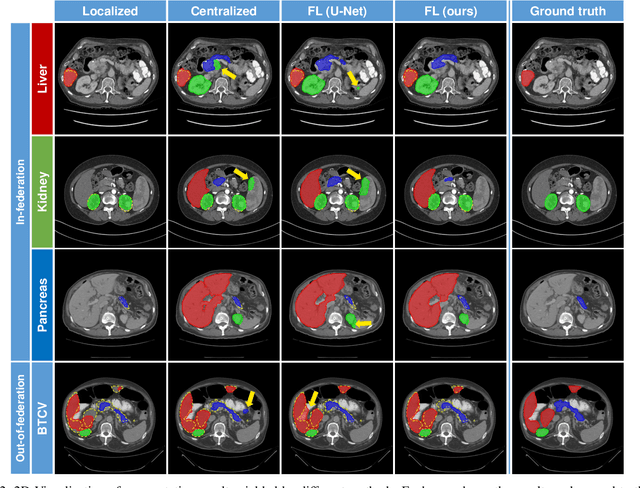
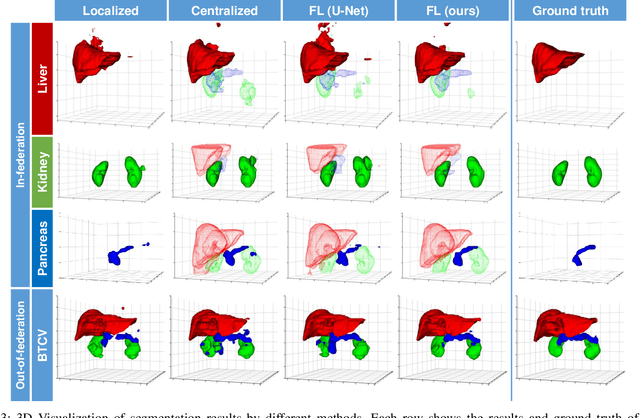
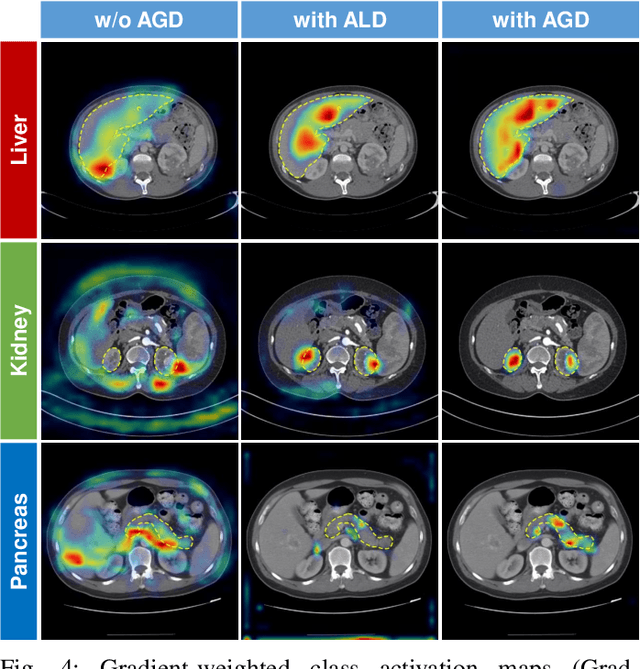
Federated learning is an emerging paradigm allowing large-scale decentralized learning without sharing data across different data owners, which helps address the concern of data privacy in medical image analysis. However, the requirement for label consistency across clients by the existing methods largely narrows its application scope. In practice, each clinical site may only annotate certain organs of interest with partial or no overlap with other sites. Incorporating such partially labeled data into a unified federation is an unexplored problem with clinical significance and urgency. This work tackles the challenge by using a novel federated multi-encoding U-Net (Fed-MENU) method for multi-organ segmentation. In our method, a multi-encoding U-Net (MENU-Net) is proposed to extract organ-specific features through different encoding sub-networks. Each sub-network can be seen as an expert of a specific organ and trained for that client. Moreover, to encourage the organ-specific features extracted by different sub-networks to be informative and distinctive, we regularize the training of the MENU-Net by designing an auxiliary generic decoder (AGD). Extensive experiments on four public datasets show that our Fed-MENU method can effectively obtain a federated learning model using the partially labeled datasets with superior performance to other models trained by either localized or centralized learning methods. Source code will be made publicly available at the time of paper publication.
Federated Cross Learning for Medical Image Segmentation
Apr 05, 2022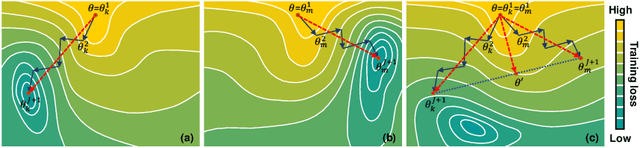
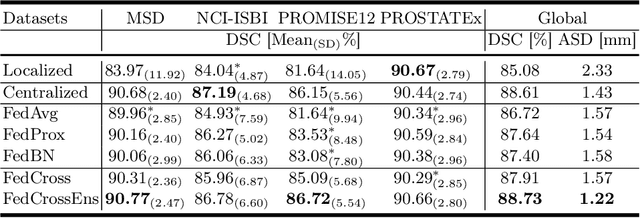

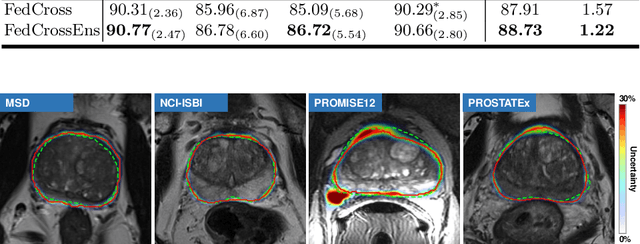
Federated learning (FL) can collaboratively train deep learning models using isolated patient data owned by different hospitals for various clinical applications, including medical image segmentation. However, a major problem of FL is its performance degradation when dealing with the data that are not independently and identically distributed (non-iid), which is often the case in medical images. In this paper, we first conduct a theoretical analysis on the FL algorithm to reveal the problem of model aggregation during training on non-iid data. With the insights gained through the analysis, we propose a simple and yet effective method, federated cross learning (FedCross), to tackle this challenging problem. Unlike the conventional FL methods that combine multiple individually trained local models on a server node, our FedCross sequentially trains the global model across different clients in a round-robin manner, and thus the entire training procedure does not involve any model aggregation steps. To further improve its performance to be comparable with the centralized learning method, we combine the FedCross with an ensemble learning mechanism to compose a federated cross ensemble learning (FedCrossEns) method. Finally, we conduct extensive experiments using a set of public datasets. The experimental results show that the proposed FedCross training strategy outperforms the mainstream FL methods on non-iid data. In addition to improving the segmentation performance, our FedCrossEns can further provide a quantitative estimation of the model uncertainty, demonstrating the effectiveness and clinical significance of our designs. Source code will be made publicly available after paper publication.
OpenKBP-Opt: An international and reproducible evaluation of 76 knowledge-based planning pipelines
Feb 16, 2022

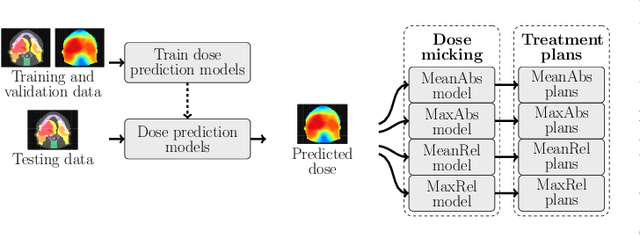
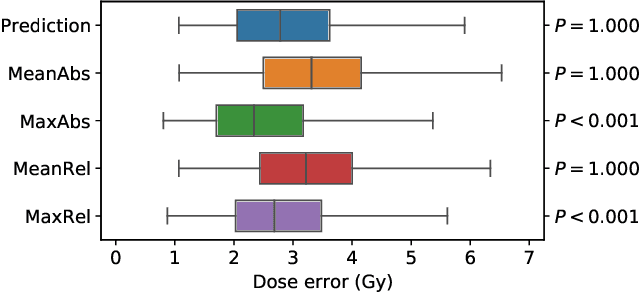
We establish an open framework for developing plan optimization models for knowledge-based planning (KBP) in radiotherapy. Our framework includes reference plans for 100 patients with head-and-neck cancer and high-quality dose predictions from 19 KBP models that were developed by different research groups during the OpenKBP Grand Challenge. The dose predictions were input to four optimization models to form 76 unique KBP pipelines that generated 7600 plans. The predictions and plans were compared to the reference plans via: dose score, which is the average mean absolute voxel-by-voxel difference in dose a model achieved; the deviation in dose-volume histogram (DVH) criterion; and the frequency of clinical planning criteria satisfaction. We also performed a theoretical investigation to justify our dose mimicking models. The range in rank order correlation of the dose score between predictions and their KBP pipelines was 0.50 to 0.62, which indicates that the quality of the predictions is generally positively correlated with the quality of the plans. Additionally, compared to the input predictions, the KBP-generated plans performed significantly better (P<0.05; one-sided Wilcoxon test) on 18 of 23 DVH criteria. Similarly, each optimization model generated plans that satisfied a higher percentage of criteria than the reference plans. Lastly, our theoretical investigation demonstrated that the dose mimicking models generated plans that are also optimal for a conventional planning model. This was the largest international effort to date for evaluating the combination of KBP prediction and optimization models. In the interest of reproducibility, our data and code is freely available at https://github.com/ababier/open-kbp-opt.
End-to-end Ultrasound Frame to Volume Registration
Jul 14, 2021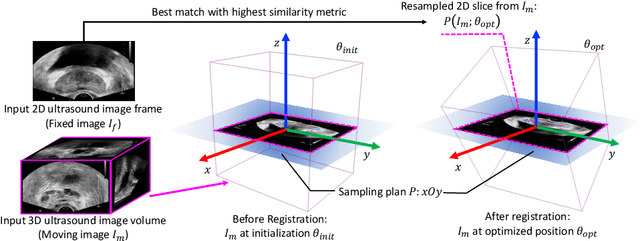
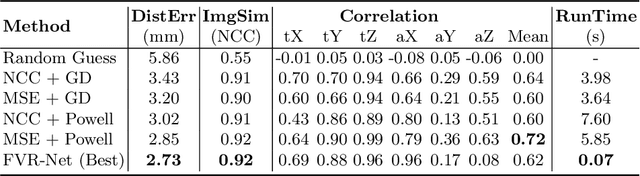
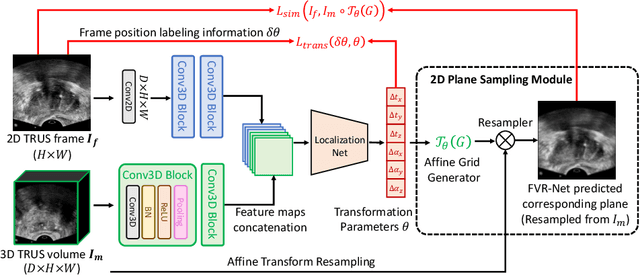
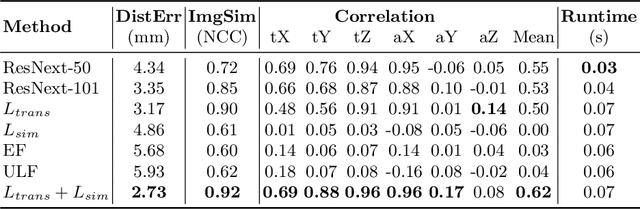
Fusing intra-operative 2D transrectal ultrasound (TRUS) image with pre-operative 3D magnetic resonance (MR) volume to guide prostate biopsy can significantly increase the yield. However, such a multimodal 2D/3D registration problem is a very challenging task. In this paper, we propose an end-to-end frame-to-volume registration network (FVR-Net), which can efficiently bridge the previous research gaps by aligning a 2D TRUS frame with a 3D TRUS volume without requiring hardware tracking. The proposed FVR-Net utilizes a dual-branch feature extraction module to extract the information from TRUS frame and volume to estimate transformation parameters. We also introduce a differentiable 2D slice sampling module which allows gradients backpropagating from an unsupervised image similarity loss for content correspondence learning. Our model shows superior efficiency for real-time interventional guidance with highly competitive registration accuracy.