 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePINNOCHIO: Physics-Informed Neural Network for Coupled Hyperelastic Interface-Volume Simulation in Orthognathic Surgery
Jun 01, 2026Predicting patient-specific facial soft-tissue deformation is critical for iterative orthognathic surgery planning. However, current computational methods face a strict accuracy-efficiency trade-off: high-fidelity Finite Element Methods (FEM) are computationally prohibitive, whereas pure deep learning models often produce biomechanically inconsistent results. While Physics-Informed Neural Networks (PINNs) offer a promising avenue, learning the complex heterogeneous mechanics of bone--soft-tissue interactions with only partial clinical supervision (i.e., outer facial surfaces) remains highly unstable. To overcome these challenges, we present PINNOCHIO, a novel physics-informed framework for facial soft-tissue simulation. PINNOCHIO introduces a hybrid sequential decomposition that explicitly decouples discontinuous bone--soft-tissue interface movements from continuous volumetric hyperelastic deformation. This structural separation enables stable training and facilitates a physics-enabled sim-to-real adaptation strategy, ensuring internal biomechanical consistency without requiring volumetric ground truth. Evaluated on a 40-patient clinical cohort, PINNOCHIO outperforms existing baselines in both surface accuracy and physical validity. Furthermore, it achieves a substantial speedup over FEM, successfully resolving the accuracy-efficiency trade-off to provide a highly reliable and practical tool for interactive surgical planning.
Soft-tissue Driven Craniomaxillofacial Surgical Planning
Jul 20, 2023In CMF surgery, the planning of bony movement to achieve a desired facial outcome is a challenging task. Current bone driven approaches focus on normalizing the bone with the expectation that the facial appearance will be corrected accordingly. However, due to the complex non-linear relationship between bony structure and facial soft-tissue, such bone-driven methods are insufficient to correct facial deformities. Despite efforts to simulate facial changes resulting from bony movement, surgical planning still relies on iterative revisions and educated guesses. To address these issues, we propose a soft-tissue driven framework that can automatically create and verify surgical plans. Our framework consists of a bony planner network that estimates the bony movements required to achieve the desired facial outcome and a facial simulator network that can simulate the possible facial changes resulting from the estimated bony movement plans. By combining these two models, we can verify and determine the final bony movement required for planning. The proposed framework was evaluated using a clinical dataset, and our experimental results demonstrate that the soft-tissue driven approach greatly improves the accuracy and efficacy of surgical planning when compared to the conventional bone-driven approach.
Leveraging Pre-Trained 3D Object Detection Models For Fast Ground Truth Generation
Jul 16, 2018
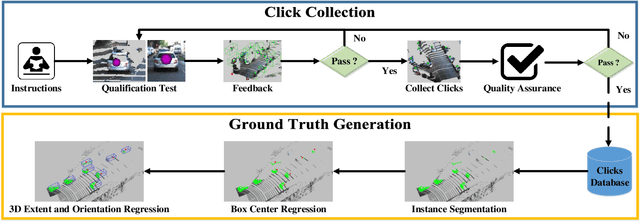
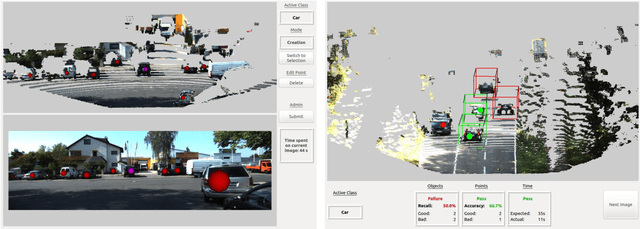
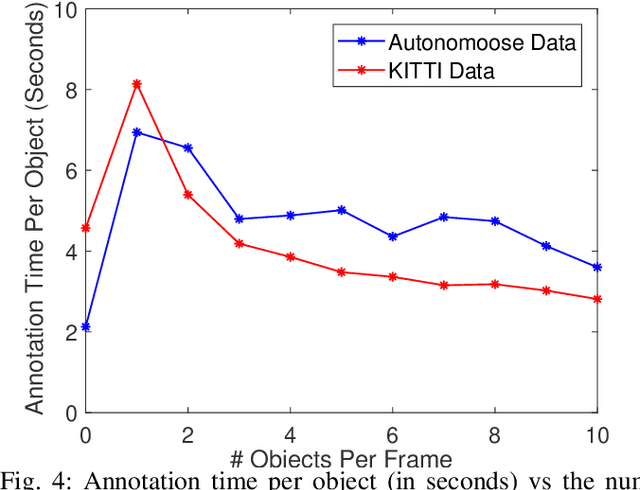
Training 3D object detectors for autonomous driving has been limited to small datasets due to the effort required to generate annotations. Reducing both task complexity and the amount of task switching done by annotators is key to reducing the effort and time required to generate 3D bounding box annotations. This paper introduces a novel ground truth generation method that combines human supervision with pretrained neural networks to generate per-instance 3D point cloud segmentation, 3D bounding boxes, and class annotations. The annotators provide object anchor clicks which behave as a seed to generate instance segmentation results in 3D. The points belonging to each instance are then used to regress object centroids, bounding box dimensions, and object orientation. Our proposed annotation scheme requires 30x lower human annotation time. We use the KITTI 3D object detection dataset to evaluate the efficiency and the quality of our annotation scheme. We also test the the proposed scheme on previously unseen data from the Autonomoose self-driving vehicle to demonstrate generalization capabilities of the network.
Joint 3D Proposal Generation and Object Detection from View Aggregation
Jul 12, 2018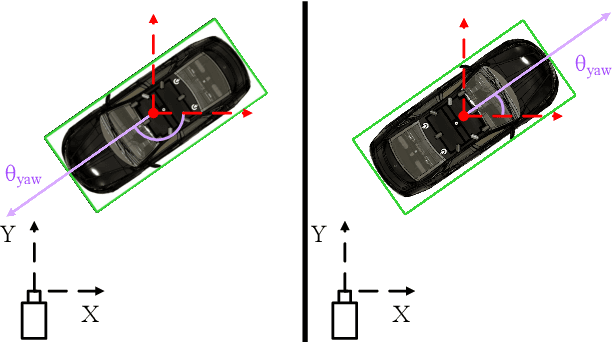
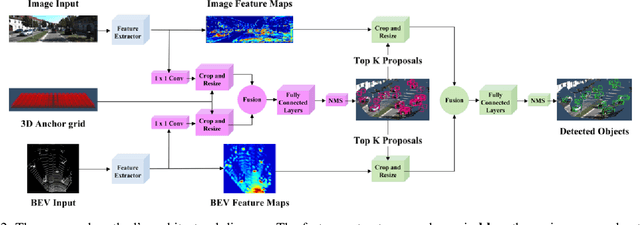
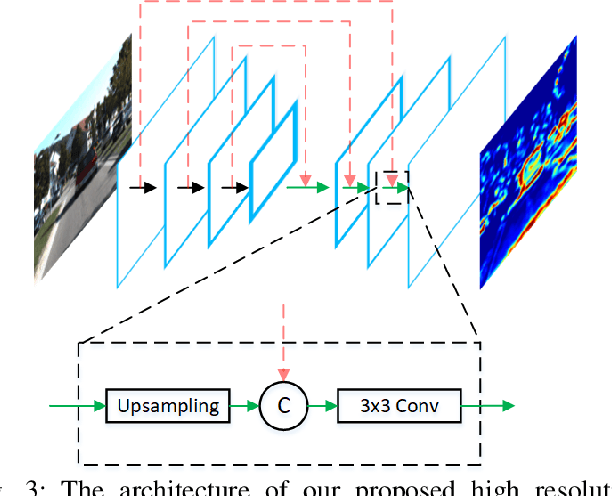
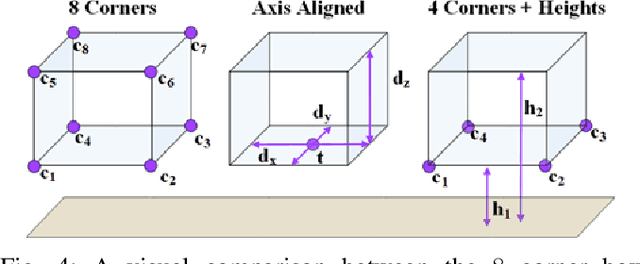
We present AVOD, an Aggregate View Object Detection network for autonomous driving scenarios. The proposed neural network architecture uses LIDAR point clouds and RGB images to generate features that are shared by two subnetworks: a region proposal network (RPN) and a second stage detector network. The proposed RPN uses a novel architecture capable of performing multimodal feature fusion on high resolution feature maps to generate reliable 3D object proposals for multiple object classes in road scenes. Using these proposals, the second stage detection network performs accurate oriented 3D bounding box regression and category classification to predict the extents, orientation, and classification of objects in 3D space. Our proposed architecture is shown to produce state of the art results on the KITTI 3D object detection benchmark while running in real time with a low memory footprint, making it a suitable candidate for deployment on autonomous vehicles. Code is at: https://github.com/kujason/avod