 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Reinforcement Learning Objectives for Sequential Recommender Systems
May 30, 2023Attention-based sequential recommendation methods have demonstrated promising results by accurately capturing users' dynamic interests from historical interactions. In addition to generating superior user representations, recent studies have begun integrating reinforcement learning (RL) into these models. Framing sequential recommendation as an RL problem with reward signals, unlocks developing recommender systems (RS) that consider a vital aspect-incorporating direct user feedback in the form of rewards to deliver a more personalized experience. Nonetheless, employing RL algorithms presents challenges, including off-policy training, expansive combinatorial action spaces, and the scarcity of datasets with sufficient reward signals. Contemporary approaches have attempted to combine RL and sequential modeling, incorporating contrastive-based objectives and negative sampling strategies for training the RL component. In this study, we further emphasize the efficacy of contrastive-based objectives paired with augmentation to address datasets with extended horizons. Additionally, we recognize the potential instability issues that may arise during the application of negative sampling. These challenges primarily stem from the data imbalance prevalent in real-world datasets, which is a common issue in offline RL contexts. While our established baselines attempt to mitigate this through various techniques, instability remains an issue. Therefore, we introduce an enhanced methodology aimed at providing a more effective solution to these challenges.
Perspectives on Sim2Real Transfer for Robotics: A Summary of the R:SS 2020 Workshop
Dec 07, 2020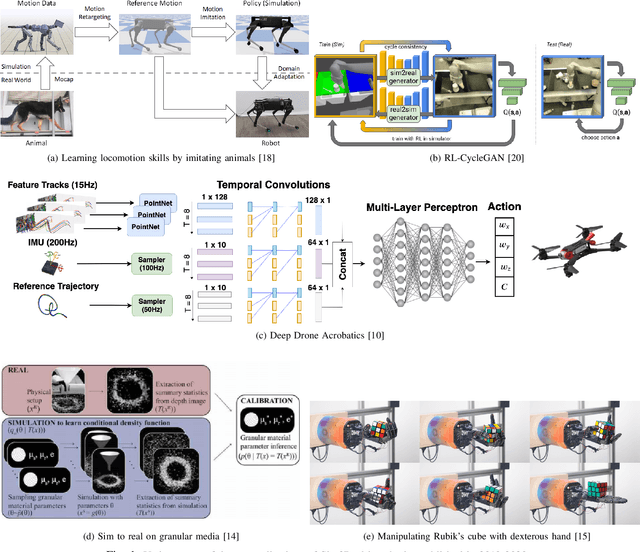
This report presents the debates, posters, and discussions of the Sim2Real workshop held in conjunction with the 2020 edition of the "Robotics: Science and System" conference. Twelve leaders of the field took competing debate positions on the definition, viability, and importance of transferring skills from simulation to the real world in the context of robotics problems. The debaters also joined a large panel discussion, answering audience questions and outlining the future of Sim2Real in robotics. Furthermore, we invited extended abstracts to this workshop which are summarized in this report. Based on the workshop, this report concludes with directions for practitioners exploiting this technology and for researchers further exploring open problems in this area.
Intervention Design for Effective Sim2Real Transfer
Dec 03, 2020
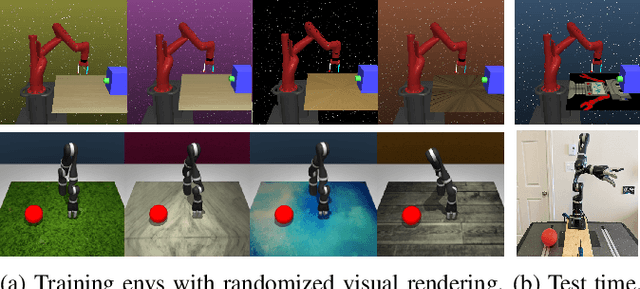
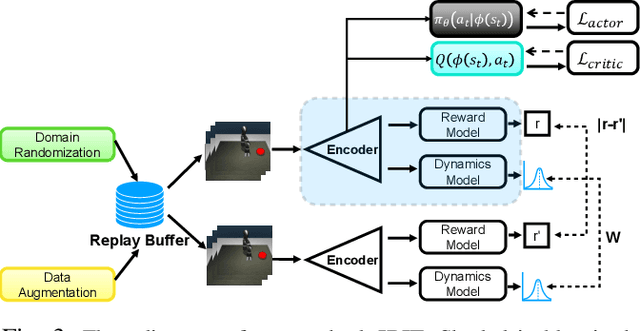
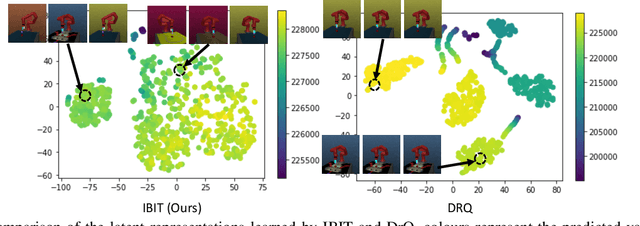
The goal of this work is to address the recent success of domain randomization and data augmentation for the sim2real setting. We explain this success through the lens of causal inference, positioning domain randomization and data augmentation as interventions on the environment which encourage invariance to irrelevant features. Such interventions include visual perturbations that have no effect on reward and dynamics. This encourages the learning algorithm to be robust to these types of variations and learn to attend to the true causal mechanisms for solving the task. This connection leads to two key findings: (1) perturbations to the environment do not have to be realistic, but merely show variation along dimensions that also vary in the real world, and (2) use of an explicit invariance-inducing objective improves generalization in sim2sim and sim2real transfer settings over just data augmentation or domain randomization alone. We demonstrate the capability of our method by performing zero-shot transfer of a robot arm reach task on a 7DoF Jaco arm learning from pixel observations.
Shaping Rewards for Reinforcement Learning with Imperfect Demonstrations using Generative Models
Nov 02, 2020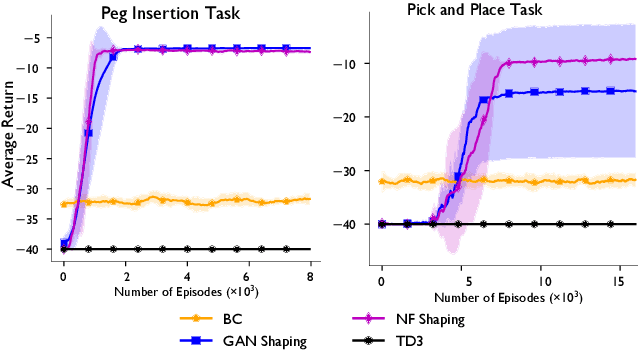
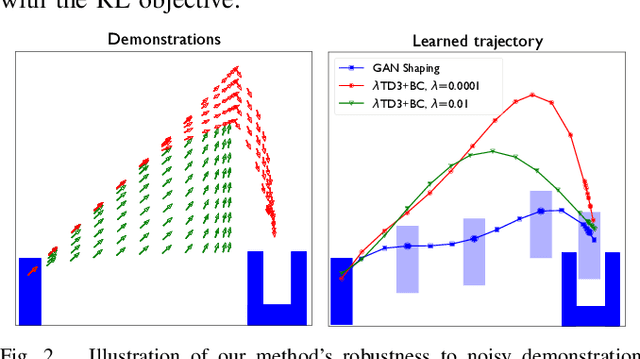
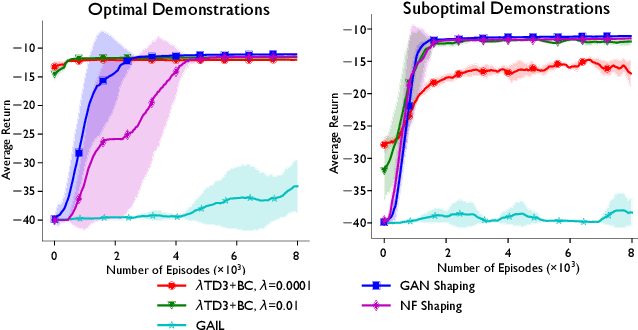
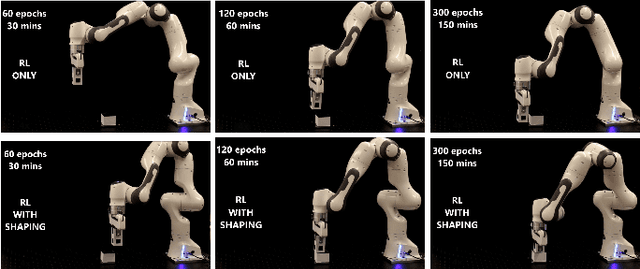
The potential benefits of model-free reinforcement learning to real robotics systems are limited by its uninformed exploration that leads to slow convergence, lack of data-efficiency, and unnecessary interactions with the environment. To address these drawbacks we propose a method that combines reinforcement and imitation learning by shaping the reward function with a state-and-action-dependent potential that is trained from demonstration data, using a generative model. We show that this accelerates policy learning by specifying high-value areas of the state and action space that are worth exploring first. Unlike the majority of existing methods that assume optimal demonstrations and incorporate the demonstration data as hard constraints on policy optimization, we instead incorporate demonstration data as advice in the form of a reward shaping potential trained as a generative model of states and actions. In particular, we examine both normalizing flows and Generative Adversarial Networks to represent these potentials. We show that, unlike many existing approaches that incorporate demonstrations as hard constraints, our approach is unbiased even in the case of suboptimal and noisy demonstrations. We present an extensive range of simulations, as well as experiments on the Franka Emika 7DOF arm, to demonstrate the practicality of our method.
Learning Domain Randomization Distributions for Transfer of Locomotion Policies
Jun 02, 2019


Domain randomization (DR) is a successful technique for learning robust policies for robot systems, when the dynamics of the target robot system are unknown. The success of policies trained with domain randomization however, is highly dependent on the correct selection of the randomization distribution. The majority of success stories typically use real world data in order to carefully select the DR distribution, or incorporate real world trajectories to better estimate appropriate randomization distributions. In this paper, we consider the problem of finding good domain randomization parameters for simulation, without prior access to data from the target system. We explore the use of gradient-based search methods to learn a domain randomization with the following properties: 1) The trained policy should be successful in environments sampled from the domain randomization distribution 2) The domain randomization distribution should be wide enough so that the experience similar to the target robot system is observed during training, while addressing the practicality of training finite capacity models. These two properties aim to ensure the trajectories encountered in the target system are close to those observed during training, as existing methods in machine learning are better suited for interpolation than extrapolation. We show how adapting the domain randomization distribution while training context-conditioned policies results in improvements on jump-start and asymptotic performance when transferring a learned policy to the target environment.
Joint 3D Proposal Generation and Object Detection from View Aggregation
Jul 12, 2018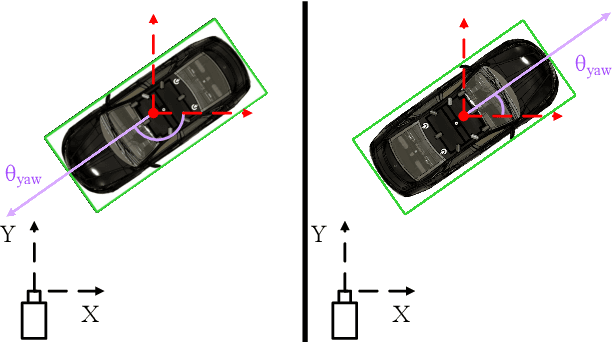
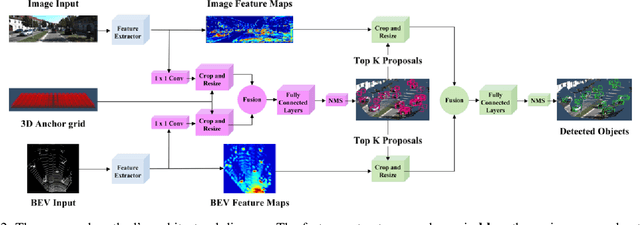
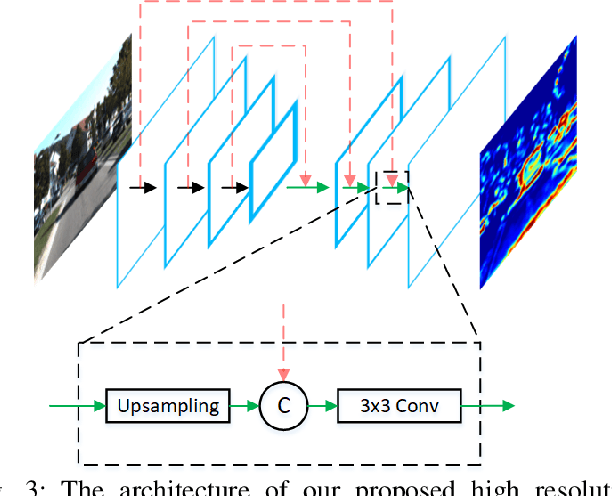
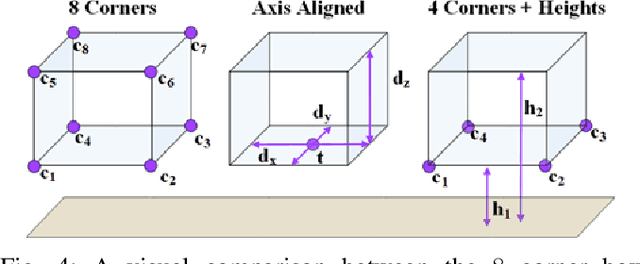
We present AVOD, an Aggregate View Object Detection network for autonomous driving scenarios. The proposed neural network architecture uses LIDAR point clouds and RGB images to generate features that are shared by two subnetworks: a region proposal network (RPN) and a second stage detector network. The proposed RPN uses a novel architecture capable of performing multimodal feature fusion on high resolution feature maps to generate reliable 3D object proposals for multiple object classes in road scenes. Using these proposals, the second stage detection network performs accurate oriented 3D bounding box regression and category classification to predict the extents, orientation, and classification of objects in 3D space. Our proposed architecture is shown to produce state of the art results on the KITTI 3D object detection benchmark while running in real time with a low memory footprint, making it a suitable candidate for deployment on autonomous vehicles. Code is at: https://github.com/kujason/avod