 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeeing the Unseen: How EMoE Unveils Bias in Text-to-Image Diffusion Models
May 19, 2025



Estimating uncertainty in text-to-image diffusion models is challenging because of their large parameter counts (often exceeding 100 million) and operation in complex, high-dimensional spaces with virtually infinite input possibilities. In this paper, we propose Epistemic Mixture of Experts (EMoE), a novel framework for efficiently estimating epistemic uncertainty in diffusion models. EMoE leverages pre-trained networks without requiring additional training, enabling direct uncertainty estimation from a prompt. We leverage a latent space within the diffusion process that captures epistemic uncertainty better than existing methods. Experimental results on the COCO dataset demonstrate EMoE's effectiveness, showing a strong correlation between uncertainty and image quality. Additionally, EMoE identifies under-sampled languages and regions with higher uncertainty, revealing hidden biases in the training set. This capability demonstrates the relevance of EMoE as a tool for addressing fairness and accountability in AI-generated content.
IL-flOw: Imitation Learning from Observation using Normalizing Flows
May 19, 2022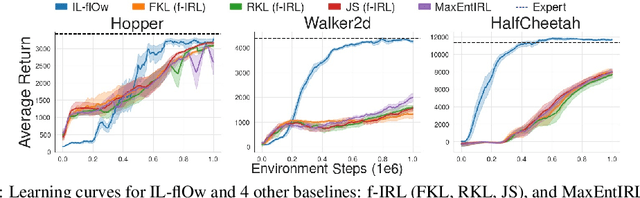
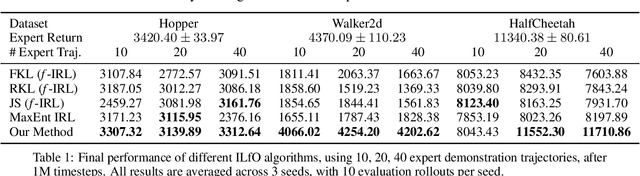
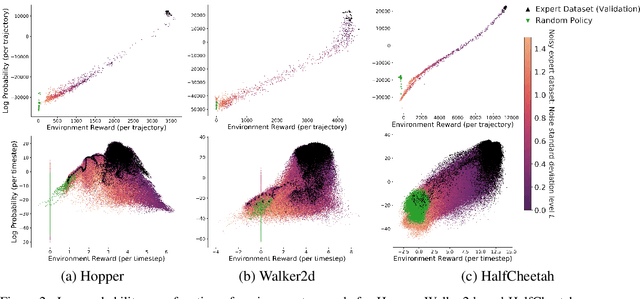
We present an algorithm for Inverse Reinforcement Learning (IRL) from expert state observations only. Our approach decouples reward modelling from policy learning, unlike state-of-the-art adversarial methods which require updating the reward model during policy search and are known to be unstable and difficult to optimize. Our method, IL-flOw, recovers the expert policy by modelling state-state transitions, by generating rewards using deep density estimators trained on the demonstration trajectories, avoiding the instability issues of adversarial methods. We demonstrate that using the state transition log-probability density as a reward signal for forward reinforcement learning translates to matching the trajectory distribution of the expert demonstrations, and experimentally show good recovery of the true reward signal as well as state of the art results for imitation from observation on locomotion and robotic continuous control tasks.
Vision-Based Goal-Conditioned Policies for Underwater Navigation in the Presence of Obstacles
Jun 29, 2020
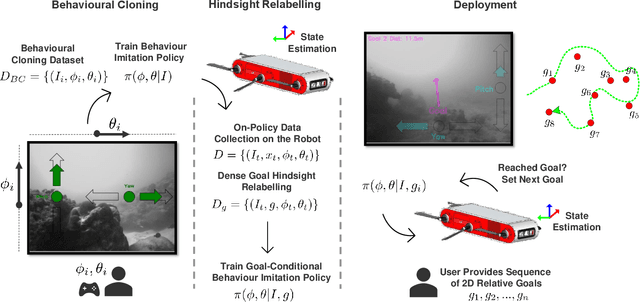
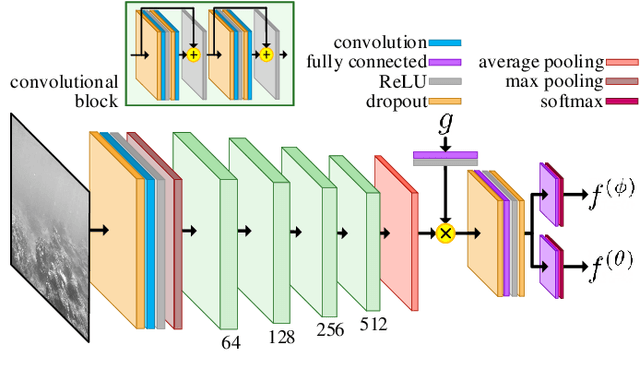
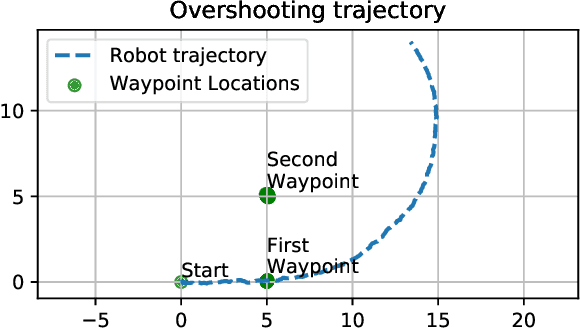
We present Nav2Goal, a data-efficient and end-to-end learning method for goal-conditioned visual navigation. Our technique is used to train a navigation policy that enables a robot to navigate close to sparse geographic waypoints provided by a user without any prior map, all while avoiding obstacles and choosing paths that cover user-informed regions of interest. Our approach is based on recent advances in conditional imitation learning. General-purpose, safe and informative actions are demonstrated by a human expert. The learned policy is subsequently extended to be goal-conditioned by training with hindsight relabelling, guided by the robot's relative localization system, which requires no additional manual annotation. We deployed our method on an underwater vehicle in the open ocean to collect scientifically relevant data of coral reefs, which allowed our robot to operate safely and autonomously, even at very close proximity to the coral. Our field deployments have demonstrated over a kilometer of autonomous visual navigation, where the robot reaches on the order of 40 waypoints, while collecting scientifically relevant data. This is done while travelling within 0.5 m altitude from sensitive corals and exhibiting significant learned agility to overcome turbulent ocean conditions and to actively avoid collisions.
One-Shot Informed Robotic Visual Search in the Wild
Mar 22, 2020
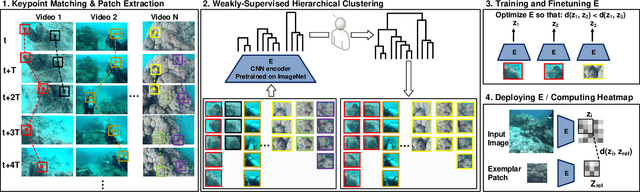


We consider the task of underwater robot navigation for the purpose of collecting scientifically-relevant video data for environmental monitoring. The majority of field robots that currently perform monitoring tasks in unstructured natural environments navigate via path-tracking a pre-specified sequence of waypoints. Although this navigation method is often necessary, it is limiting because the robot does not have a model of what the scientist deems to be relevant visual observations. Thus, the robot can neither visually search for particular types of objects, nor focus its attention on parts of the scene that might be more relevant than the pre-specified waypoints and viewpoints. In this paper we propose a method that enables informed visual navigation via a learned visual similarity operator that guides the robot's visual search towards parts of the scene that look like an exemplar image, which is given by the user as a high-level specification for data collection. We propose and evaluate a weakly-supervised video representation learning method that outperforms ImageNet embeddings for similarity tasks in the underwater domain. We also demonstrate the deployment of this similarity operator during informed visual navigation in collaborative environmental monitoring scenarios, in large-scale field trials, where the robot and a human scientist jointly search for relevant visual content.
Optimizing Through Learned Errors for Accurate Sports Field Registration
Sep 17, 2019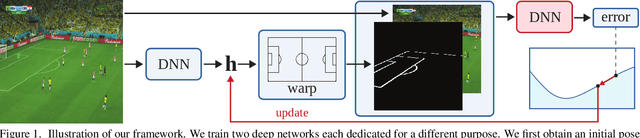
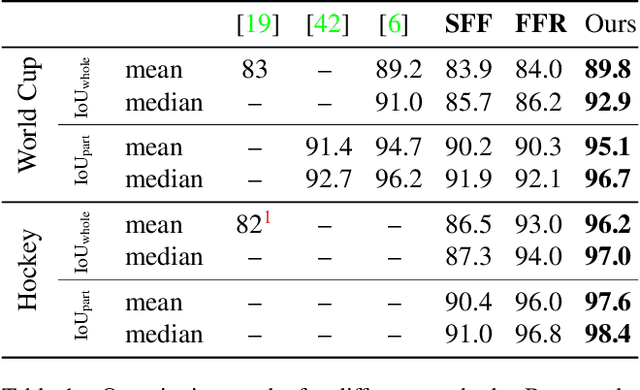
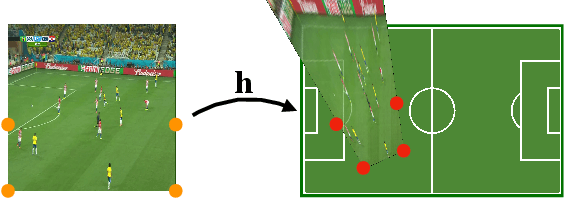
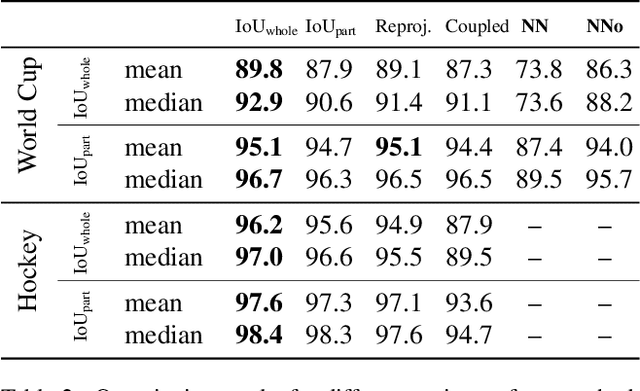
We propose an optimization-based framework to register sports field templates onto broadcast videos. For accurate registration we go beyond the prevalent feed-forward paradigm. Instead, we propose to train a deep network that regresses the registration error, and then register images by finding the registration parameters that minimize the regressed error. We demonstrate the effectiveness of our method by applying it to real-world sports broadcast videos, outperforming the state of the art. We further apply our method on a synthetic toy example and demonstrate that our method brings significant gains even when the problem is simplified and unlimited training data is available.
Learning Domain Randomization Distributions for Transfer of Locomotion Policies
Jun 02, 2019


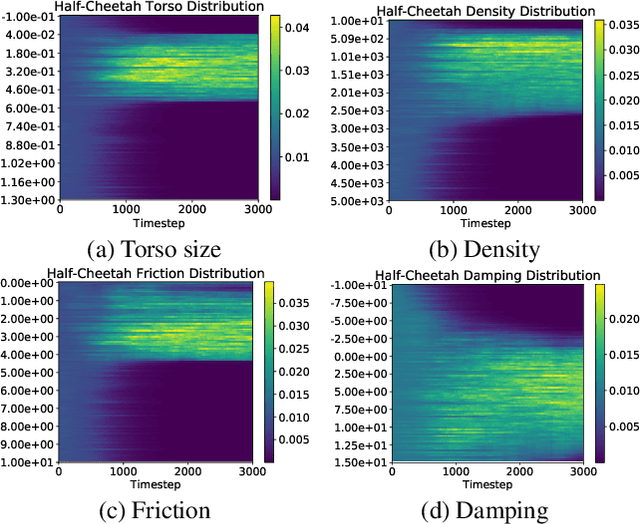
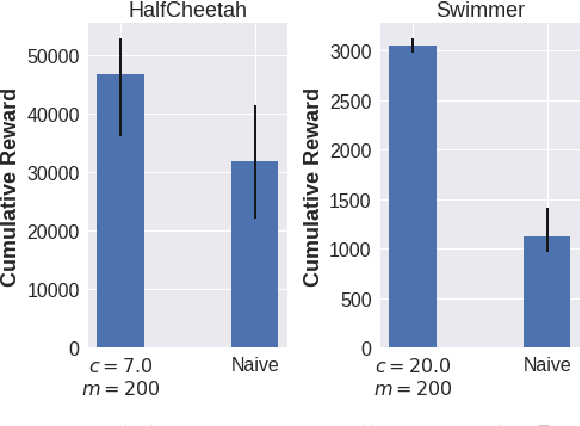
Domain randomization (DR) is a successful technique for learning robust policies for robot systems, when the dynamics of the target robot system are unknown. The success of policies trained with domain randomization however, is highly dependent on the correct selection of the randomization distribution. The majority of success stories typically use real world data in order to carefully select the DR distribution, or incorporate real world trajectories to better estimate appropriate randomization distributions. In this paper, we consider the problem of finding good domain randomization parameters for simulation, without prior access to data from the target system. We explore the use of gradient-based search methods to learn a domain randomization with the following properties: 1) The trained policy should be successful in environments sampled from the domain randomization distribution 2) The domain randomization distribution should be wide enough so that the experience similar to the target robot system is observed during training, while addressing the practicality of training finite capacity models. These two properties aim to ensure the trajectories encountered in the target system are close to those observed during training, as existing methods in machine learning are better suited for interpolation than extrapolation. We show how adapting the domain randomization distribution while training context-conditioned policies results in improvements on jump-start and asymptotic performance when transferring a learned policy to the target environment.
Uncertainty Aware Learning from Demonstrations in Multiple Contexts using Bayesian Neural Networks
Mar 13, 2019
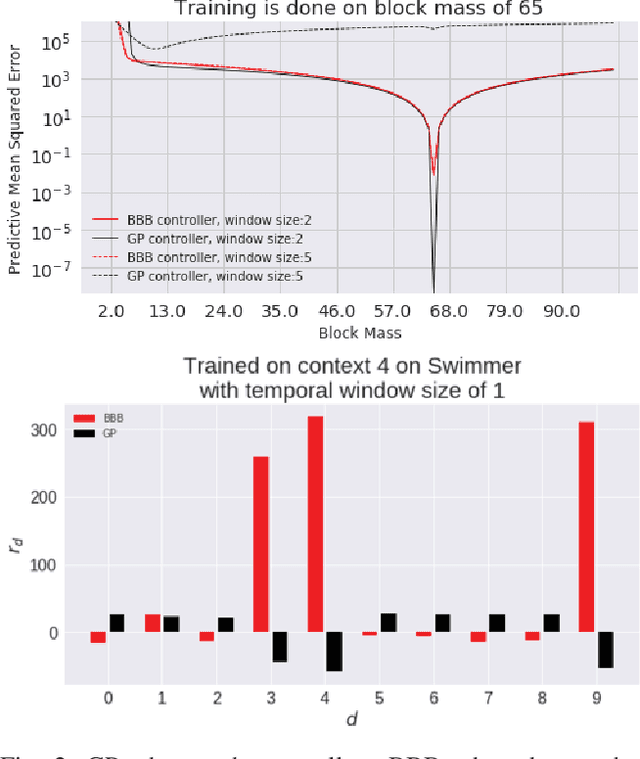
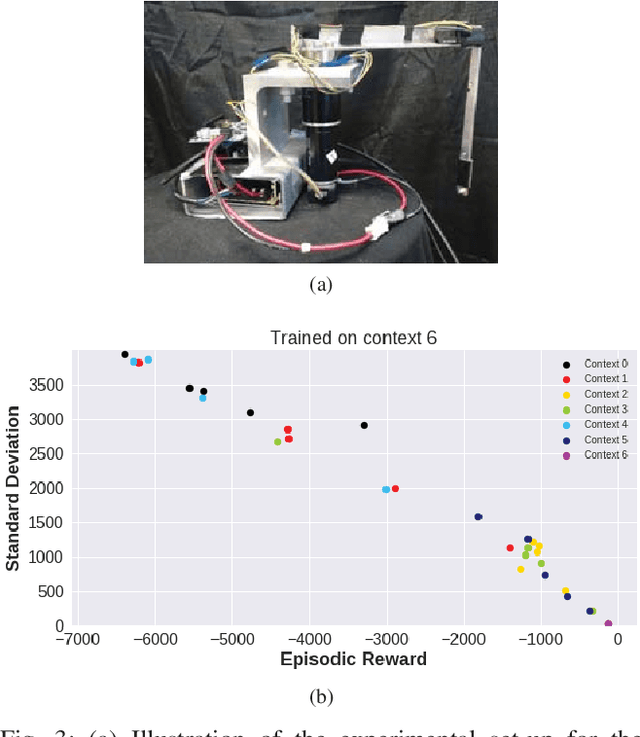
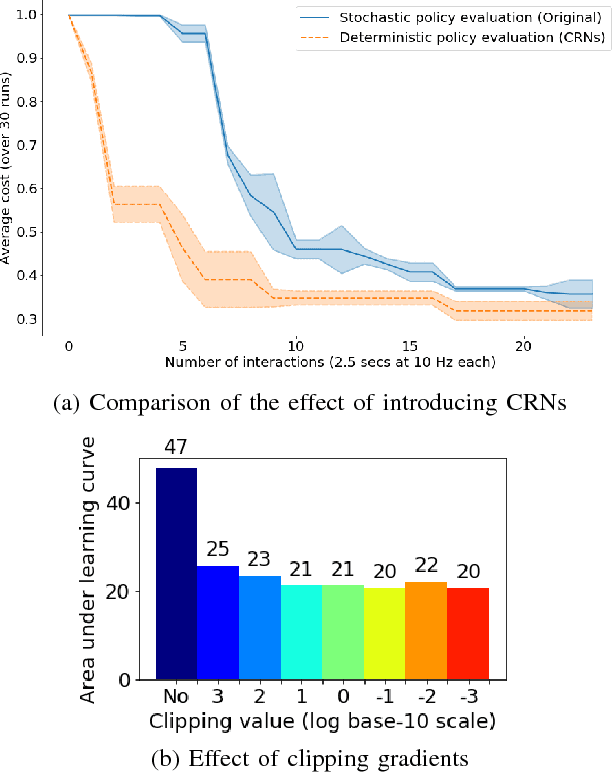
Diversity of environments is a key challenge that causes learned robotic controllers to fail due to the discrepancies between the training and evaluation conditions. Training from demonstrations in various conditions can mitigate---but not completely prevent---such failures. Learned controllers such as neural networks typically do not have a notion of uncertainty that allows to diagnose an offset between training and testing conditions, and potentially intervene. In this work, we propose to use Bayesian Neural Networks, which have such a notion of uncertainty. We show that uncertainty can be leveraged to consistently detect situations in high-dimensional simulated and real robotic domains in which the performance of the learned controller would be sub-par. Also, we show that such an uncertainty based solution allows making an informed decision about when to invoke a fallback strategy. One fallback strategy is to request more data. We empirically show that providing data only when requested results in increased data-efficiency.
Synthesizing Neural Network Controllers with Probabilistic Model based Reinforcement Learning
Aug 01, 2018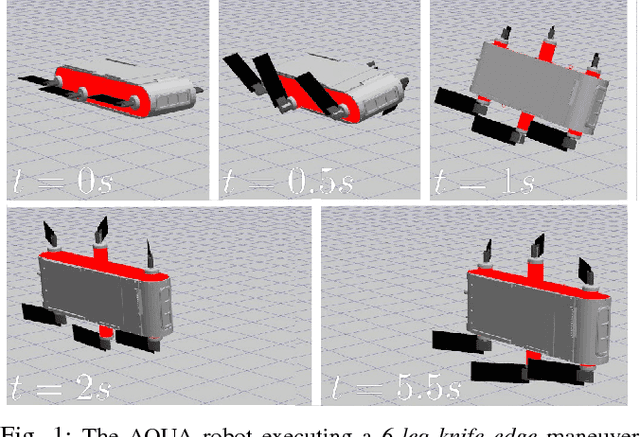
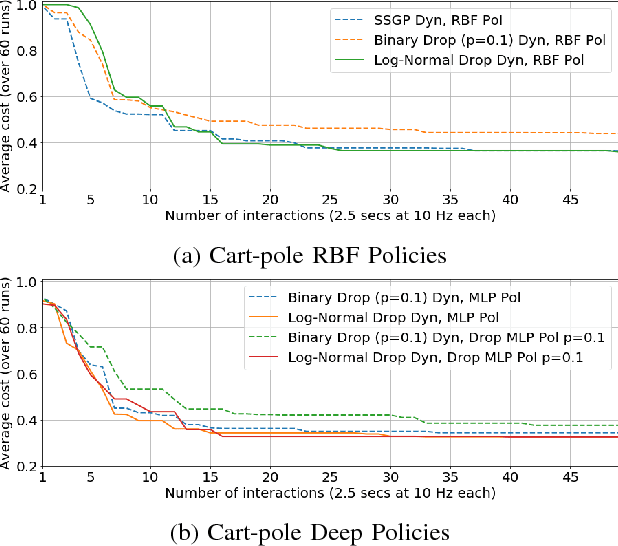
We present an algorithm for rapidly learning controllers for robotics systems. The algorithm follows the model-based reinforcement learning paradigm, and improves upon existing algorithms; namely Probabilistic learning in Control (PILCO) and a sample-based version of PILCO with neural network dynamics (Deep-PILCO). We propose training a neural network dynamics model using variational dropout with truncated Log-Normal noise. This allows us to obtain a dynamics model with calibrated uncertainty, which can be used to simulate controller executions via rollouts. We also describe set of techniques, inspired by viewing PILCO as a recurrent neural network model, that are crucial to improve the convergence of the method. We test our method on a variety of benchmark tasks, demonstrating data-efficiency that is competitive with PILCO, while being able to optimize complex neural network controllers. Finally, we assess the performance of the algorithm for learning motor controllers for a six legged autonomous underwater vehicle. This demonstrates the potential of the algorithm for scaling up the dimensionality and dataset sizes, in more complex control tasks.
Underwater Multi-Robot Convoying using Visual Tracking by Detection
Sep 25, 2017
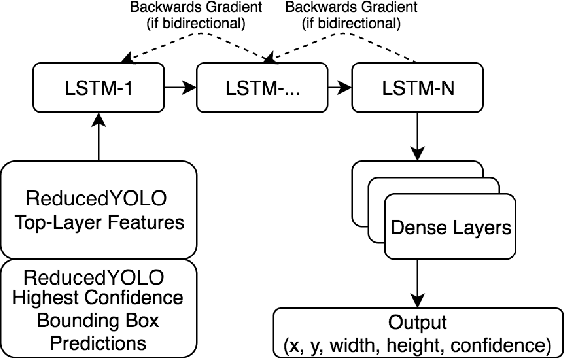
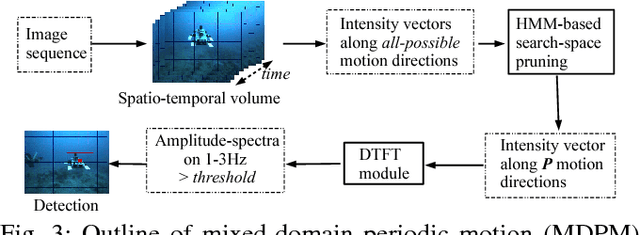
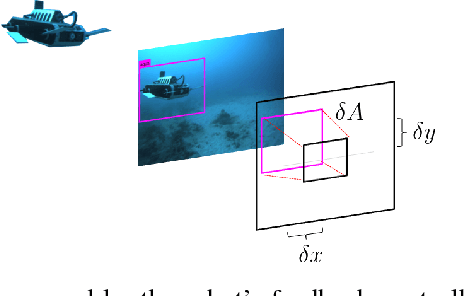
We present a robust multi-robot convoying approach that relies on visual detection of the leading agent, thus enabling target following in unstructured 3-D environments. Our method is based on the idea of tracking-by-detection, which interleaves efficient model-based object detection with temporal filtering of image-based bounding box estimation. This approach has the important advantage of mitigating tracking drift (i.e. drifting away from the target object), which is a common symptom of model-free trackers and is detrimental to sustained convoying in practice. To illustrate our solution, we collected extensive footage of an underwater robot in ocean settings, and hand-annotated its location in each frame. Based on this dataset, we present an empirical comparison of multiple tracker variants, including the use of several convolutional neural networks, both with and without recurrent connections, as well as frequency-based model-free trackers. We also demonstrate the practicality of this tracking-by-detection strategy in real-world scenarios by successfully controlling a legged underwater robot in five degrees of freedom to follow another robot's independent motion.