 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrajectory-Constrained Deep Latent Visual Attention for Improved Local Planning in Presence of Heterogeneous Terrain
Dec 09, 2021

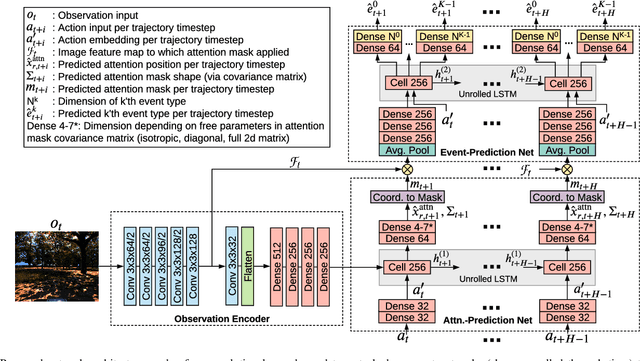

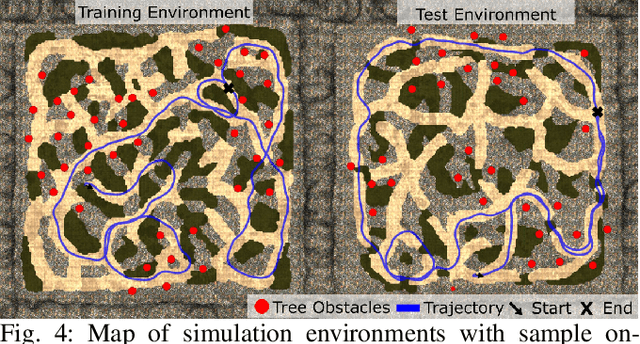
We present a reward-predictive, model-based deep learning method featuring trajectory-constrained visual attention for use in mapless, local visual navigation tasks. Our method learns to place visual attention at locations in latent image space which follow trajectories caused by vehicle control actions to enhance predictive accuracy during planning. The attention model is jointly optimized by the task-specific loss and an additional trajectory-constraint loss, allowing adaptability yet encouraging a regularized structure for improved generalization and reliability. Importantly, visual attention is applied in latent feature map space instead of raw image space to promote efficient planning. We validated our model in visual navigation tasks of planning low turbulence, collision-free trajectories in off-road settings and hill climbing with locking differentials in the presence of slippery terrain. Experiments involved randomized procedural generated simulation and real-world environments. We found our method improved generalization and learning efficiency when compared to no-attention and self-attention alternatives.
Vision-Based Goal-Conditioned Policies for Underwater Navigation in the Presence of Obstacles
Jun 29, 2020
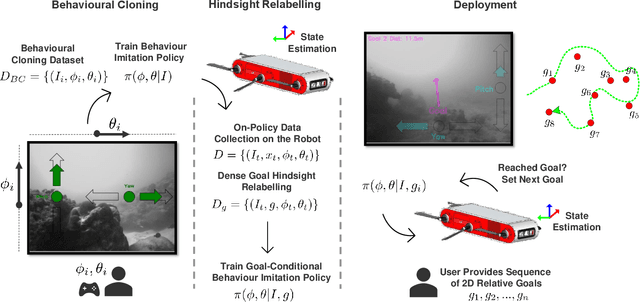
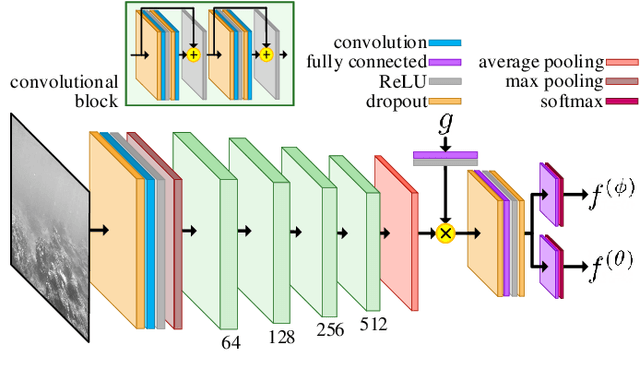
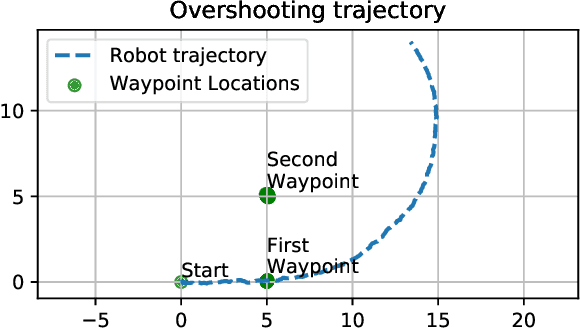
We present Nav2Goal, a data-efficient and end-to-end learning method for goal-conditioned visual navigation. Our technique is used to train a navigation policy that enables a robot to navigate close to sparse geographic waypoints provided by a user without any prior map, all while avoiding obstacles and choosing paths that cover user-informed regions of interest. Our approach is based on recent advances in conditional imitation learning. General-purpose, safe and informative actions are demonstrated by a human expert. The learned policy is subsequently extended to be goal-conditioned by training with hindsight relabelling, guided by the robot's relative localization system, which requires no additional manual annotation. We deployed our method on an underwater vehicle in the open ocean to collect scientifically relevant data of coral reefs, which allowed our robot to operate safely and autonomously, even at very close proximity to the coral. Our field deployments have demonstrated over a kilometer of autonomous visual navigation, where the robot reaches on the order of 40 waypoints, while collecting scientifically relevant data. This is done while travelling within 0.5 m altitude from sensitive corals and exhibiting significant learned agility to overcome turbulent ocean conditions and to actively avoid collisions.
Learning to Drive Off Road on Smooth Terrain in Unstructured Environments Using an On-Board Camera and Sparse Aerial Images
Apr 09, 2020


We present a method for learning to drive on smooth terrain while simultaneously avoiding collisions in challenging off-road and unstructured outdoor environments using only visual inputs. Our approach applies a hybrid model-based and model-free reinforcement learning method that is entirely self-supervised in labeling terrain roughness and collisions using on-board sensors. Notably, we provide both first-person and overhead aerial image inputs to our model. We find that the fusion of these complementary inputs improves planning foresight and makes the model robust to visual obstructions. Our results show the ability to generalize to environments with plentiful vegetation, various types of rock, and sandy trails. During evaluation, our policy attained 90% smooth terrain traversal and reduced the proportion of rough terrain driven over by 6.1 times compared to a model using only first-person imagery.