 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContractive Diffusion Policies: Robust Action Diffusion via Contractive Score-Based Sampling with Differential Equations
Jan 02, 2026Diffusion policies have emerged as powerful generative models for offline policy learning, whose sampling process can be rigorously characterized by a score function guiding a Stochastic Differential Equation (SDE). However, the same score-based SDE modeling that grants diffusion policies the flexibility to learn diverse behavior also incurs solver and score-matching errors, large data requirements, and inconsistencies in action generation. While less critical in image generation, these inaccuracies compound and lead to failure in continuous control settings. We introduce Contractive Diffusion Policies (CDPs) to induce contractive behavior in the diffusion sampling dynamics. Contraction pulls nearby flows closer to enhance robustness against solver and score-matching errors while reducing unwanted action variance. We develop an in-depth theoretical analysis along with a practical implementation recipe to incorporate CDPs into existing diffusion policy architectures with minimal modification and computational cost. We evaluate CDPs for offline learning by conducting extensive experiments in simulation and real-world settings. Across benchmarks, CDPs often outperform baseline policies, with pronounced benefits under data scarcity.
Seeing the Unseen: How EMoE Unveils Bias in Text-to-Image Diffusion Models
May 19, 2025Estimating uncertainty in text-to-image diffusion models is challenging because of their large parameter counts (often exceeding 100 million) and operation in complex, high-dimensional spaces with virtually infinite input possibilities. In this paper, we propose Epistemic Mixture of Experts (EMoE), a novel framework for efficiently estimating epistemic uncertainty in diffusion models. EMoE leverages pre-trained networks without requiring additional training, enabling direct uncertainty estimation from a prompt. We leverage a latent space within the diffusion process that captures epistemic uncertainty better than existing methods. Experimental results on the COCO dataset demonstrate EMoE's effectiveness, showing a strong correlation between uncertainty and image quality. Additionally, EMoE identifies under-sampled languages and regions with higher uncertainty, revealing hidden biases in the training set. This capability demonstrates the relevance of EMoE as a tool for addressing fairness and accountability in AI-generated content.
Tractable Representations for Convergent Approximation of Distributional HJB Equations
Mar 07, 2025In reinforcement learning (RL), the long-term behavior of decision-making policies is evaluated based on their average returns. Distributional RL has emerged, presenting techniques for learning return distributions, which provide additional statistics for evaluating policies, incorporating risk-sensitive considerations. When the passage of time cannot naturally be divided into discrete time increments, researchers have studied the continuous-time RL (CTRL) problem, where agent states and decisions evolve continuously. In this setting, the Hamilton-Jacobi-Bellman (HJB) equation is well established as the characterization of the expected return, and many solution methods exist. However, the study of distributional RL in the continuous-time setting is in its infancy. Recent work has established a distributional HJB (DHJB) equation, providing the first characterization of return distributions in CTRL. These equations and their solutions are intractable to solve and represent exactly, requiring novel approximation techniques. This work takes strides towards this end, establishing conditions on the method of parameterizing return distributions under which the DHJB equation can be approximately solved. Particularly, we show that under a certain topological property of the mapping between statistics learned by a distributional RL algorithm and corresponding distributions, approximation of these statistics leads to close approximations of the solution of the DHJB equation. Concretely, we demonstrate that the quantile representation common in distributional RL satisfies this topological property, certifying an efficient approximation algorithm for continuous-time distributional RL.
Fairness in Reinforcement Learning with Bisimulation Metrics
Dec 22, 2024



Ensuring long-term fairness is crucial when developing automated decision making systems, specifically in dynamic and sequential environments. By maximizing their reward without consideration of fairness, AI agents can introduce disparities in their treatment of groups or individuals. In this paper, we establish the connection between bisimulation metrics and group fairness in reinforcement learning. We propose a novel approach that leverages bisimulation metrics to learn reward functions and observation dynamics, ensuring that learners treat groups fairly while reflecting the original problem. We demonstrate the effectiveness of our method in addressing disparities in sequential decision making problems through empirical evaluation on a standard fairness benchmark consisting of lending and college admission scenarios.
Parseval Regularization for Continual Reinforcement Learning
Dec 10, 2024



Loss of plasticity, trainability loss, and primacy bias have been identified as issues arising when training deep neural networks on sequences of tasks -- all referring to the increased difficulty in training on new tasks. We propose to use Parseval regularization, which maintains orthogonality of weight matrices, to preserve useful optimization properties and improve training in a continual reinforcement learning setting. We show that it provides significant benefits to RL agents on a suite of gridworld, CARL and MetaWorld tasks. We conduct comprehensive ablations to identify the source of its benefits and investigate the effect of certain metrics associated to network trainability including weight matrix rank, weight norms and policy entropy.
Action Gaps and Advantages in Continuous-Time Distributional Reinforcement Learning
Oct 14, 2024When decisions are made at high frequency, traditional reinforcement learning (RL) methods struggle to accurately estimate action values. In turn, their performance is inconsistent and often poor. Whether the performance of distributional RL (DRL) agents suffers similarly, however, is unknown. In this work, we establish that DRL agents are sensitive to the decision frequency. We prove that action-conditioned return distributions collapse to their underlying policy's return distribution as the decision frequency increases. We quantify the rate of collapse of these return distributions and exhibit that their statistics collapse at different rates. Moreover, we define distributional perspectives on action gaps and advantages. In particular, we introduce the superiority as a probabilistic generalization of the advantage -- the core object of approaches to mitigating performance issues in high-frequency value-based RL. In addition, we build a superiority-based DRL algorithm. Through simulations in an option-trading domain, we validate that proper modeling of the superiority distribution produces improved controllers at high decision frequencies.
Topological mapping for traversability-aware long-range navigation in off-road terrain
Oct 02, 2024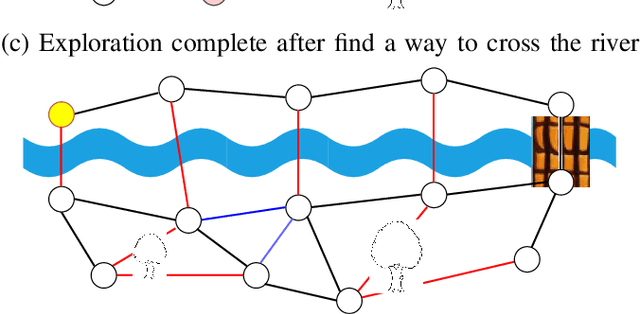

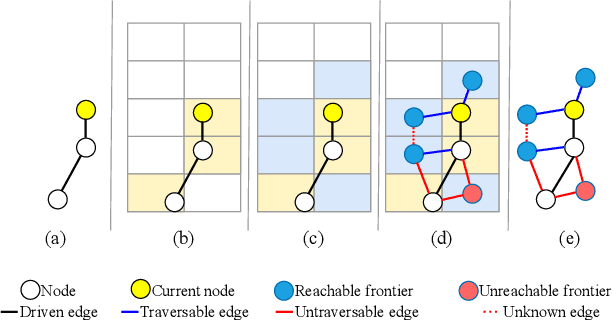
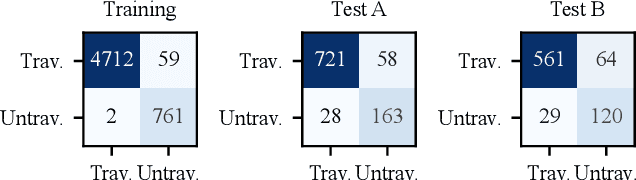
Autonomous robots navigating in off-road terrain like forests open new opportunities for automation. While off-road navigation has been studied, existing work often relies on clearly delineated pathways. We present a method allowing for long-range planning, exploration and low-level control in unknown off-trail forest terrain, using vision and GPS only. We represent outdoor terrain with a topological map, which is a set of panoramic snapshots connected with edges containing traversability information. A novel traversability analysis method is demonstrated, predicting the existence of a safe path towards a target in an image. Navigating between nodes is done using goal-conditioned behavior cloning, leveraging the power of a pretrained vision transformer. An exploration planner is presented, efficiently covering an unknown off-road area with unknown traversability using a frontiers-based approach. The approach is successfully deployed to autonomously explore two 400 meters squared forest sites unseen during training, in difficult conditions for navigation.
Constrained Robotic Navigation on Preferred Terrains Using LLMs and Speech Instruction: Exploiting the Power of Adverbs
Apr 02, 2024This paper explores leveraging large language models for map-free off-road navigation using generative AI, reducing the need for traditional data collection and annotation. We propose a method where a robot receives verbal instructions, converted to text through Whisper, and a large language model (LLM) model extracts landmarks, preferred terrains, and crucial adverbs translated into speed settings for constrained navigation. A language-driven semantic segmentation model generates text-based masks for identifying landmarks and terrain types in images. By translating 2D image points to the vehicle's motion plane using camera parameters, an MPC controller can guides the vehicle towards the desired terrain. This approach enhances adaptation to diverse environments and facilitates the use of high-level instructions for navigating complex and challenging terrains.
Learning active tactile perception through belief-space control
Nov 30, 2023Robots operating in an open world will encounter novel objects with unknown physical properties, such as mass, friction, or size. These robots will need to sense these properties through interaction prior to performing downstream tasks with the objects. We propose a method that autonomously learns tactile exploration policies by developing a generative world model that is leveraged to 1) estimate the object's physical parameters using a differentiable Bayesian filtering algorithm and 2) develop an exploration policy using an information-gathering model predictive controller. We evaluate our method on three simulated tasks where the goal is to estimate a desired object property (mass, height or toppling height) through physical interaction. We find that our method is able to discover policies that efficiently gather information about the desired property in an intuitive manner. Finally, we validate our method on a real robot system for the height estimation task, where our method is able to successfully learn and execute an information-gathering policy from scratch.
Generalizable Imitation Learning Through Pre-Trained Representations
Nov 15, 2023



In this paper we leverage self-supervised vision transformer models and their emergent semantic abilities to improve the generalization abilities of imitation learning policies. We introduce BC-ViT, an imitation learning algorithm that leverages rich DINO pre-trained Visual Transformer (ViT) patch-level embeddings to obtain better generalization when learning through demonstrations. Our learner sees the world by clustering appearance features into semantic concepts, forming stable keypoints that generalize across a wide range of appearance variations and object types. We show that this representation enables generalized behaviour by evaluating imitation learning across a diverse dataset of object manipulation tasks. Our method, data and evaluation approach are made available to facilitate further study of generalization in Imitation Learners.