 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFairness in Reinforcement Learning with Bisimulation Metrics
Dec 22, 2024



Ensuring long-term fairness is crucial when developing automated decision making systems, specifically in dynamic and sequential environments. By maximizing their reward without consideration of fairness, AI agents can introduce disparities in their treatment of groups or individuals. In this paper, we establish the connection between bisimulation metrics and group fairness in reinforcement learning. We propose a novel approach that leverages bisimulation metrics to learn reward functions and observation dynamics, ensuring that learners treat groups fairly while reflecting the original problem. We demonstrate the effectiveness of our method in addressing disparities in sequential decision making problems through empirical evaluation on a standard fairness benchmark consisting of lending and college admission scenarios.
Policy Gradient Methods in the Presence of Symmetries and State Abstractions
May 09, 2023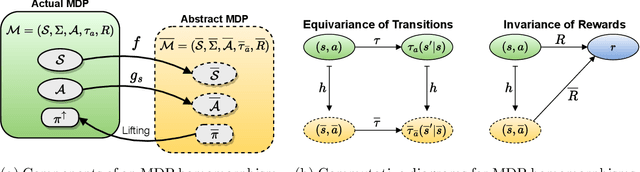
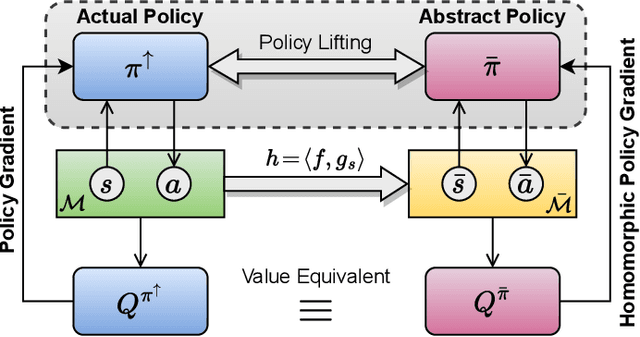
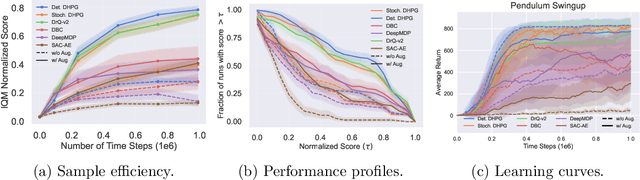
Reinforcement learning on high-dimensional and complex problems relies on abstraction for improved efficiency and generalization. In this paper, we study abstraction in the continuous-control setting, and extend the definition of MDP homomorphisms to the setting of continuous state and action spaces. We derive a policy gradient theorem on the abstract MDP for both stochastic and deterministic policies. Our policy gradient results allow for leveraging approximate symmetries of the environment for policy optimization. Based on these theorems, we propose a family of actor-critic algorithms that are able to learn the policy and the MDP homomorphism map simultaneously, using the lax bisimulation metric. Finally, we introduce a series of environments with continuous symmetries to further demonstrate the ability of our algorithm for action abstraction in the presence of such symmetries. We demonstrate the effectiveness of our method on our environments, as well as on challenging visual control tasks from the DeepMind Control Suite. Our method's ability to utilize MDP homomorphisms for representation learning leads to improved performance, and the visualizations of the latent space clearly demonstrate the structure of the learned abstraction.
Hypernetworks for Zero-shot Transfer in Reinforcement Learning
Nov 28, 2022
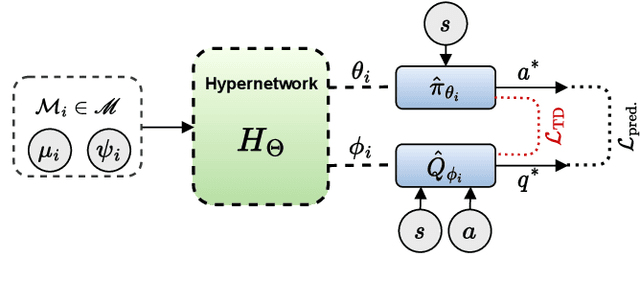
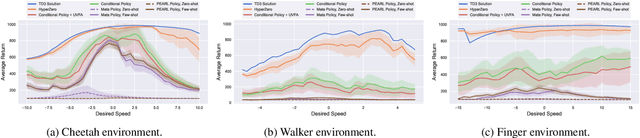
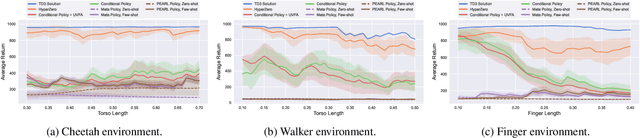
In this paper, hypernetworks are trained to generate behaviors across a range of unseen task conditions, via a novel TD-based training objective and data from a set of near-optimal RL solutions for training tasks. This work relates to meta RL, contextual RL, and transfer learning, with a particular focus on zero-shot performance at test time, enabled by knowledge of the task parameters (also known as context). Our technical approach is based upon viewing each RL algorithm as a mapping from the MDP specifics to the near-optimal value function and policy and seek to approximate it with a hypernetwork that can generate near-optimal value functions and policies, given the parameters of the MDP. We show that, under certain conditions, this mapping can be considered as a supervised learning problem. We empirically evaluate the effectiveness of our method for zero-shot transfer to new reward and transition dynamics on a series of continuous control tasks from DeepMind Control Suite. Our method demonstrates significant improvements over baselines from multitask and meta RL approaches.
Continuous MDP Homomorphisms and Homomorphic Policy Gradient
Sep 15, 2022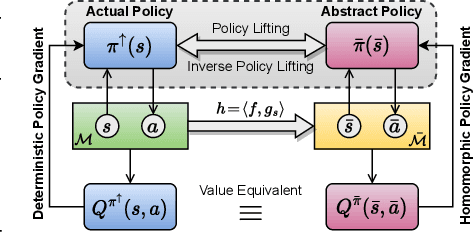
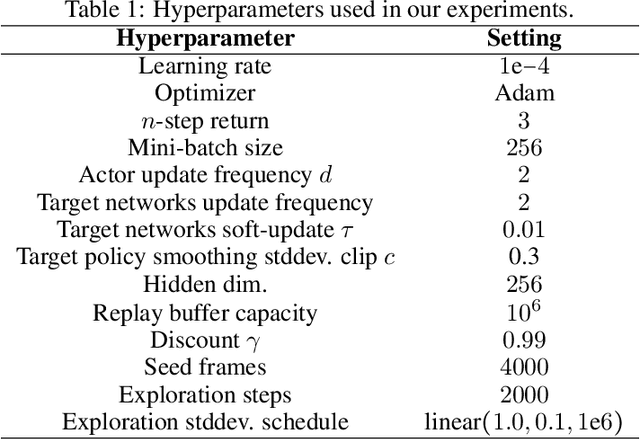
Abstraction has been widely studied as a way to improve the efficiency and generalization of reinforcement learning algorithms. In this paper, we study abstraction in the continuous-control setting. We extend the definition of MDP homomorphisms to encompass continuous actions in continuous state spaces. We derive a policy gradient theorem on the abstract MDP, which allows us to leverage approximate symmetries of the environment for policy optimization. Based on this theorem, we propose an actor-critic algorithm that is able to learn the policy and the MDP homomorphism map simultaneously, using the lax bisimulation metric. We demonstrate the effectiveness of our method on benchmark tasks in the DeepMind Control Suite. Our method's ability to utilize MDP homomorphisms for representation learning leads to improved performance when learning from pixel observations.
Learning Intuitive Physics with Multimodal Generative Models
Jan 19, 2021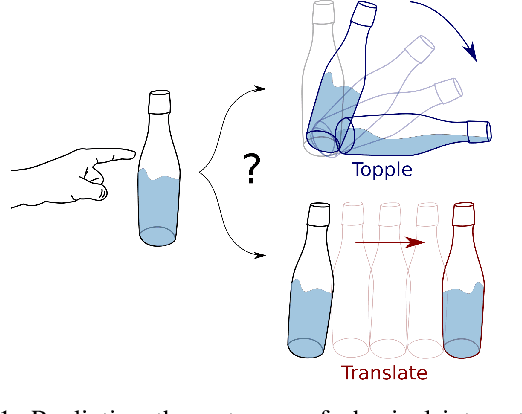
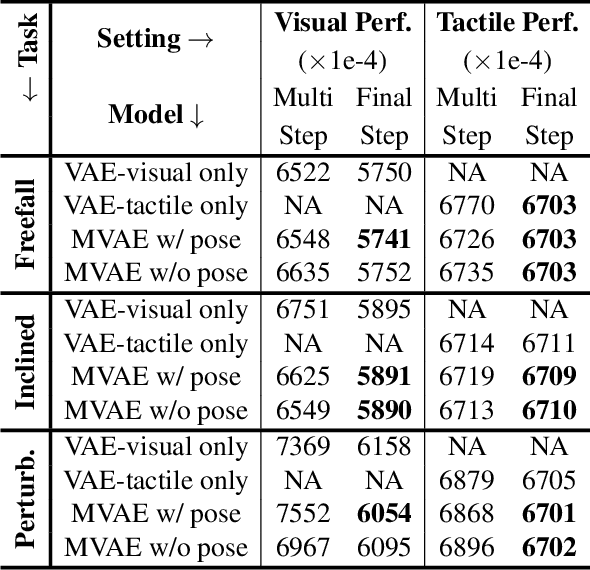

Predicting the future interaction of objects when they come into contact with their environment is key for autonomous agents to take intelligent and anticipatory actions. This paper presents a perception framework that fuses visual and tactile feedback to make predictions about the expected motion of objects in dynamic scenes. Visual information captures object properties such as 3D shape and location, while tactile information provides critical cues about interaction forces and resulting object motion when it makes contact with the environment. Utilizing a novel See-Through-your-Skin (STS) sensor that provides high resolution multimodal sensing of contact surfaces, our system captures both the visual appearance and the tactile properties of objects. We interpret the dual stream signals from the sensor using a Multimodal Variational Autoencoder (MVAE), allowing us to capture both modalities of contacting objects and to develop a mapping from visual to tactile interaction and vice-versa. Additionally, the perceptual system can be used to infer the outcome of future physical interactions, which we validate through simulated and real-world experiments in which the resting state of an object is predicted from given initial conditions.
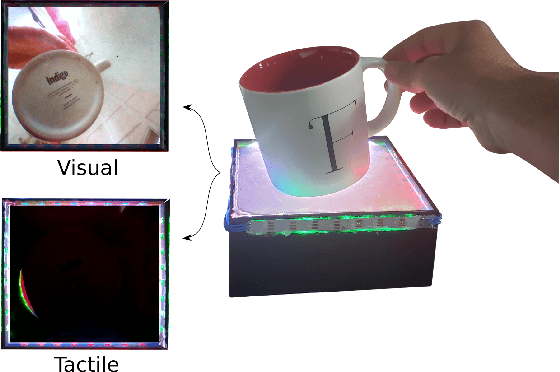
Seeing Through your Skin: Recognizing Objects with a Novel Visuotactile Sensor
Dec 14, 2020
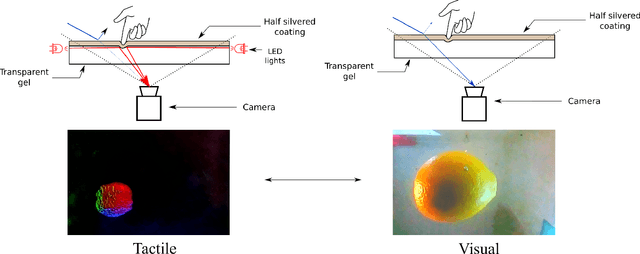
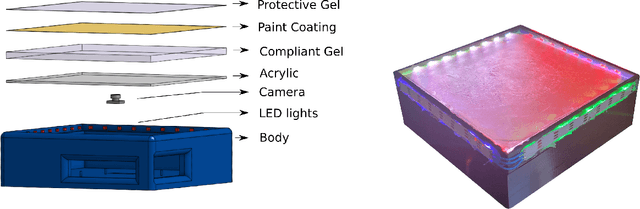
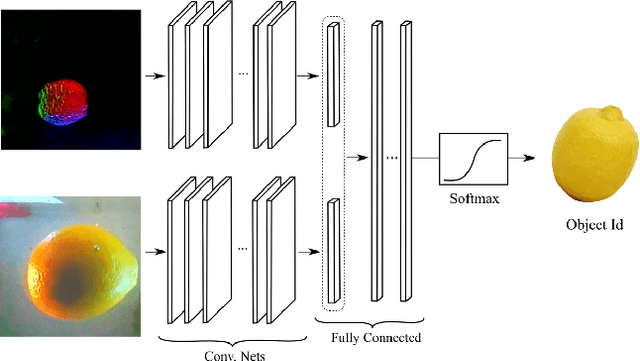
We introduce a new class of vision-based sensor and associated algorithmic processes that combine visual imaging with high-resolution tactile sending, all in a uniform hardware and computational architecture. We demonstrate the sensor's efficacy for both multi-modal object recognition and metrology. Object recognition is typically formulated as an unimodal task, but by combining two sensor modalities we show that we can achieve several significant performance improvements. This sensor, named the See-Through-your-Skin sensor (STS), is designed to provide rich multi-modal sensing of contact surfaces. Inspired by recent developments in optical tactile sensing technology, we address a key missing feature of these sensors: the ability to capture a visual perspective of the region beyond the contact surface. Whereas optical tactile sensors are typically opaque, we present a sensor with a semitransparent skin that has the dual capabilities of acting as a tactile sensor and/or as a visual camera depending on its internal lighting conditions. This paper details the design of the sensor, showcases its dual sensing capabilities, and presents a deep learning architecture that fuses vision and touch. We validate the ability of the sensor to classify household objects, recognize fine textures, and infer their physical properties both through numerical simulations and experiments with a smart countertop prototype.
Learning the Latent Space of Robot Dynamics for Cutting Interaction Inference
Jul 22, 2020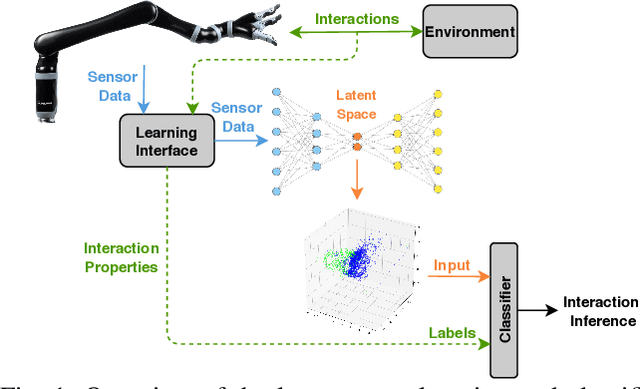
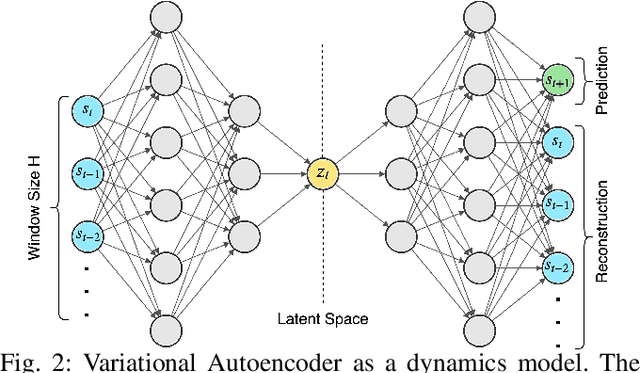

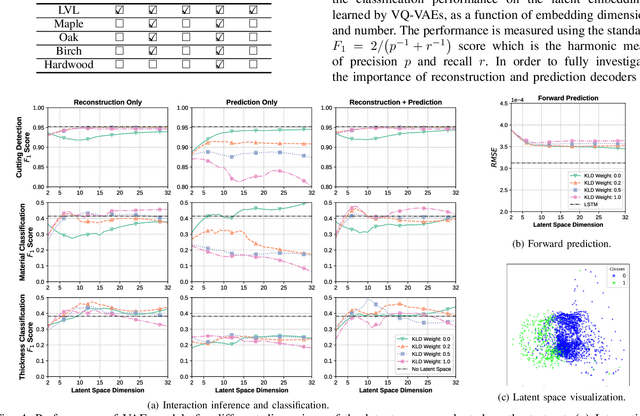
Utilization of latent space to capture a lower-dimensional representation of a complex dynamics model is explored in this work. The targeted application is of a robotic manipulator executing a complex environment interaction task, in particular, cutting a wooden object. We train two flavours of Variational Autoencoders---standard and Vector-Quantised---to learn the latent space which is then used to infer certain properties of the cutting operation, such as whether the robot is cutting or not, as well as, material and geometry of the object being cut. The two VAE models are evaluated with reconstruction, prediction and a combined reconstruction/prediction decoders. The results demonstrate the expressiveness of the latent space for robotic interaction inference and the competitive prediction performance against recurrent neural networks.
Cascaded Gaussian Processes for Data-efficient Robot Dynamics Learning
Oct 05, 2019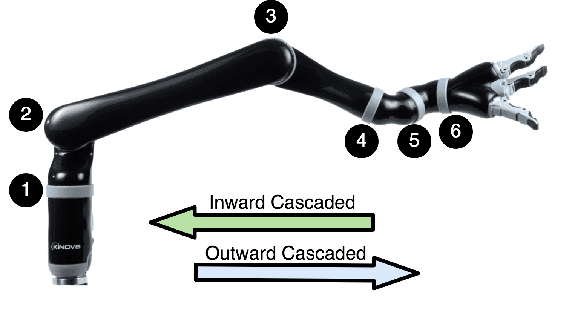
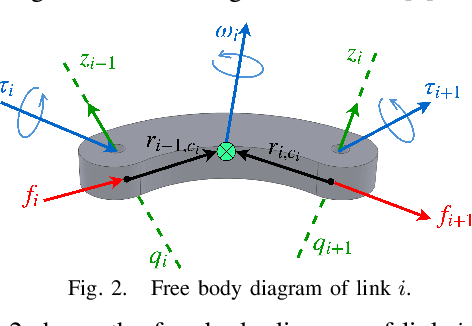
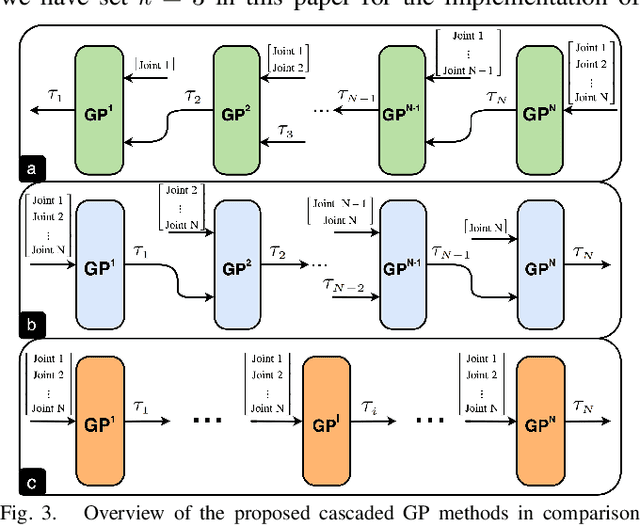
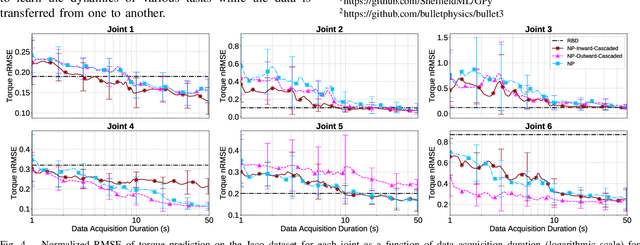
Motivated by the recursive Newton-Euler formulation, we propose a novel cascaded Gaussian process learning framework for the inverse dynamics of robot manipulators. This approach leads to a significant dimensionality reduction which in turn results in better learning and data efficiency. We explore two formulations for the cascading: the inward and outward, both along the manipulator chain topology. The learned modeling is tested in conjunction with the classical inverse dynamics model (semi-parametric) and on its own (non-parametric) in the context of feed-forward control of the arm. Experimental results are obtained with Jaco 2 six-DOF and SARCOS seven-DOF manipulators for randomly defined sinusoidal motions of the joints in order to evaluate the performance of cascading against the standard GP learning. In addition, experiments are conducted using Jaco 2 on a task emulating a pouring maneuver. Results indicate a consistent improvement in learning speed with the inward cascaded GP model and an overall improvement in data efficiency and generalization.