 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReefMapGS: Enabling Large-Scale Underwater Reconstruction by Closing the Loop Between Multimodal SLAM and Gaussian Splatting
Apr 13, 20263D Gaussian Splatting is a powerful visual representation, providing high-quality and efficient 3D scene reconstruction, but it is crucially dependent on accurate camera poses typically obtained from computationally intensive processes like structure-from-motion that are unsuitable for field robot applications. However, in these domains, multimodal sensor data from acoustic, inertial, pressure, and visual sensors are available and suitable for pose-graph optimization-based SLAM methods that can estimate the vehicle's trajectory and thus our needed camera poses while providing uncertainty. We propose a 3DGS-based incremental reconstruction framework, ReefMapGS, that builds an initial model from a high certainty region and progressively expands to incorporate the whole scene. We reconstruct the scene incrementally by interleaving local tracking of new image observations with optimization of the underlying 3DGS scene. These refined poses are integrated back into the pose-graph to globally optimize the whole trajectory. We show COLMAP-free 3D reconstruction of two underwater reef sites with complex geometry as well as more accurate global pose estimation of our AUV over survey trajectories spanning up to 700 m.
Autonomous Search for Sparsely Distributed Visual Phenomena through Environmental Context Modeling
Mar 10, 2026Autonomous underwater vehicles (AUVs) are increasingly used to survey coral reefs, yet efficiently locating specific coral species of interest remains difficult: target species are often sparsely distributed across the reef, and an AUV with limited battery life cannot afford to search everywhere. When detections of the target itself are too sparse to provide directional guidance, the robot benefits from an additional signal to decide where to look next. We propose using the visual environmental context -- the habitat features that tend to co-occur with a target species -- as that signal. Because context features are spatially denser and often vary more smoothly than target detections, we hypothesize that a reward function targeted at broader environmental context will enable adaptive planners to make better decisions on where to go next, even in regions where no target has yet been observed. Starting from a single labeled image, our method uses patch-level DINOv2 embeddings to perform one-shot detections of both the target species and its surrounding context online. We validate our approach using real imagery collected by an AUV at two reef sites in St. John, U.S. Virgin Islands, simulating the robot's motion offline. Our results demonstrate that one-shot detection combined with adaptive context modeling enables efficient autonomous surveying, sampling up to 75$\%$ of the target in roughly half the time required by exhaustive coverage when the target is sparsely distributed, and outperforming search strategies that only use target detections.
AMP2026: A Multi-Platform Marine Robotics Dataset for Tracking and Mapping
Mar 04, 2026Marine environments present significant challenges for perception and autonomy due to dynamic surfaces, limited visibility, and complex interactions between aerial, surface, and submerged sensing modalities. This paper introduces the Aerial Marine Perception Dataset (AMP2026), a multi-platform marine robotics dataset collected across multiple field deployments designed to support research in two primary areas: multi-view tracking and marine environment mapping. The dataset includes synchronized data from aerial drones, boat-mounted cameras, and submerged robotic platforms, along with associated localization and telemetry information. The goal of this work is to provide a publicly available dataset enabling research in marine perception and multi-robot observation scenarios. This paper describes the data collection methodology, sensor configurations, dataset organization, and intended research tasks supported by the dataset.
Measuring and Minimizing Disturbance of Marine Animals to Underwater Vehicles
Jun 12, 2025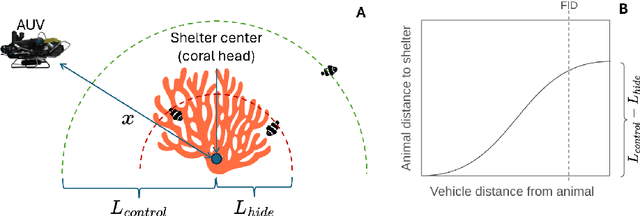


Do fish respond to the presence of underwater vehicles, potentially biasing our estimates about them? If so, are there strategies to measure and mitigate this response? This work provides a theoretical and practical framework towards bias-free estimation of animal behavior from underwater vehicle observations. We also provide preliminary results from the field in coral reef environments to address these questions.
DataS^3: Dataset Subset Selection for Specialization
Apr 22, 2025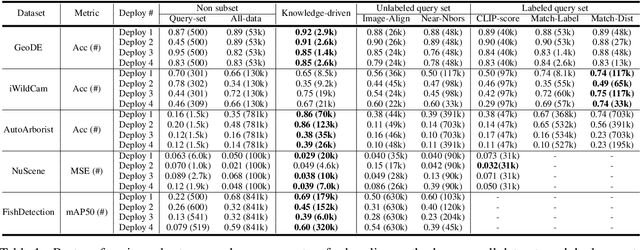
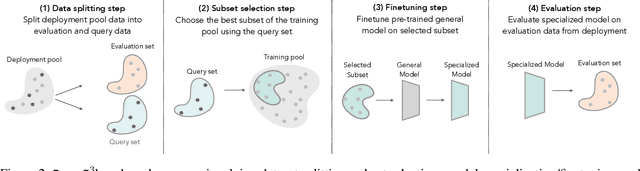
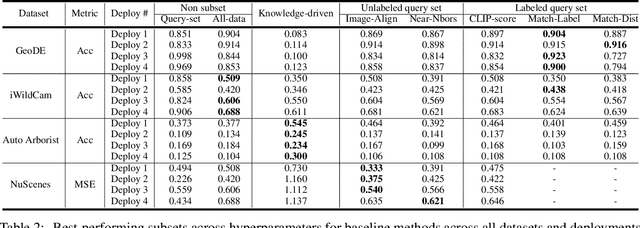
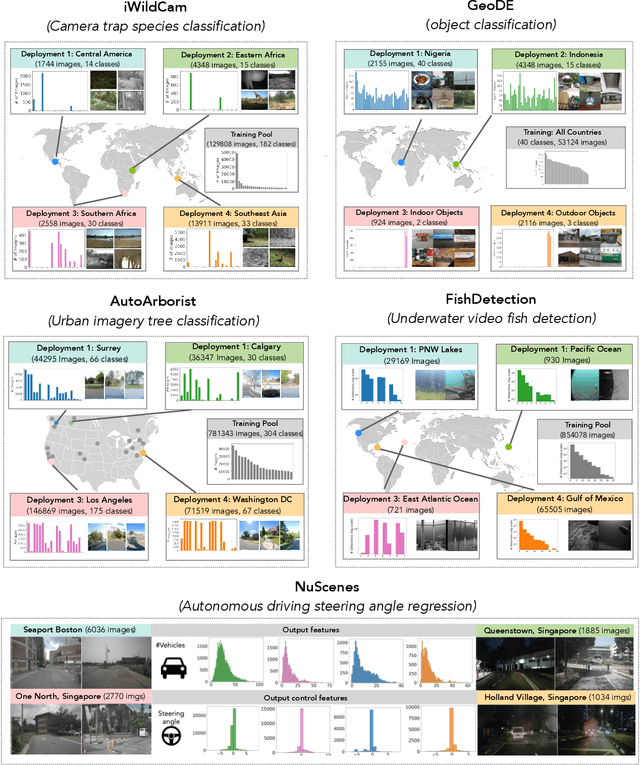
In many real-world machine learning (ML) applications (e.g. detecting broken bones in x-ray images, detecting species in camera traps), in practice models need to perform well on specific deployments (e.g. a specific hospital, a specific national park) rather than the domain broadly. However, deployments often have imbalanced, unique data distributions. Discrepancy between the training distribution and the deployment distribution can lead to suboptimal performance, highlighting the need to select deployment-specialized subsets from the available training data. We formalize dataset subset selection for specialization (DS3): given a training set drawn from a general distribution and a (potentially unlabeled) query set drawn from the desired deployment-specific distribution, the goal is to select a subset of the training data that optimizes deployment performance. We introduce DataS^3; the first dataset and benchmark designed specifically for the DS3 problem. DataS^3 encompasses diverse real-world application domains, each with a set of distinct deployments to specialize in. We conduct a comprehensive study evaluating algorithms from various families--including coresets, data filtering, and data curation--on DataS^3, and find that general-distribution methods consistently fail on deployment-specific tasks. Additionally, we demonstrate the existence of manually curated (deployment-specific) expert subsets that outperform training on all available data with accuracy gains up to 51.3 percent. Our benchmark highlights the critical role of tailored dataset curation in enhancing performance and training efficiency on deployment-specific distributions, which we posit will only become more important as global, public datasets become available across domains and ML models are deployed in the real world.
SeaSplat: Representing Underwater Scenes with 3D Gaussian Splatting and a Physically Grounded Image Formation Model
Sep 25, 2024We introduce SeaSplat, a method to enable real-time rendering of underwater scenes leveraging recent advances in 3D radiance fields. Underwater scenes are challenging visual environments, as rendering through a medium such as water introduces both range and color dependent effects on image capture. We constrain 3D Gaussian Splatting (3DGS), a recent advance in radiance fields enabling rapid training and real-time rendering of full 3D scenes, with a physically grounded underwater image formation model. Applying SeaSplat to the real-world scenes from SeaThru-NeRF dataset, a scene collected by an underwater vehicle in the US Virgin Islands, and simulation-degraded real-world scenes, not only do we see increased quantitative performance on rendering novel viewpoints from the scene with the medium present, but are also able to recover the underlying true color of the scene and restore renders to be without the presence of the intervening medium. We show that the underwater image formation helps learn scene structure, with better depth maps, as well as show that our improvements maintain the significant computational improvements afforded by leveraging a 3D Gaussian representation.
ReefGlider: A highly maneuverable vectored buoyancy engine based underwater robot
May 09, 2024There exists a capability gap in the design of currently available autonomous underwater vehicles (AUV). Most AUVs use a set of thrusters, and optionally control surfaces, to control their depth and pose. AUVs utilizing thrusters can be highly maneuverable, making them well-suited to operate in complex environments such as in close-proximity to coral reefs. However, they are inherently power-inefficient and produce significant noise and disturbance. Underwater gliders, on the other hand, use changes in buoyancy and center of mass, in combination with a control surface to move around. They are extremely power efficient but not very maneuverable. Gliders are designed for long-range missions that do not require precision maneuvering. Furthermore, since gliders only activate the buoyancy engine for small time intervals, they do not disturb the environment and can also be used for passive acoustic observations. In this paper we present ReefGlider, a novel AUV that uses only buoyancy for control but is still highly maneuverable from additional buoyancy control devices. ReefGlider bridges the gap between the capabilities of thruster-driven AUVs and gliders. These combined characteristics make ReefGlider ideal for tasks such as long-term visual and acoustic monitoring of coral reefs. We present the overall design and implementation of the system, as well as provide analysis of some of its capabilities.
Biological Hotspot Mapping in Coral Reefs with Robotic Visual Surveys
May 03, 2023
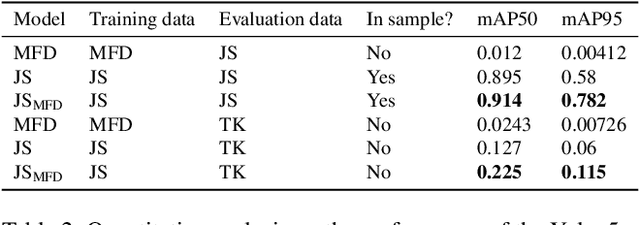

Coral reefs are fast-changing and complex ecosystems that are crucial to monitor and study. Biological hotspot detection can help coral reef managers prioritize limited resources for monitoring and intervention tasks. Here, we explore the use of autonomous underwater vehicles (AUVs) with cameras, coupled with visual detectors and photogrammetry, to map and identify these hotspots. This approach can provide high spatial resolution information in fast feedback cycles. To the best of our knowledge, we present one of the first attempts at using an AUV to gather visually-observed, fine-grain biological hotspot maps in concert with topography of a coral reefs. Our hotspot maps correlate with rugosity, an established proxy metric for coral reef biodiversity and abundance, as well as with our visual inspections of the 3D reconstruction. We also investigate issues of scaling this approach when applied to new reefs by using these visual detectors pre-trained on large public datasets.
DeepSeeColor: Realtime Adaptive Color Correction for Autonomous Underwater Vehicles via Deep Learning Methods
Mar 07, 2023

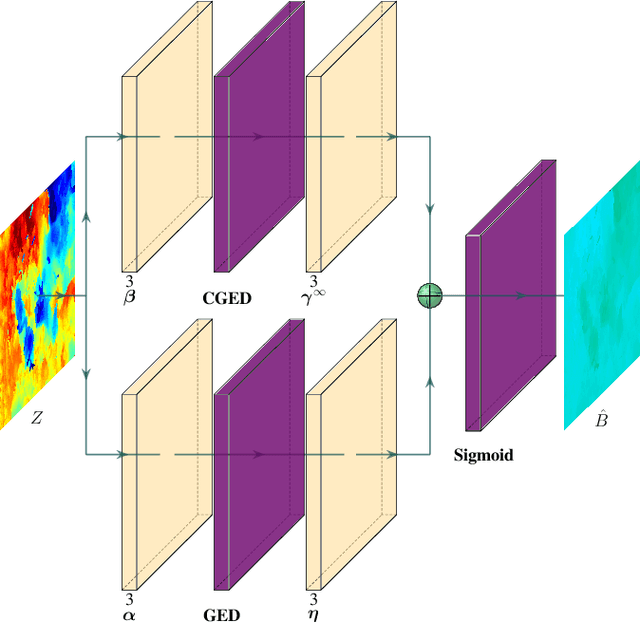
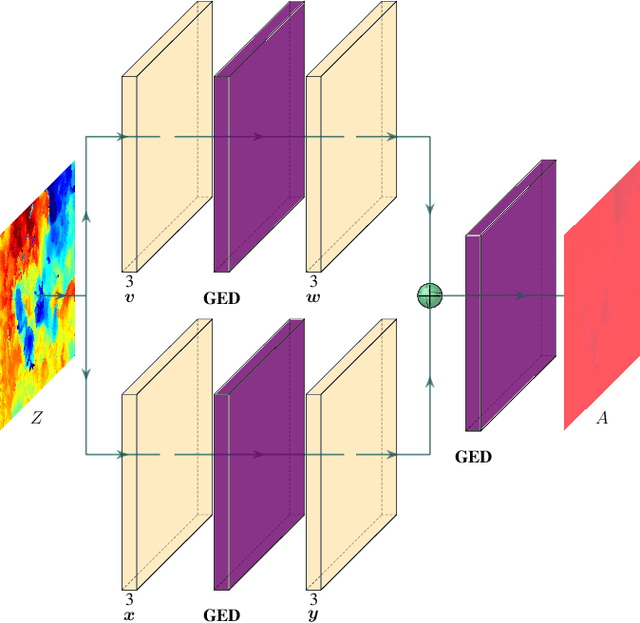
Successful applications of complex vision-based behaviours underwater have lagged behind progress in terrestrial and aerial domains. This is largely due to the degraded image quality resulting from the physical phenomena involved in underwater image formation. Spectrally-selective light attenuation drains some colors from underwater images while backscattering adds others, making it challenging to perform vision-based tasks underwater. State-of-the-art methods for underwater color correction optimize the parameters of image formation models to restore the full spectrum of color to underwater imagery. However, these methods have high computational complexity that is unfavourable for realtime use by autonomous underwater vehicles (AUVs), as a result of having been primarily designed for offline color correction. Here, we present DeepSeeColor, a novel algorithm that combines a state-of-the-art underwater image formation model with the computational efficiency of deep learning frameworks. In our experiments, we show that DeepSeeColor offers comparable performance to the popular "Sea-Thru" algorithm (Akkaynak & Treibitz, 2019) while being able to rapidly process images at up to 60Hz, thus making it suitable for use onboard AUVs as a preprocessing step to enable more robust vision-based behaviours.
Semi-Supervised Visual Tracking of Marine Animals using Autonomous Underwater Vehicles
Feb 14, 2023In-situ visual observations of marine organisms is crucial to developing behavioural understandings and their relations to their surrounding ecosystem. Typically, these observations are collected via divers, tags, and remotely-operated or human-piloted vehicles. Recently, however, autonomous underwater vehicles equipped with cameras and embedded computers with GPU capabilities are being developed for a variety of applications, and in particular, can be used to supplement these existing data collection mechanisms where human operation or tags are more difficult. Existing approaches have focused on using fully-supervised tracking methods, but labelled data for many underwater species are severely lacking. Semi-supervised trackers may offer alternative tracking solutions because they require less data than fully-supervised counterparts. However, because there are not existing realistic underwater tracking datasets, the performance of semi-supervised tracking algorithms in the marine domain is not well understood. To better evaluate their performance and utility, in this paper we provide (1) a novel dataset specific to marine animals located at http://warp.whoi.edu/vmat/, (2) an evaluation of state-of-the-art semi-supervised algorithms in the context of underwater animal tracking, and (3) an evaluation of real-world performance through demonstrations using a semi-supervised algorithm on-board an autonomous underwater vehicle to track marine animals in the wild.