 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning from Feedback: Semantic Enhancement for Object SLAM Using Foundation Models
Nov 11, 2024



Semantic Simultaneous Localization and Mapping (SLAM) systems struggle to map semantically similar objects in close proximity, especially in cluttered indoor environments. We introduce Semantic Enhancement for Object SLAM (SEO-SLAM), a novel SLAM system that leverages Vision-Language Models (VLMs) and Multimodal Large Language Models (MLLMs) to enhance object-level semantic mapping in such environments. SEO-SLAM tackles existing challenges by (1) generating more specific and descriptive open-vocabulary object labels using MLLMs, (2) simultaneously correcting factors causing erroneous landmarks, and (3) dynamically updating a multiclass confusion matrix to mitigate object detector biases. Our approach enables more precise distinctions between similar objects and maintains map coherence by reflecting scene changes through MLLM feedback. We evaluate SEO-SLAM on our challenging dataset, demonstrating enhanced accuracy and robustness in environments with multiple similar objects. Our system outperforms existing approaches in terms of landmark matching accuracy and semantic consistency. Results show the feedback from MLLM improves object-centric semantic mapping. Our dataset is publicly available at: jungseokhong.com/SEO-SLAM.
SeaSplat: Representing Underwater Scenes with 3D Gaussian Splatting and a Physically Grounded Image Formation Model
Sep 25, 2024We introduce SeaSplat, a method to enable real-time rendering of underwater scenes leveraging recent advances in 3D radiance fields. Underwater scenes are challenging visual environments, as rendering through a medium such as water introduces both range and color dependent effects on image capture. We constrain 3D Gaussian Splatting (3DGS), a recent advance in radiance fields enabling rapid training and real-time rendering of full 3D scenes, with a physically grounded underwater image formation model. Applying SeaSplat to the real-world scenes from SeaThru-NeRF dataset, a scene collected by an underwater vehicle in the US Virgin Islands, and simulation-degraded real-world scenes, not only do we see increased quantitative performance on rendering novel viewpoints from the scene with the medium present, but are also able to recover the underlying true color of the scene and restore renders to be without the presence of the intervening medium. We show that the underwater image formation helps learn scene structure, with better depth maps, as well as show that our improvements maintain the significant computational improvements afforded by leveraging a 3D Gaussian representation.
Open-Set Semantic Uncertainty Aware Metric-Semantic Graph Matching
Sep 17, 2024Underwater object-level mapping requires incorporating visual foundation models to handle the uncommon and often previously unseen object classes encountered in marine scenarios. In this work, a metric of semantic uncertainty for open-set object detections produced by visual foundation models is calculated and then incorporated into an object-level uncertainty tracking framework. Object-level uncertainties and geometric relationships between objects are used to enable robust object-level loop closure detection for unknown object classes. The above loop closure detection problem is formulated as a graph-matching problem. While graph matching, in general, is NP-Complete, a solver for an equivalent formulation of the proposed graph matching problem as a graph editing problem is tested on multiple challenging underwater scenes. Results for this solver as well as three other solvers demonstrate that the proposed methods are feasible for real-time use in marine environments for the robust, open-set, multi-object, semantic-uncertainty-aware loop closure detection. Further experimental results on the KITTI dataset demonstrate that the method generalizes to large-scale terrestrial scenes.
ShapeICP: Iterative Category-level Object Pose and Shape Estimation from Depth
Aug 23, 2024Category-level object pose and shape estimation from a single depth image has recently drawn research attention due to its wide applications in robotics and self-driving. The task is particularly challenging because the three unknowns, object pose, object shape, and model-to-measurement correspondences, are compounded together but only a single view of depth measurements is provided. The vast majority of the prior work heavily relies on data-driven approaches to obtain solutions to at least one of the unknowns and typically two, running with the risk of failing to generalize to unseen domains. The shape representations used in the prior work also mainly focus on point cloud and signed distance field (SDF). In stark contrast to the prior work, we approach the problem using an iterative estimation method that does not require learning from any pose-annotated data. In addition, we adopt a novel mesh-based object active shape model that has not been explored by the previous literature. Our algorithm, named ShapeICP, has its foundation in the iterative closest point (ICP) algorithm but is equipped with additional features for the category-level pose and shape estimation task. The results show that even without using any pose-annotated data, ShapeICP surpasses many data-driven approaches that rely on the pose data for training, opening up new solution space for researchers to consider.
LOSS-SLAM: Lightweight Open-Set Semantic Simultaneous Localization and Mapping
Apr 05, 2024



Enabling robots to understand the world in terms of objects is a critical building block towards higher level autonomy. The success of foundation models in vision has created the ability to segment and identify nearly all objects in the world. However, utilizing such objects to localize the robot and build an open-set semantic map of the world remains an open research question. In this work, a system of identifying, localizing, and encoding objects is tightly coupled with probabilistic graphical models for performing open-set semantic simultaneous localization and mapping (SLAM). Results are presented demonstrating that the proposed lightweight object encoding can be used to perform more accurate object-based SLAM than existing open-set methods, closed-set methods, and geometric methods while incurring a lower computational overhead than existing open-set mapping methods.
Opti-Acoustic Semantic SLAM with Unknown Objects in Underwater Environments
Mar 19, 2024Despite recent advances in semantic Simultaneous Localization and Mapping (SLAM) for terrestrial and aerial applications, underwater semantic SLAM remains an open and largely unaddressed research problem due to the unique sensing modalities and the object classes found underwater. This paper presents an object-based semantic SLAM method for underwater environments that can identify, localize, classify, and map a wide variety of marine objects without a priori knowledge of the object classes present in the scene. The method performs unsupervised object segmentation and object-level feature aggregation, and then uses opti-acoustic sensor fusion for object localization. Probabilistic data association is used to determine observation to landmark correspondences. Given such correspondences, the method then jointly optimizes landmark and vehicle position estimates. Indoor and outdoor underwater datasets with a wide variety of objects and challenging acoustic and lighting conditions are collected for evaluation and made publicly available. Quantitative and qualitative results show the proposed method achieves reduced trajectory error compared to baseline methods, and is able to obtain comparable map accuracy to a baseline closed-set method that requires hand-labeled data of all objects in the scene.
GAPSLAM: Blending Gaussian Approximation and Particle Filters for Real-Time Non-Gaussian SLAM
Mar 24, 2023Inferring the posterior distribution in SLAM is critical for evaluating the uncertainty in localization and mapping, as well as supporting subsequent planning tasks aiming to reduce uncertainty for safe navigation. However, real-time full posterior inference techniques, such as Gaussian approximation and particle filters, either lack expressiveness for representing non-Gaussian posteriors or suffer from performance degeneracy when estimating high-dimensional posteriors. Inspired by the complementary strengths of Gaussian approximation and particle filters$\unicode{x2013}$scalability and non-Gaussian estimation, respectively$\unicode{x2013}$we blend these two approaches to infer marginal posteriors in SLAM. Specifically, Gaussian approximation provides robot pose distributions on which particle filters are conditioned to sample landmark marginals. In return, the maximum a posteriori point among these samples can be used to reset linearization points in the nonlinear optimization solver of the Gaussian approximation, facilitating the pursuit of global optima. We demonstrate the scalability, generalizability, and accuracy of our algorithm for real-time full posterior inference on realworld range-only SLAM and object-based bearing-only SLAM datasets.
NeuSE: Neural SE(3)-Equivariant Embedding for Consistent Spatial Understanding with Objects
Mar 13, 2023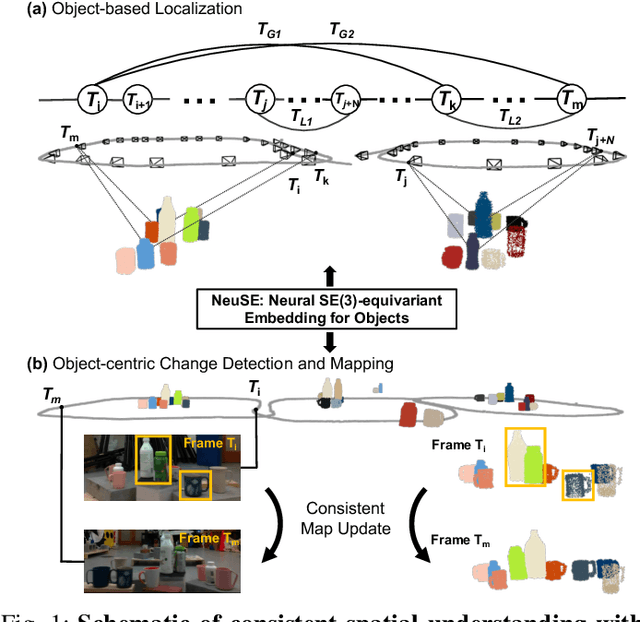
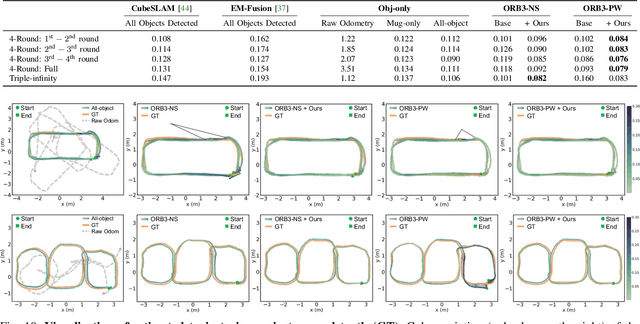
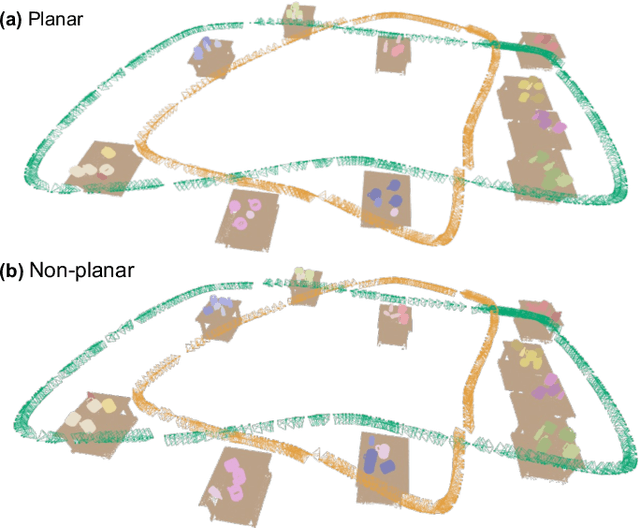
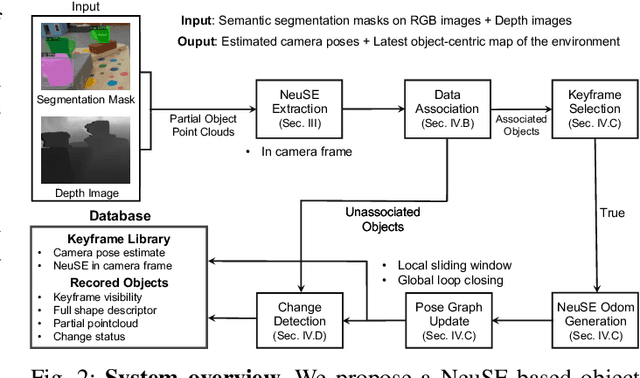
We present NeuSE, a novel Neural SE(3)-Equivariant Embedding for objects, and illustrate how it supports object SLAM for consistent spatial understanding with long-term scene changes. NeuSE is a set of latent object embeddings created from partial object observations. It serves as a compact point cloud surrogate for complete object models, encoding full shape information while transforming SE(3)-equivariantly in tandem with the object in the physical world. With NeuSE, relative frame transforms can be directly derived from inferred latent codes. Our proposed SLAM paradigm, using NeuSE for object shape and pose characterization, can operate independently or in conjunction with typical SLAM systems. It directly infers SE(3) camera pose constraints that are compatible with general SLAM pose graph optimization, while also maintaining a lightweight object-centric map that adapts to real-world changes. Our approach is evaluated on synthetic and real-world sequences featuring changed objects and shows improved localization accuracy and change-aware mapping capability, when working either standalone or jointly with a common SLAM pipeline.
Data-Association-Free Landmark-based SLAM
Mar 07, 2023



We study landmark-based SLAM with unknown data association: our robot navigates in a completely unknown environment and has to simultaneously reason over its own trajectory, the positions of an unknown number of landmarks in the environment, and potential data associations between measurements and landmarks. This setup is interesting since: (i) it arises when recovering from data association failures or from SLAM with information-poor sensors, (ii) it sheds light on fundamental limits (and hardness) of landmark-based SLAM problems irrespective of the front-end data association method, and (iii) it generalizes existing approaches where data association is assumed to be known or partially known. We approach the problem by splitting it into an inner problem of estimating the trajectory, landmark positions and data associations and an outer problem of estimating the number of landmarks. Our approach creates useful and novel connections with existing techniques from discrete-continuous optimization (e.g., k-means clustering), which has the potential to trigger novel research. We demonstrate the proposed approaches in extensive simulations and on real datasets and show that the proposed techniques outperform typical data association baselines and are even competitive against an "oracle" baseline which has access to the number of landmarks and an initial guess for each landmark.
Certifiably Correct Range-Aided SLAM
Feb 22, 2023We present the first algorithm capable of efficiently computing certifiably optimal solutions to range-aided simultaneous localization and mapping (RA-SLAM) problems. Robotic navigation systems are increasingly incorporating point-to-point ranging sensors, leading state estimation which takes the form of RA-SLAM. However, the RA-SLAM problem is more difficult to solve than traditional pose-graph SLAM; ranging sensor models introduce additional non-convexity, unlike pose-pose or pose-landmark measurements, a single range measurement does not uniquely determine the relative transform between the involved sensors, and RA-SLAM inference is highly sensitive to initial estimates. Our approach relaxes the RA-SLAM problem to a semidefinite program (SDP), which we show how to solve efficiently using the Riemannian staircase methodology. The solution of this SDP provides a high-quality initialization for our original RA-SLAM problem, which is subsequently refined via local optimization, as well as a lower-bound on the RA-SLAM problem's optimal value. Our algorithm, named certifiably correct RA-SLAM (CORA), applies to problems comprised of arbitrary pose-pose, pose-landmark, and ranging measurements. Evaluation on simulated and real-world marine examples shows that our algorithm frequently produces certifiably optimal RA-SLAM solutions; moreover, even suboptimal estimates are typically within 1-2\% of the optimal value.