 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReefMapGS: Enabling Large-Scale Underwater Reconstruction by Closing the Loop Between Multimodal SLAM and Gaussian Splatting
Apr 13, 20263D Gaussian Splatting is a powerful visual representation, providing high-quality and efficient 3D scene reconstruction, but it is crucially dependent on accurate camera poses typically obtained from computationally intensive processes like structure-from-motion that are unsuitable for field robot applications. However, in these domains, multimodal sensor data from acoustic, inertial, pressure, and visual sensors are available and suitable for pose-graph optimization-based SLAM methods that can estimate the vehicle's trajectory and thus our needed camera poses while providing uncertainty. We propose a 3DGS-based incremental reconstruction framework, ReefMapGS, that builds an initial model from a high certainty region and progressively expands to incorporate the whole scene. We reconstruct the scene incrementally by interleaving local tracking of new image observations with optimization of the underlying 3DGS scene. These refined poses are integrated back into the pose-graph to globally optimize the whole trajectory. We show COLMAP-free 3D reconstruction of two underwater reef sites with complex geometry as well as more accurate global pose estimation of our AUV over survey trajectories spanning up to 700 m.
IBURD: Image Blending for Underwater Robotic Detection
Feb 24, 2025We present an image blending pipeline, \textit{IBURD}, that creates realistic synthetic images to assist in the training of deep detectors for use on underwater autonomous vehicles (AUVs) for marine debris detection tasks. Specifically, IBURD generates both images of underwater debris and their pixel-level annotations, using source images of debris objects, their annotations, and target background images of marine environments. With Poisson editing and style transfer techniques, IBURD is even able to robustly blend transparent objects into arbitrary backgrounds and automatically adjust the style of blended images using the blurriness metric of target background images. These generated images of marine debris in actual underwater backgrounds address the data scarcity and data variety problems faced by deep-learned vision algorithms in challenging underwater conditions, and can enable the use of AUVs for environmental cleanup missions. Both quantitative and robotic evaluations of IBURD demonstrate the efficacy of the proposed approach for robotic detection of marine debris.
Learning from Feedback: Semantic Enhancement for Object SLAM Using Foundation Models
Nov 11, 2024



Semantic Simultaneous Localization and Mapping (SLAM) systems struggle to map semantically similar objects in close proximity, especially in cluttered indoor environments. We introduce Semantic Enhancement for Object SLAM (SEO-SLAM), a novel SLAM system that leverages Vision-Language Models (VLMs) and Multimodal Large Language Models (MLLMs) to enhance object-level semantic mapping in such environments. SEO-SLAM tackles existing challenges by (1) generating more specific and descriptive open-vocabulary object labels using MLLMs, (2) simultaneously correcting factors causing erroneous landmarks, and (3) dynamically updating a multiclass confusion matrix to mitigate object detector biases. Our approach enables more precise distinctions between similar objects and maintains map coherence by reflecting scene changes through MLLM feedback. We evaluate SEO-SLAM on our challenging dataset, demonstrating enhanced accuracy and robustness in environments with multiple similar objects. Our system outperforms existing approaches in terms of landmark matching accuracy and semantic consistency. Results show the feedback from MLLM improves object-centric semantic mapping. Our dataset is publicly available at: jungseokhong.com/SEO-SLAM.
Opti-Acoustic Semantic SLAM with Unknown Objects in Underwater Environments
Mar 19, 2024Despite recent advances in semantic Simultaneous Localization and Mapping (SLAM) for terrestrial and aerial applications, underwater semantic SLAM remains an open and largely unaddressed research problem due to the unique sensing modalities and the object classes found underwater. This paper presents an object-based semantic SLAM method for underwater environments that can identify, localize, classify, and map a wide variety of marine objects without a priori knowledge of the object classes present in the scene. The method performs unsupervised object segmentation and object-level feature aggregation, and then uses opti-acoustic sensor fusion for object localization. Probabilistic data association is used to determine observation to landmark correspondences. Given such correspondences, the method then jointly optimizes landmark and vehicle position estimates. Indoor and outdoor underwater datasets with a wide variety of objects and challenging acoustic and lighting conditions are collected for evaluation and made publicly available. Quantitative and qualitative results show the proposed method achieves reduced trajectory error compared to baseline methods, and is able to obtain comparable map accuracy to a baseline closed-set method that requires hand-labeled data of all objects in the scene.
Diver Identification Using Anthropometric Data Ratios for Underwater Multi-Human-Robot Collaboration
Sep 29, 2023

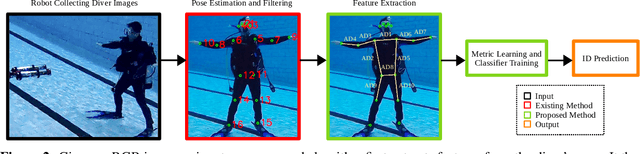
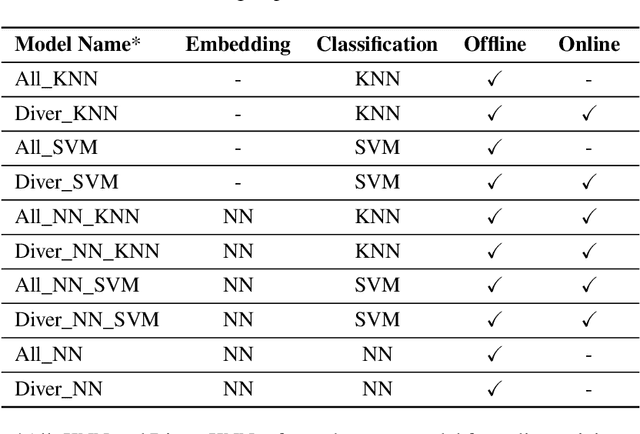
Recent advances in efficient design, perception algorithms, and computing hardware have made it possible to create improved human-robot interaction (HRI) capabilities for autonomous underwater vehicles (AUVs). To conduct secure missions as underwater human-robot teams, AUVs require the ability to accurately identify divers. However, this remains an open problem due to divers' challenging visual features, mainly caused by similar-looking scuba gear. In this paper, we present a novel algorithm that can perform diver identification using either pre-trained models or models trained during deployment. We exploit anthropometric data obtained from diver pose estimates to generate robust features that are invariant to changes in distance and photometric conditions. We also propose an embedding network that maximizes inter-class distances in the feature space and minimizes those for the intra-class features, which significantly improves classification performance. Furthermore, we present an end-to-end diver identification framework that operates on an AUV and evaluate the accuracy of the proposed algorithm. Quantitative results in controlled-water experiments show that our algorithm achieves a high level of accuracy in diver identification.
Self-supervised Wide Baseline Visual Servoing via 3D Equivariance
Sep 12, 2022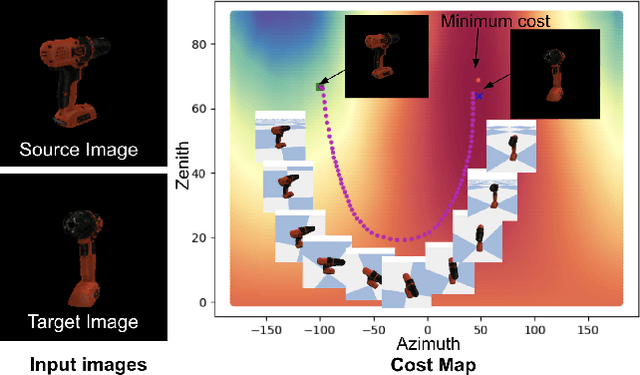
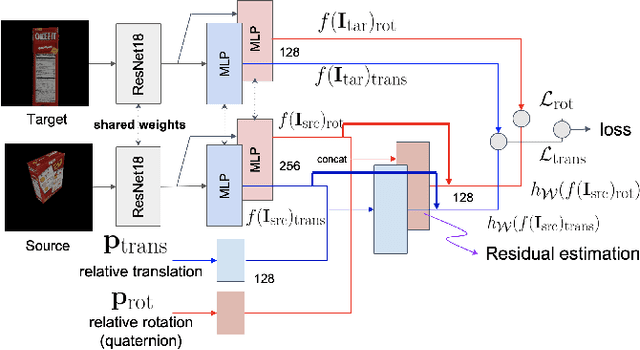

One of the challenging input settings for visual servoing is when the initial and goal camera views are far apart. Such settings are difficult because the wide baseline can cause drastic changes in object appearance and cause occlusions. This paper presents a novel self-supervised visual servoing method for wide baseline images which does not require 3D ground truth supervision. Existing approaches that regress absolute camera pose with respect to an object require 3D ground truth data of the object in the forms of 3D bounding boxes or meshes. We learn a coherent visual representation by leveraging a geometric property called 3D equivariance-the representation is transformed in a predictable way as a function of 3D transformation. To ensure that the feature-space is faithful to the underlying geodesic space, a geodesic preserving constraint is applied in conjunction with the equivariance. We design a Siamese network that can effectively enforce these two geometric properties without requiring 3D supervision. With the learned model, the relative transformation can be inferred simply by following the gradient in the learned space and used as feedback for closed-loop visual servoing. Our method is evaluated on objects from the YCB dataset, showing meaningful outperformance on a visual servoing task, or object alignment task with respect to state-of-the-art approaches that use 3D supervision. Ours yields more than 35% average distance error reduction and more than 90% success rate with 3cm error tolerance.
Using Monocular Vision and Human Body Priors for AUVs to Autonomously Approach Divers
Nov 05, 2021
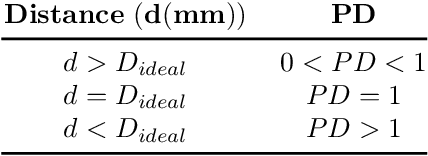

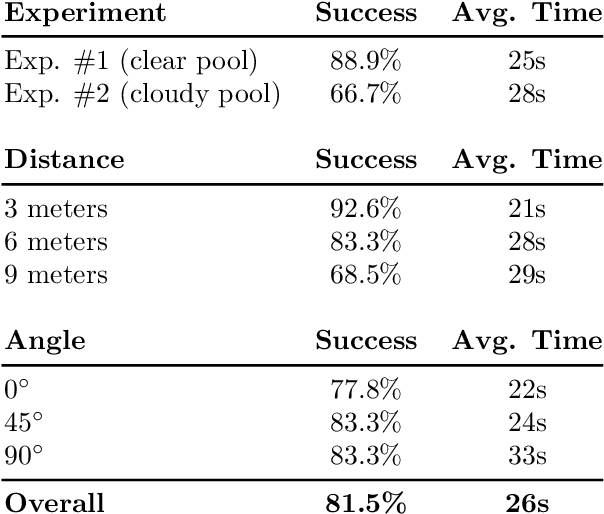
Direct communication between humans and autonomous underwater vehicles (AUVs) is a relatively underexplored area in human-robot interaction (HRI) research, although many tasks (\eg surveillance, inspection, and search-and-rescue) require close diver-robot collaboration. Many core functionalities in this domain are in need of further study to improve robotic capabilities for ease of interaction. One of these is the challenge of autonomous robots approaching and positioning themselves relative to divers to initiate and facilitate interactions. Suboptimal AUV positioning can lead to poor quality interaction and lead to excessive cognitive and physical load for divers. In this paper, we introduce a novel method for AUVs to autonomously navigate and achieve diver-relative positioning to begin interaction. Our method is based only on monocular vision, requires no global localization, and is computationally efficient. We present our algorithm along with an implementation of said algorithm on board both a simulated and physical AUV, performing extensive evaluations in the form of closed-water tests in a controlled pool. Analysis of our results show that the proposed monocular vision-based algorithm performs reliably and efficiently operating entirely on-board the AUV.
ROW-SLAM: Under-Canopy Cornfield Semantic SLAM
Sep 15, 2021

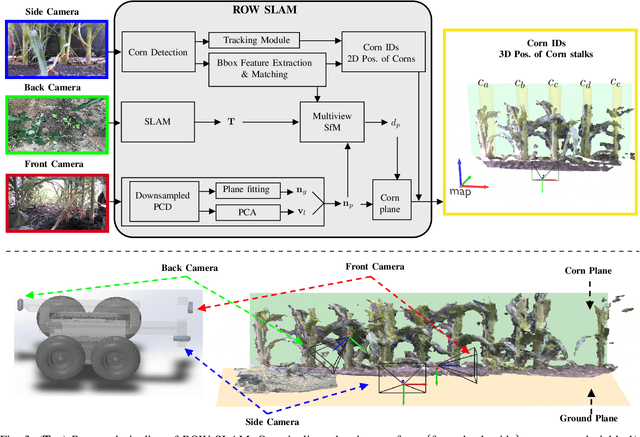
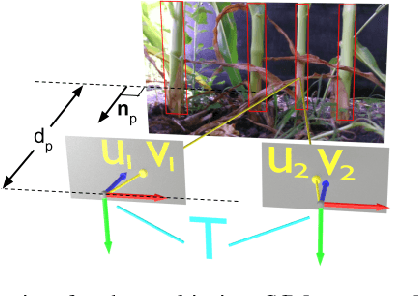
We study a semantic SLAM problem faced by a robot tasked with autonomous weeding under the corn canopy. The goal is to detect corn stalks and localize them in a global coordinate frame. This is a challenging setup for existing algorithms because there is very little space between the camera and the plants, and the camera motion is primarily restricted to be along the row. To overcome these challenges, we present a multi-camera system where a side camera (facing the plants) is used for detection whereas front and back cameras are used for motion estimation. Next, we show how semantic features in the environment (corn stalks, ground, and crop planes) can be used to develop a robust semantic SLAM solution and present results from field trials performed throughout the growing season across various cornfields.
Semantically-Aware Strategies for Stereo-Visual Robotic Obstacle Avoidance
Jul 13, 2021

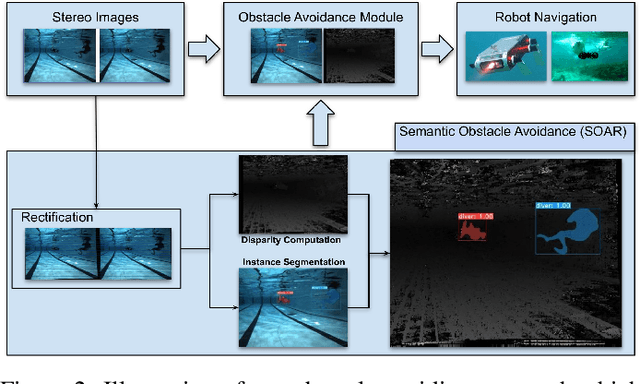
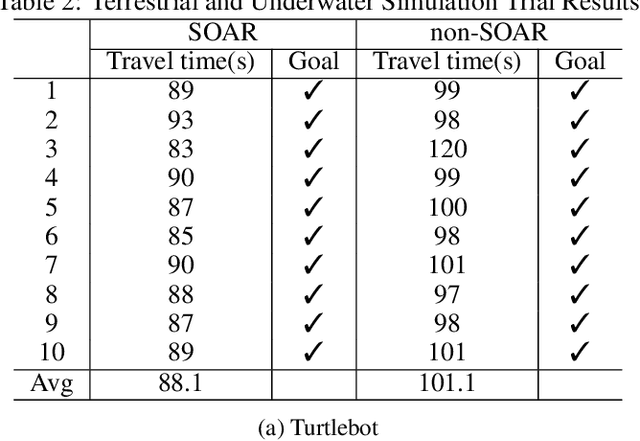
Mobile robots in unstructured, mapless environments must rely on an obstacle avoidance module to navigate safely. The standard avoidance techniques estimate the locations of obstacles with respect to the robot but are unaware of the obstacles' identities. Consequently, the robot cannot take advantage of semantic information about obstacles when making decisions about how to navigate. We propose an obstacle avoidance module that combines visual instance segmentation with a depth map to classify and localize objects in the scene. The system avoids obstacles differentially, based on the identity of the objects: for example, the system is more cautious in response to unpredictable objects such as humans. The system can also navigate closer to harmless obstacles and ignore obstacles that pose no collision danger, enabling it to navigate more efficiently. We validate our approach in two simulated environments: one terrestrial and one underwater. Results indicate that our approach is feasible and can enable more efficient navigation strategies.
Visual Diver Face Recognition for Underwater Human-Robot Interaction
Nov 18, 2020

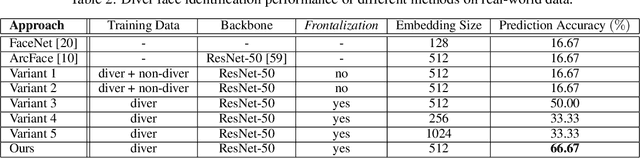
This paper presents a deep-learned facial recognition method for underwater robots to identify scuba divers. Specifically, the proposed method is able to recognize divers underwater with faces heavily obscured by scuba masks and breathing apparatus. Our contribution in this research is towards robust facial identification of individuals under significant occlusion of facial features and image degradation from underwater optical distortions. With the ability to correctly recognize divers, autonomous underwater vehicles (AUV) will be able to engage in collaborative tasks with the correct person in human-robot teams and ensure that instructions are accepted from only those authorized to command the robots. We demonstrate that our proposed framework is able to learn discriminative features from real-world diver faces through different data augmentation and generation techniques. Experimental evaluations show that this framework achieves a 3-fold increase in prediction accuracy compared to the state-of-the-art (SOTA) algorithms and is well-suited for embedded inference on robotic platforms.