 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Generative Approach for Detection-driven Underwater Image Enhancement
Dec 10, 2020
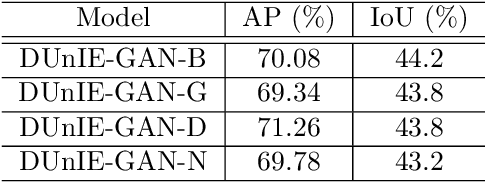

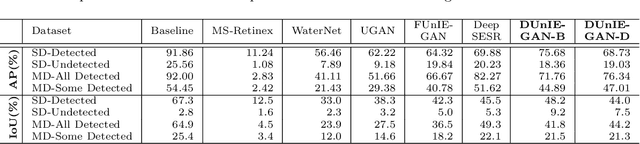
In this paper, we introduce a generative model for image enhancement specifically for improving diver detection in the underwater domain. In particular, we present a model that integrates generative adversarial network (GAN)-based image enhancement with the diver detection task. Our proposed approach restructures the GAN objective function to include information from a pre-trained diver detector with the goal to generate images which would enhance the accuracy of the detector in adverse visual conditions. By incorporating the detector output into both the generator and discriminator networks, our model is able to focus on enhancing images beyond aesthetic qualities and specifically to improve robotic detection of scuba divers. We train our network on a large dataset of scuba divers, using a state-of-the-art diver detector, and demonstrate its utility on images collected from oceanic explorations of human-robot teams. Experimental evaluations demonstrate that our approach significantly improves diver detection performance over raw, unenhanced images, and even outperforms detection performance on the output of state-of-the-art underwater image enhancement algorithms. Finally, we demonstrate the inference performance of our network on embedded devices to highlight the feasibility of operating on board mobile robotic platforms.
Visual Diver Face Recognition for Underwater Human-Robot Interaction
Nov 18, 2020
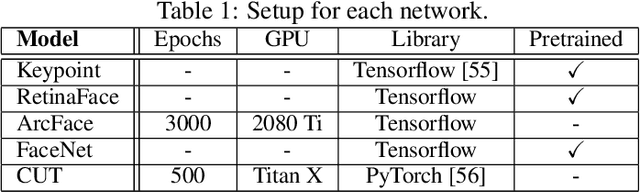

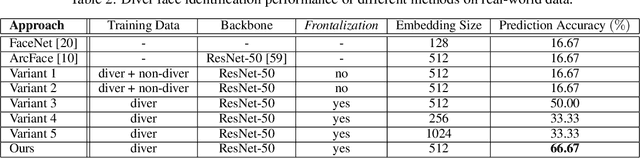
This paper presents a deep-learned facial recognition method for underwater robots to identify scuba divers. Specifically, the proposed method is able to recognize divers underwater with faces heavily obscured by scuba masks and breathing apparatus. Our contribution in this research is towards robust facial identification of individuals under significant occlusion of facial features and image degradation from underwater optical distortions. With the ability to correctly recognize divers, autonomous underwater vehicles (AUV) will be able to engage in collaborative tasks with the correct person in human-robot teams and ensure that instructions are accepted from only those authorized to command the robots. We demonstrate that our proposed framework is able to learn discriminative features from real-world diver faces through different data augmentation and generation techniques. Experimental evaluations show that this framework achieves a 3-fold increase in prediction accuracy compared to the state-of-the-art (SOTA) algorithms and is well-suited for embedded inference on robotic platforms.
Semantic Segmentation of Underwater Imagery: Dataset and Benchmark
Apr 02, 2020


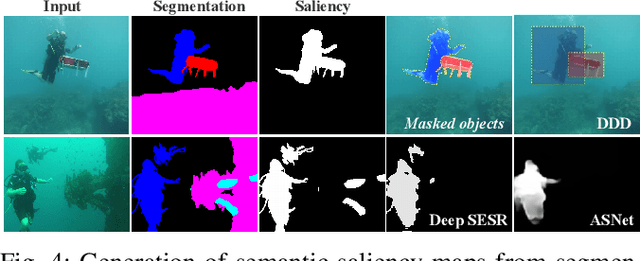
In this paper, we present the first large-scale dataset for semantic Segmentation of Underwater IMagery (SUIM). It contains over 1500 images with pixel annotations for eight object categories: fish (vertebrates), reefs (invertebrates), aquatic plants, wrecks/ruins, human divers, robots, and sea-floor. The images are rigorously collected during oceanic explorations and human-robot collaborative experiments, and annotated by human participants. We also present a comprehensive benchmark evaluation of several state-of-the-art semantic segmentation approaches based on standard performance metrics. Additionally, we present SUIM-Net, a fully-convolutional deep residual model that balances the trade-off between performance and computational efficiency. It offers competitive performance while ensuring fast end-to-end inference, which is essential for its use in the autonomy pipeline by visually-guided underwater robots. In particular, we demonstrate its usability benefits for visual servoing, saliency prediction, and detailed scene understanding. With a variety of use cases, the proposed model and benchmark dataset open up promising opportunities for future research on underwater robot vision.