 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiver Interest via Pointing in Three Dimensions: 3D Pointing Reconstruction for Diver-AUV Communication
Oct 17, 2023



This paper presents Diver Interest via Pointing in Three Dimensions (DIP-3D), a method to relay an object of interest from a diver to an autonomous underwater vehicle (AUV) by pointing that includes three-dimensional distance information to discriminate between multiple objects in the AUV's camera image. Traditional dense stereo vision for distance estimation underwater is challenging because of the relative lack of saliency of scene features and degraded lighting conditions. Yet, including distance information is necessary for robotic perception of diver pointing when multiple objects appear within the robot's image plane. We subvert the challenges of underwater distance estimation by using sparse reconstruction of keypoints to perform pose estimation on both the left and right images from the robot's stereo camera. Triangulated pose keypoints, along with a classical object detection method, enable DIP-3D to infer the location of an object of interest when multiple objects are in the AUV's field of view. By allowing the scuba diver to point at an arbitrary object of interest and enabling the AUV to autonomously decide which object the diver is pointing to, this method will permit more natural interaction between AUVs and human scuba divers in underwater-human robot collaborative tasks.
Diver Interest via Pointing: Human-Directed Object Inspection for AUVs
Dec 02, 2022In this paper, we present the Diver Interest via Pointing (DIP) algorithm, a highly modular method for conveying a diver's area of interest to an autonomous underwater vehicle (AUV) using pointing gestures for underwater human-robot collaborative tasks. DIP uses a single monocular camera and exploits human body pose, even with complete dive gear, to extract underwater human pointing gesture poses and their directions. By extracting 2D scene geometry based on the human body pose and density of salient feature points along the direction of pointing, using a low-level feature detector, the DIP algorithm is able to locate objects of interest as indicated by the diver.
A Generative Approach for Detection-driven Underwater Image Enhancement
Dec 10, 2020
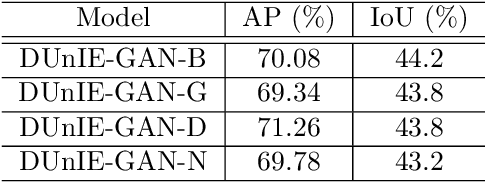

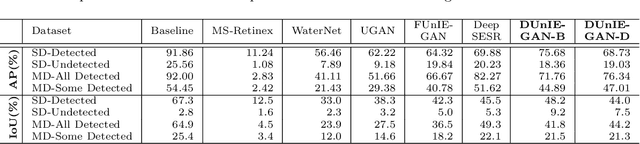
In this paper, we introduce a generative model for image enhancement specifically for improving diver detection in the underwater domain. In particular, we present a model that integrates generative adversarial network (GAN)-based image enhancement with the diver detection task. Our proposed approach restructures the GAN objective function to include information from a pre-trained diver detector with the goal to generate images which would enhance the accuracy of the detector in adverse visual conditions. By incorporating the detector output into both the generator and discriminator networks, our model is able to focus on enhancing images beyond aesthetic qualities and specifically to improve robotic detection of scuba divers. We train our network on a large dataset of scuba divers, using a state-of-the-art diver detector, and demonstrate its utility on images collected from oceanic explorations of human-robot teams. Experimental evaluations demonstrate that our approach significantly improves diver detection performance over raw, unenhanced images, and even outperforms detection performance on the output of state-of-the-art underwater image enhancement algorithms. Finally, we demonstrate the inference performance of our network on embedded devices to highlight the feasibility of operating on board mobile robotic platforms.
Semantic Segmentation of Underwater Imagery: Dataset and Benchmark
Apr 02, 2020


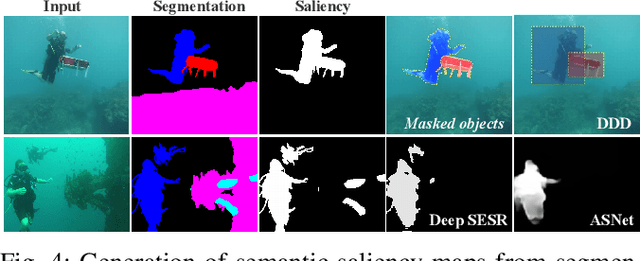
In this paper, we present the first large-scale dataset for semantic Segmentation of Underwater IMagery (SUIM). It contains over 1500 images with pixel annotations for eight object categories: fish (vertebrates), reefs (invertebrates), aquatic plants, wrecks/ruins, human divers, robots, and sea-floor. The images are rigorously collected during oceanic explorations and human-robot collaborative experiments, and annotated by human participants. We also present a comprehensive benchmark evaluation of several state-of-the-art semantic segmentation approaches based on standard performance metrics. Additionally, we present SUIM-Net, a fully-convolutional deep residual model that balances the trade-off between performance and computational efficiency. It offers competitive performance while ensuring fast end-to-end inference, which is essential for its use in the autonomy pipeline by visually-guided underwater robots. In particular, we demonstrate its usability benefits for visual servoing, saliency prediction, and detailed scene understanding. With a variety of use cases, the proposed model and benchmark dataset open up promising opportunities for future research on underwater robot vision.
Design and Experiments with LoCO AUV: A Low Cost Open-Source Autonomous Underwater Vehicle
Mar 19, 2020


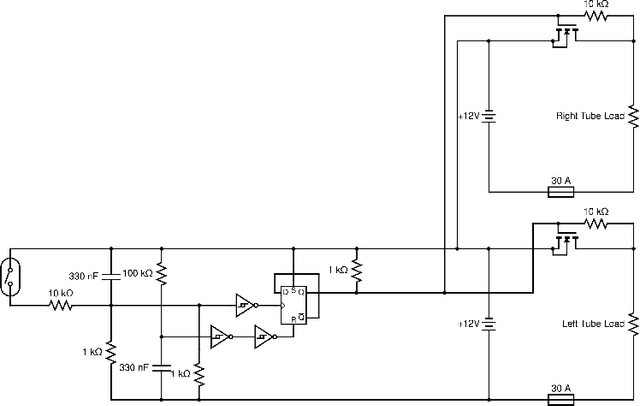
In this paper we present LoCO AUV, a Low-Cost, Open Autonomous Underwater Vehicle. LoCO is a general-purpose, single-person-deployable, vision-guided AUV, rated to a depth of 100 meters. We discuss the open and expandable design of this underwater robot, as well as the design of a simulator in Gazebo. Additionally, we explore the platform's preliminary local motion control and state estimation abilities, which enable it to perform maneuvers autonomously. In order to demonstrate its usefulness for a variety of tasks, we implement a variety of our previously presented human-robot interaction capabilities on LoCO, including gestural control, diver following, and robot communication via motion. Finally, we discuss the practical concerns of deployment and our experiences in using this robot in pools, lakes, and the ocean. All design details, instructions on assembly, and code will be released under a permissive, open-source license.
Robot Communication Via Motion: Closing the Underwater Human-Robot Interaction Loop
Sep 21, 2018

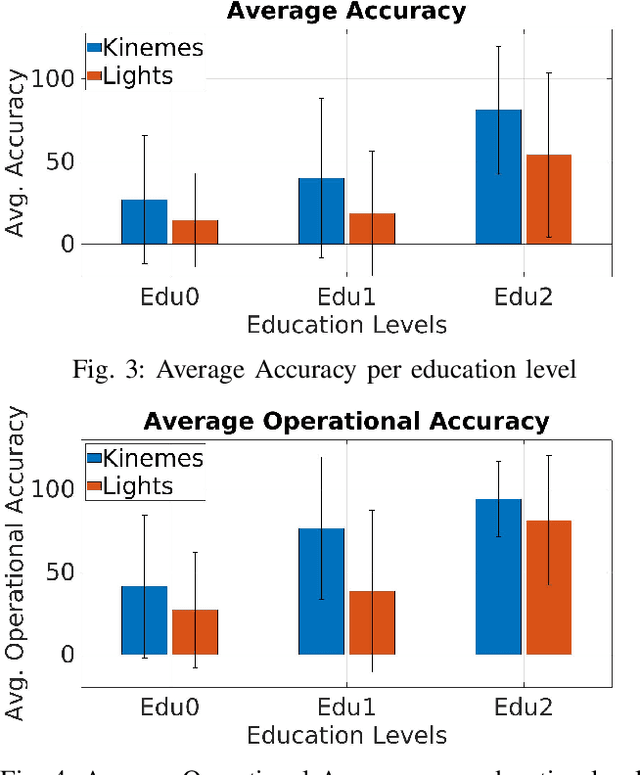
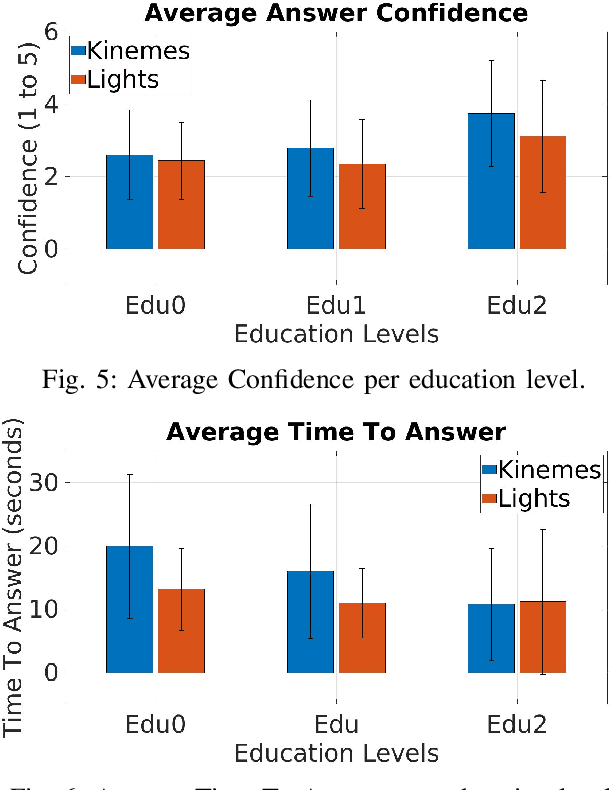
In this paper, we propose a novel method for underwater robot-to-human communication using the motion of the robot as "body language". To evaluate this system, we develop simulated examples of the system's body language gestures, called kinemes, and compare them to a baseline system using flashing colored lights through a user study. Our work shows evidence that motion can be used as a successful communication vector which is accurate, easy to learn, and quick enough to be used, all without requiring any additional hardware to be added to our platform. We thus contribute to "closing the loop" for human-robot interaction underwater by proposing and testing this system, suggesting a library of possible body language gestures for underwater robots, and offering insight on the design of nonverbal robot-to-human communication methods.