 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantically-Aware Diver Activity Recognition Framework for Effective Underwater Multi-Human-Robot Collaboration
Jun 10, 2026Effective multi-human-robot collaboration is essential for expanding human-led operations in the challenging and high-risk underwater environment. For autonomous underwater vehicles (AUVs) to become true teammates, they must be able to comprehend their surroundings and recognize a diver's activities to offer assistance and ensure safety. Towards this goal, we introduce DAR-Net, a novel transformer-based framework that analyzes complex underwater scenes to classify diver activities. Our contribution lies in a semantically guided learning formulation that couples transformer-based temporal reasoning with pixel-level scene supervision. This multi-loss training strategy explicitly aligns global activity recognition with local human-robot interaction semantics, which is particularly critical in low-visibility underwater conditions. To address the significant challenge of data scarcity in this domain, we present the first-ever Underwater Diver Activity (UDA) dataset, a foundational resource containing over 2,600 annotated images with pixel-level masks. Through rigorous experimental evaluations in a controlled environment, we demonstrate that DAR-Net achieves promising accuracy in recognizing six distinct diver activities, outperforming state-of-the-art models. While this dataset provides a crucial baseline, our work serves as a pioneering step, laying the groundwork for future research and facilitating the development of more intelligent, collaborative underwater robotic systems.
AMP2026: A Multi-Platform Marine Robotics Dataset for Tracking and Mapping
Mar 04, 2026Marine environments present significant challenges for perception and autonomy due to dynamic surfaces, limited visibility, and complex interactions between aerial, surface, and submerged sensing modalities. This paper introduces the Aerial Marine Perception Dataset (AMP2026), a multi-platform marine robotics dataset collected across multiple field deployments designed to support research in two primary areas: multi-view tracking and marine environment mapping. The dataset includes synchronized data from aerial drones, boat-mounted cameras, and submerged robotic platforms, along with associated localization and telemetry information. The goal of this work is to provide a publicly available dataset enabling research in marine perception and multi-robot observation scenarios. This paper describes the data collection methodology, sensor configurations, dataset organization, and intended research tasks supported by the dataset.
Design and Development of the MeCO Open-Source Autonomous Underwater Vehicle
Mar 13, 2025We present MeCO, the Medium Cost Open-source autonomous underwater vehicle (AUV), a versatile autonomous vehicle designed to support research and development in underwater human-robot interaction (UHRI) and marine robotics in general. An inexpensive platform to build compared to similarly-capable AUVs, the MeCO design and software are released under open-source licenses, making it a cost effective, extensible, and open platform. It is equipped with UHRI-focused systems, such as front and side facing displays, light-based communication devices, a transducer for acoustic interaction, and stereo vision, in addition to typical AUV sensing and actuation components. Additionally, MeCO is capable of real-time deep learning inference using the latest edge computing devices, while maintaining low-latency, closed-loop control through high-performance microcontrollers. MeCO is designed from the ground up for modularity in internal electronics, external payloads, and software architecture, exploiting open-source robotics and containerarization tools. We demonstrate the diverse capabilities of MeCO through simulated, closed-water, and open-water experiments. All resources necessary to build and run MeCO, including software and hardware design, have been made publicly available.
The Common Objects Underwater (COU) Dataset for Robust Underwater Object Detection
Feb 28, 2025We introduce COU: Common Objects Underwater, an instance-segmented image dataset of commonly found man-made objects in multiple aquatic and marine environments. COU contains approximately 10K segmented images, annotated from images collected during a number of underwater robot field trials in diverse locations. COU has been created to address the lack of datasets with robust class coverage curated for underwater instance segmentation, which is particularly useful for training light-weight, real-time capable detectors for Autonomous Underwater Vehicles (AUVs). In addition, COU addresses the lack of diversity in object classes since the commonly available underwater image datasets focus only on marine life. Currently, COU contains images from both closed-water (pool) and open-water (lakes and oceans) environments, of 24 different classes of objects including marine debris, dive tools, and AUVs. To assess the efficacy of COU in training underwater object detectors, we use three state-of-the-art models to evaluate its performance and accuracy, using a combination of standard accuracy and efficiency metrics. The improved performance of COU-trained detectors over those solely trained on terrestrial data demonstrates the clear advantage of training with annotated underwater images. We make COU available for broad use under open-source licenses.
IBURD: Image Blending for Underwater Robotic Detection
Feb 24, 2025We present an image blending pipeline, \textit{IBURD}, that creates realistic synthetic images to assist in the training of deep detectors for use on underwater autonomous vehicles (AUVs) for marine debris detection tasks. Specifically, IBURD generates both images of underwater debris and their pixel-level annotations, using source images of debris objects, their annotations, and target background images of marine environments. With Poisson editing and style transfer techniques, IBURD is even able to robustly blend transparent objects into arbitrary backgrounds and automatically adjust the style of blended images using the blurriness metric of target background images. These generated images of marine debris in actual underwater backgrounds address the data scarcity and data variety problems faced by deep-learned vision algorithms in challenging underwater conditions, and can enable the use of AUVs for environmental cleanup missions. Both quantitative and robotic evaluations of IBURD demonstrate the efficacy of the proposed approach for robotic detection of marine debris.
Autonomous robotic re-alignment for face-to-face underwater human-robot interaction
Jan 09, 2024
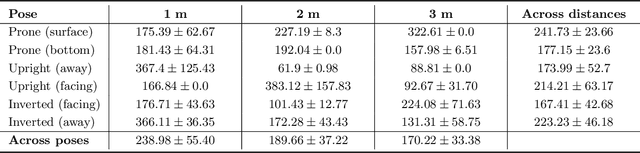

The use of autonomous underwater vehicles (AUVs) to accomplish traditionally challenging and dangerous tasks has proliferated thanks to advances in sensing, navigation, manipulation, and on-board computing technologies. Utilizing AUVs in underwater human-robot interaction (UHRI) has witnessed comparatively smaller levels of growth due to limitations in bi-directional communication and significant technical hurdles to bridge the gap between analogies with terrestrial interaction strategies and those that are possible in the underwater domain. A necessary component to support UHRI is establishing a system for safe robotic-diver approach to establish face-to-face communication that considers non-standard human body pose. In this work, we introduce a stereo vision system for enhancing UHRI that utilizes three-dimensional reconstruction from stereo image pairs and machine learning for localizing human joint estimates. We then establish a convention for a coordinate system that encodes the direction the human is facing with respect to the camera coordinate frame. This allows automatic setpoint computation that preserves human body scale and can be used as input to an image-based visual servo control scheme. We show that our setpoint computations tend to agree both quantitatively and qualitatively with experimental setpoint baselines. The methodology introduced shows promise for enhancing UHRI by improving robotic perception of human orientation underwater.
Robotic Detection and Estimation of Single Scuba Diver Respiration Rate from Underwater Video
Nov 24, 2023Human respiration rate (HRR) is an important physiological metric for diagnosing a variety of health conditions from stress levels to heart conditions. Estimation of HRR is well-studied in controlled terrestrial environments, yet robotic estimation of HRR as an indicator of diver stress in underwater for underwater human robot interaction (UHRI) scenarios is to our knowledge unexplored. We introduce a novel system for robotic estimation of HRR from underwater visual data by utilizing bubbles from exhalation cycles in scuba diving to time respiration rate. We introduce a fuzzy labeling system that utilizes audio information to label a diverse dataset of diver breathing data on which we compare four different methods for characterizing the presence of bubbles in images. Ultimately we show that our method is effective at estimating HRR by comparing the respiration rate output with human analysts.
Diver Interest via Pointing in Three Dimensions: 3D Pointing Reconstruction for Diver-AUV Communication
Oct 17, 2023



This paper presents Diver Interest via Pointing in Three Dimensions (DIP-3D), a method to relay an object of interest from a diver to an autonomous underwater vehicle (AUV) by pointing that includes three-dimensional distance information to discriminate between multiple objects in the AUV's camera image. Traditional dense stereo vision for distance estimation underwater is challenging because of the relative lack of saliency of scene features and degraded lighting conditions. Yet, including distance information is necessary for robotic perception of diver pointing when multiple objects appear within the robot's image plane. We subvert the challenges of underwater distance estimation by using sparse reconstruction of keypoints to perform pose estimation on both the left and right images from the robot's stereo camera. Triangulated pose keypoints, along with a classical object detection method, enable DIP-3D to infer the location of an object of interest when multiple objects are in the AUV's field of view. By allowing the scuba diver to point at an arbitrary object of interest and enabling the AUV to autonomously decide which object the diver is pointing to, this method will permit more natural interaction between AUVs and human scuba divers in underwater-human robot collaborative tasks.
Adaptive Landmark Color for AUV Docking in Visually Dynamic Environments
Oct 04, 2023



Autonomous Underwater Vehicles (AUVs) conduct missions underwater without the need for human intervention. A docking station (DS) can extend mission times of an AUV by providing a location for the AUV to recharge its batteries and receive updated mission information. Various methods for locating and tracking a DS exist, but most rely on expensive acoustic sensors, or are vision-based, which is significantly affected by water quality. In this \doctype, we present a vision-based method that utilizes adaptive color LED markers and dynamic color filtering to maximize landmark visibility in varying water conditions. Both AUV and DS utilize cameras to determine the water background color in order to calculate the desired marker color. No communication between AUV and DS is needed to determine marker color. Experiments conducted in a pool and lake show our method performs 10 times better than static color thresholding methods as background color varies. DS detection is possible at a range of 5 meters in clear water with minimal false positives.
Diver Identification Using Anthropometric Data Ratios for Underwater Multi-Human-Robot Collaboration
Sep 29, 2023

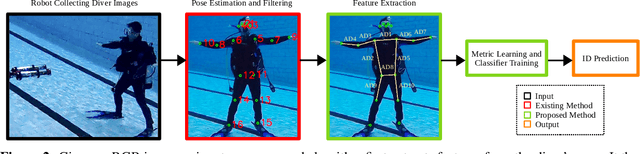
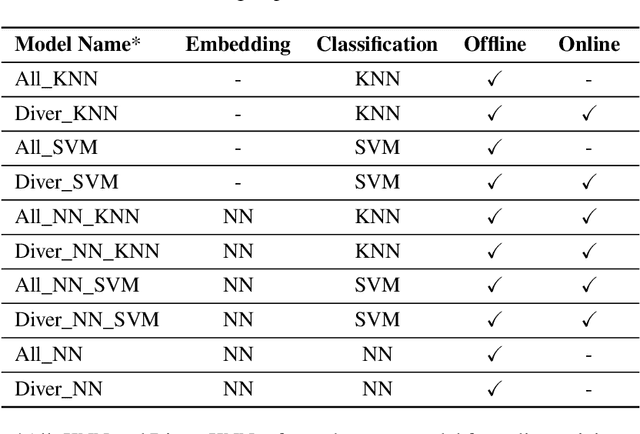
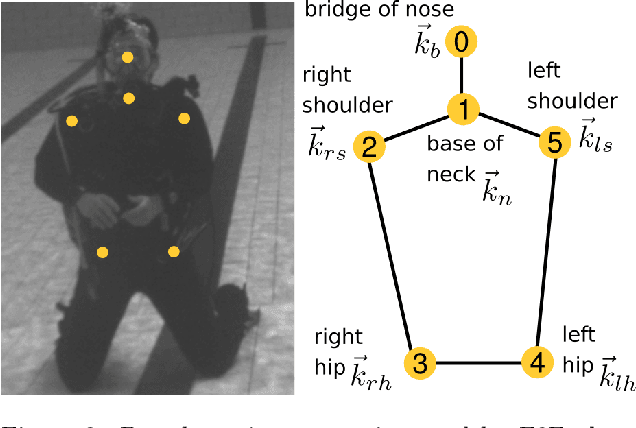
Recent advances in efficient design, perception algorithms, and computing hardware have made it possible to create improved human-robot interaction (HRI) capabilities for autonomous underwater vehicles (AUVs). To conduct secure missions as underwater human-robot teams, AUVs require the ability to accurately identify divers. However, this remains an open problem due to divers' challenging visual features, mainly caused by similar-looking scuba gear. In this paper, we present a novel algorithm that can perform diver identification using either pre-trained models or models trained during deployment. We exploit anthropometric data obtained from diver pose estimates to generate robust features that are invariant to changes in distance and photometric conditions. We also propose an embedding network that maximizes inter-class distances in the feature space and minimizes those for the intra-class features, which significantly improves classification performance. Furthermore, we present an end-to-end diver identification framework that operates on an AUV and evaluate the accuracy of the proposed algorithm. Quantitative results in controlled-water experiments show that our algorithm achieves a high level of accuracy in diver identification.