 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHREyes: Design, Development, and Evaluation of a Novel Method for AUVs to Communicate Information and Gaze Direction
Nov 05, 2022We present the design, development, and evaluation of HREyes: biomimetic communication devices which use light to communicate information and, for the first time, gaze direction from AUVs to humans. First, we introduce two types of information displays using the HREye devices: active lucemes and ocular lucemes. Active lucemes communicate information explicitly through animations, while ocular lucemes communicate gaze direction implicitly by mimicking human eyes. We present a human study in which our system is compared to the use of an embedded digital display that explicitly communicates information to a diver by displaying text. Our results demonstrate accurate recognition of active lucemes for trained interactants, limited intuitive understanding of these lucemes for untrained interactants, and relatively accurate perception of gaze direction for all interactants. The results on active luceme recognition demonstrate more accurate recognition than previous light-based communication systems for AUVs (albeit with different phrase sets). Additionally, the ocular lucemes we introduce in this work represent the first method for communicating gaze direction from an AUV, a critical aspect of nonverbal communication used in collaborative work. With readily available hardware as well as open-source and easily re-configurable programming, HREyes can be easily integrated into any AUV with the physical space for the devices and used to communicate effectively with divers in any underwater environment with appropriate visibility.
Robotic Detection of a Human-Comprehensible Gestural Language for Underwater Multi-Human-Robot Collaboration
Jul 12, 2022
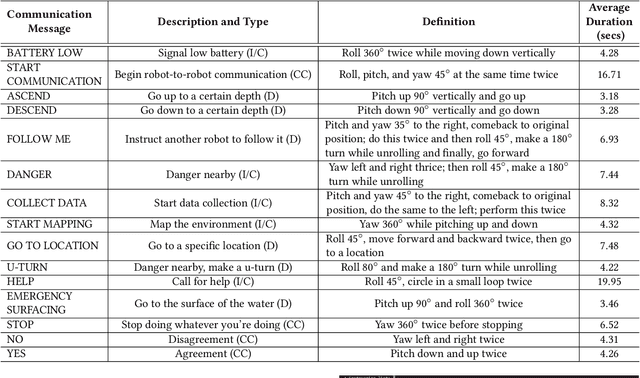

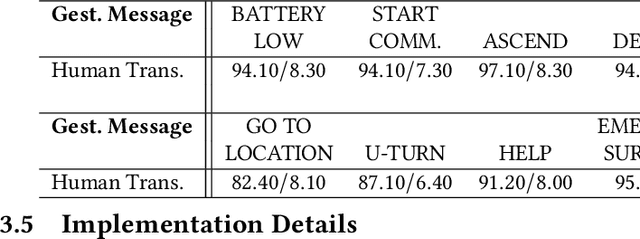
In this paper, we present a motion-based robotic communication framework that enables non-verbal communication among autonomous underwater vehicles (AUVs) and human divers. We design a gestural language for AUV-to-AUV communication which can be easily understood by divers observing the conversation unlike typical radio frequency, light, or audio based AUV communication. To allow AUVs to visually understand a gesture from another AUV, we propose a deep network (RRCommNet) which exploits a self-attention mechanism to learn to recognize each message by extracting maximally discriminative spatio-temporal features. We train this network on diverse simulated and real-world data. Our experimental evaluations, both in simulation and in closed-water robot trials, demonstrate that the proposed RRCommNet architecture is able to decipher gesture-based messages with an average accuracy of 88-94% on simulated data, 73-83% on real data (depending on the version of the model used). Further, by performing a message transcription study with human participants, we also show that the proposed language can be understood by humans, with an overall transcription accuracy of 88%. Finally, we discuss the inference runtime of RRCommNet on embedded GPU hardware, for real-time use on board AUVs in the field.
Using Monocular Vision and Human Body Priors for AUVs to Autonomously Approach Divers
Nov 05, 2021

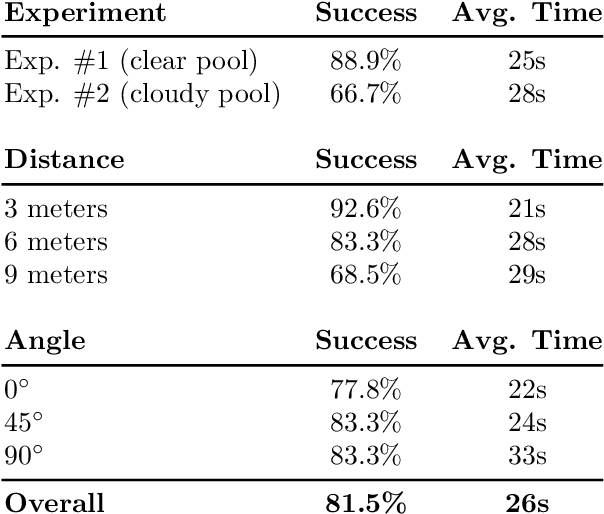
Direct communication between humans and autonomous underwater vehicles (AUVs) is a relatively underexplored area in human-robot interaction (HRI) research, although many tasks (\eg surveillance, inspection, and search-and-rescue) require close diver-robot collaboration. Many core functionalities in this domain are in need of further study to improve robotic capabilities for ease of interaction. One of these is the challenge of autonomous robots approaching and positioning themselves relative to divers to initiate and facilitate interactions. Suboptimal AUV positioning can lead to poor quality interaction and lead to excessive cognitive and physical load for divers. In this paper, we introduce a novel method for AUVs to autonomously navigate and achieve diver-relative positioning to begin interaction. Our method is based only on monocular vision, requires no global localization, and is computationally efficient. We present our algorithm along with an implementation of said algorithm on board both a simulated and physical AUV, performing extensive evaluations in the form of closed-water tests in a controlled pool. Analysis of our results show that the proposed monocular vision-based algorithm performs reliably and efficiently operating entirely on-board the AUV.
An Analysis of Deep Object Detectors For Diver Detection
Nov 25, 2020
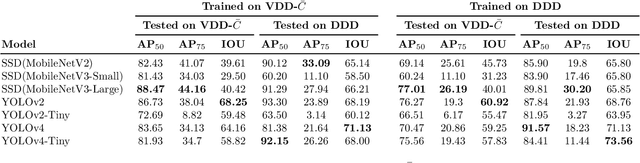

With the end goal of selecting and using diver detection models to support human-robot collaboration capabilities such as diver following, we thoroughly analyze a large set of deep neural networks for diver detection. We begin by producing a dataset of approximately 105,000 annotated images of divers sourced from videos -- one of the largest and most varied diver detection datasets ever created. Using this dataset, we train a variety of state-of-the-art deep neural networks for object detection, including SSD with Mobilenet, Faster R-CNN, and YOLO. Along with these single-frame detectors, we also train networks designed for detection of objects in a video stream, using temporal information as well as single-frame image information. We evaluate these networks on typical accuracy and efficiency metrics, as well as on the temporal stability of their detections. Finally, we analyze the failures of these detectors, pointing out the most common scenarios of failure. Based on our results, we recommend SSDs or Tiny-YOLOv4 for real-time applications on robots and recommend further investigation of video object detection methods.
TrashCan: A Semantically-Segmented Dataset towards Visual Detection of Marine Debris
Jul 16, 2020


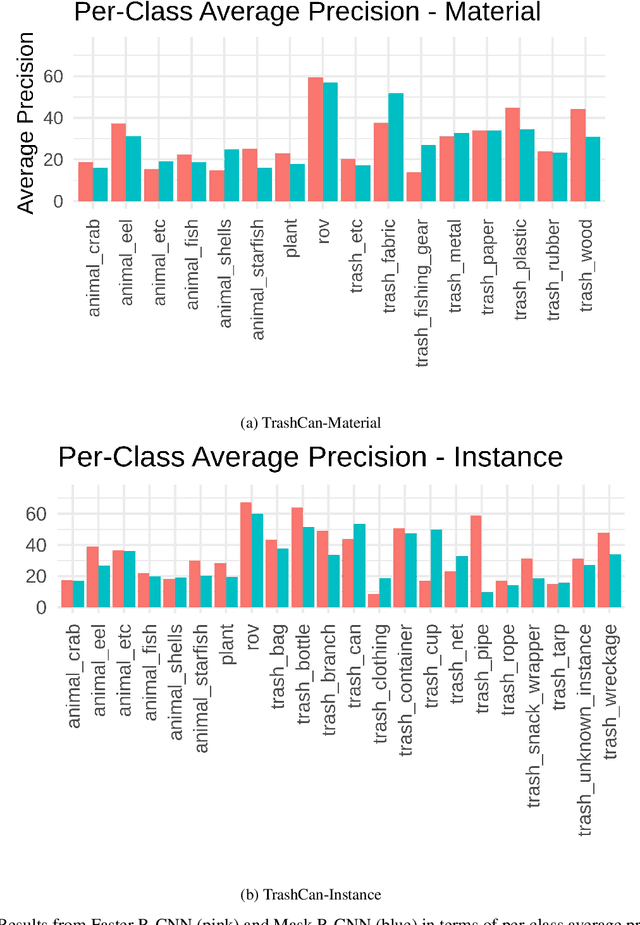
This paper presents TrashCan, a large dataset comprised of images of underwater trash collected from a variety of sources, annotated both using bounding boxes and segmentation labels, for development of robust detectors of marine debris. The dataset has two versions, TrashCan-Material and TrashCan-Instance, corresponding to different object class configurations. The eventual goal is to develop efficient and accurate trash detection methods suitable for onboard robot deployment. Along with information about the construction and sourcing of the TrashCan dataset, we present initial results of instance segmentation from Mask R-CNN and object detection from Faster R-CNN. These do not represent the best possible detection results but provides an initial baseline for future work in instance segmentation and object detection on the TrashCan dataset.
Design and Experiments with LoCO AUV: A Low Cost Open-Source Autonomous Underwater Vehicle
Mar 19, 2020


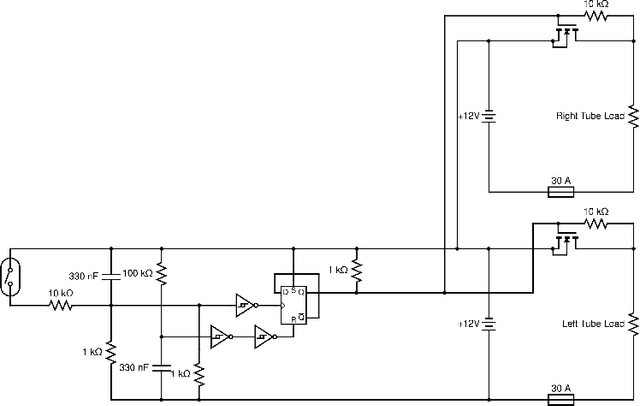
In this paper we present LoCO AUV, a Low-Cost, Open Autonomous Underwater Vehicle. LoCO is a general-purpose, single-person-deployable, vision-guided AUV, rated to a depth of 100 meters. We discuss the open and expandable design of this underwater robot, as well as the design of a simulator in Gazebo. Additionally, we explore the platform's preliminary local motion control and state estimation abilities, which enable it to perform maneuvers autonomously. In order to demonstrate its usefulness for a variety of tasks, we implement a variety of our previously presented human-robot interaction capabilities on LoCO, including gestural control, diver following, and robot communication via motion. Finally, we discuss the practical concerns of deployment and our experiences in using this robot in pools, lakes, and the ocean. All design details, instructions on assembly, and code will be released under a permissive, open-source license.
A Generative Approach Towards Improved Robotic Detection of Marine Litter
Oct 10, 2019

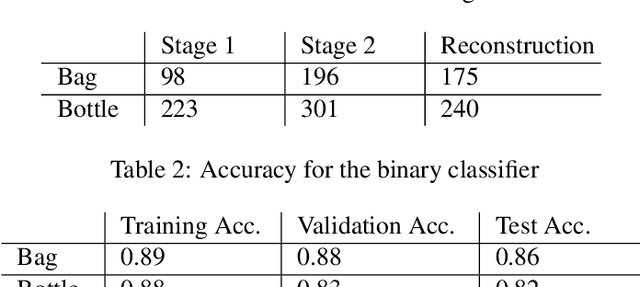
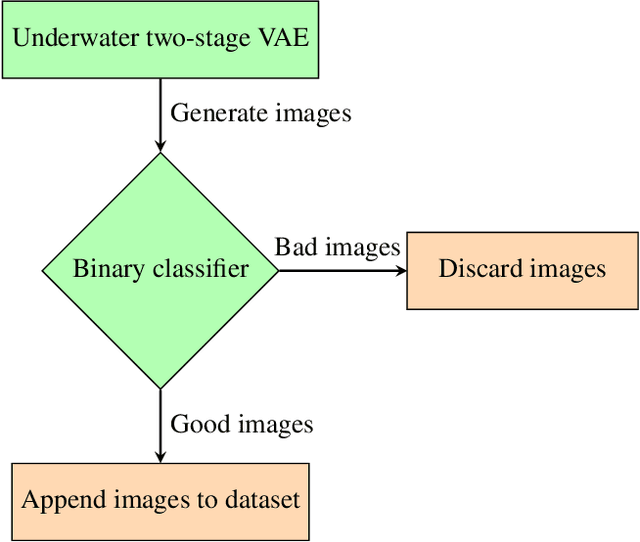
This paper presents an approach to address data scarcity problems in underwater image datasets for visual detection of marine debris. The proposed approach relies on a two-stage variational autoencoder (VAE) and a binary classifier to evaluate the generated imagery for quality and realism. From the images generated by the two-stage VAE, the binary classifier selects "good quality" images and augments the given dataset with them. Lastly, a multi-class classifier is used to evaluate the impact of the augmentation process by measuring the accuracy of an object detector trained on combinations of real and generated trash images. Our results show that the classifier trained with the augmented data outperforms the one trained only with the real data. This approach will not only be valid for the underwater trash classification problem presented in this paper, but it will also be useful for any data-dependent task for which collecting more images is challenging or infeasible.
An Evaluation of Bayesian Methods for Bathymetry-based Localization of Autonomous Underwater Robots
Mar 26, 2019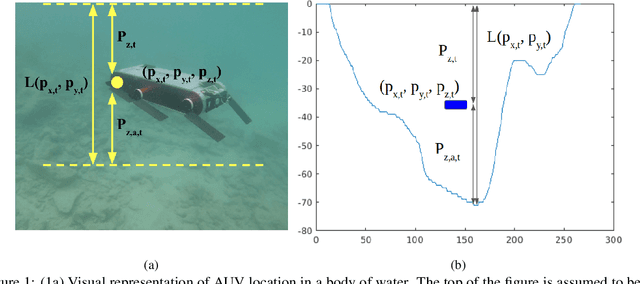

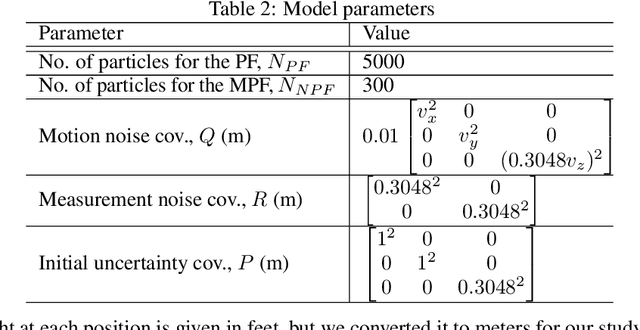
This paper presents an evaluation of a number of probabilistic algorithms for localization of autonomous underwater vehicles (AUVs) using bathymetry data. The algorithms, based on the principles of the Bayes filter, work by fusing bathymetry information with depth and altitude data from an AUV. Four different Bayes filter-based algorithms are used to design the localization algorithms: the Extended Kalman Filter (EKF), Unscented Kalman Filter (UKF), Particle Filter (PF), and Marginalized Particle Filter (MPF). We evaluate the performance of these four Bayesian bathymetry-based AUV localization approaches under variable conditions and available computational resources. The localization algorithms overcome unique challenges of the underwater domain, including visual distortion and radio frequency (RF) signal attenuation, which often make landmark-based localization infeasible. Evaluation results on real-world bathymetric data show the effectiveness of each algorithm under a variety of conditions, with the MPF being the most accurate.
By Land, Air, or Sea: Multi-Domain Robot Communication Via Motion
Mar 07, 2019

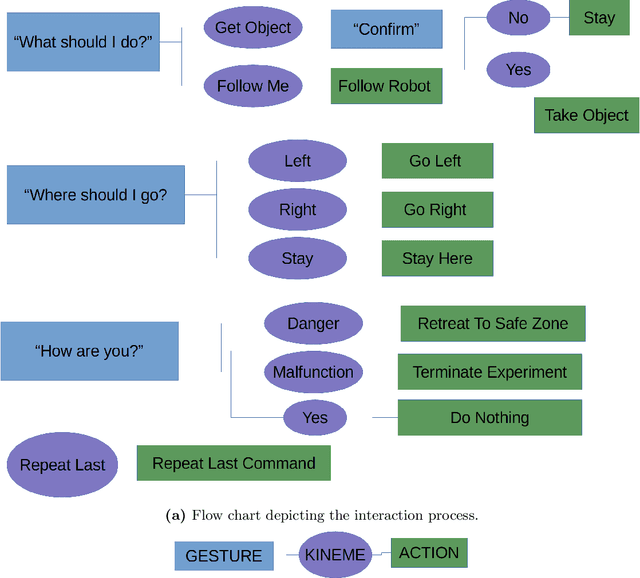
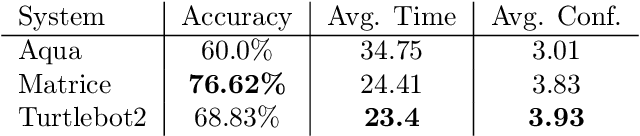
In this paper, we explore the use of motion for robot-to-human communication on three robotic platforms: the 5 degrees-of-freedom (DOF) Aqua autonomous underwater vehicle (AUV), a 3-DOF camera gimbal mounted on a Matrice 100 drone, and a 3-DOF Turtlebot2 terrestrial robot. While we previously explored the use of body language-like motion (called kinemes) versus other methods of communication for the Aqua AUV, we now extend those concepts to robots in two new and different domains. We evaluate all three platforms using a small interaction study where participants use gestures to communicate with the robot, receive information from the robot via kinemes, and then take actions based on the information. To compare the three domains we consider the accuracy of these interactions, the time it takes to complete them, and how confident users feel in the success of their interactions. The kineme systems perform with reasonable accuracy for all robots and experience gained in this study is used to form a set of prescriptions for further development of kineme systems.
Robot Communication Via Motion: Closing the Underwater Human-Robot Interaction Loop
Sep 21, 2018

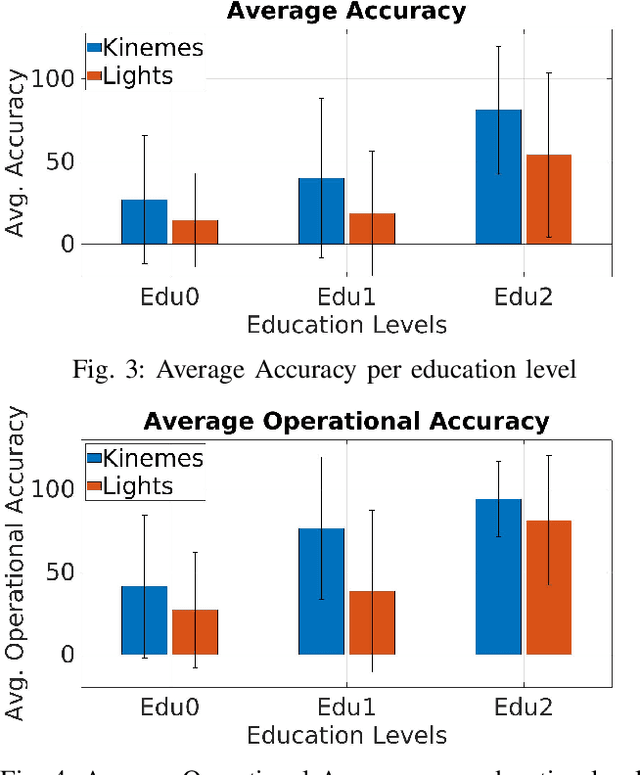
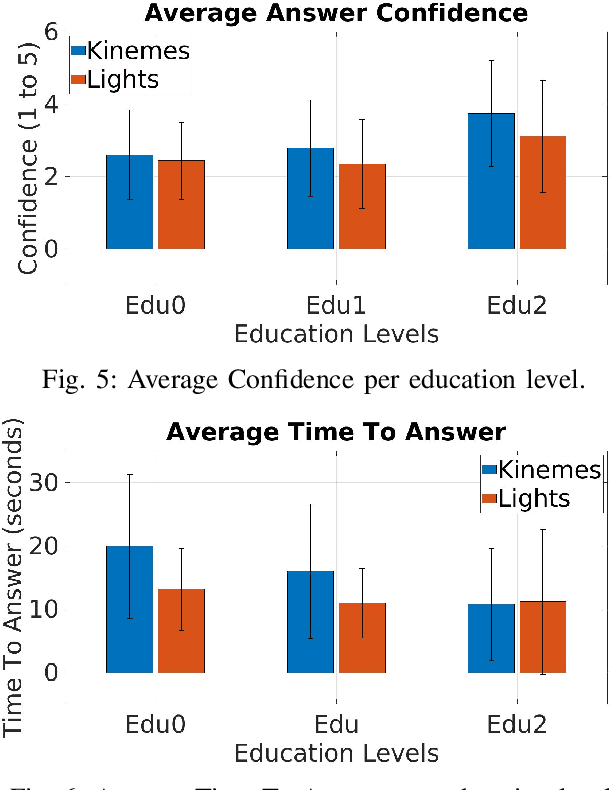
In this paper, we propose a novel method for underwater robot-to-human communication using the motion of the robot as "body language". To evaluate this system, we develop simulated examples of the system's body language gestures, called kinemes, and compare them to a baseline system using flashing colored lights through a user study. Our work shows evidence that motion can be used as a successful communication vector which is accurate, easy to learn, and quick enough to be used, all without requiring any additional hardware to be added to our platform. We thus contribute to "closing the loop" for human-robot interaction underwater by proposing and testing this system, suggesting a library of possible body language gestures for underwater robots, and offering insight on the design of nonverbal robot-to-human communication methods.