 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantically-Aware Diver Activity Recognition Framework for Effective Underwater Multi-Human-Robot Collaboration
Jun 10, 2026Effective multi-human-robot collaboration is essential for expanding human-led operations in the challenging and high-risk underwater environment. For autonomous underwater vehicles (AUVs) to become true teammates, they must be able to comprehend their surroundings and recognize a diver's activities to offer assistance and ensure safety. Towards this goal, we introduce DAR-Net, a novel transformer-based framework that analyzes complex underwater scenes to classify diver activities. Our contribution lies in a semantically guided learning formulation that couples transformer-based temporal reasoning with pixel-level scene supervision. This multi-loss training strategy explicitly aligns global activity recognition with local human-robot interaction semantics, which is particularly critical in low-visibility underwater conditions. To address the significant challenge of data scarcity in this domain, we present the first-ever Underwater Diver Activity (UDA) dataset, a foundational resource containing over 2,600 annotated images with pixel-level masks. Through rigorous experimental evaluations in a controlled environment, we demonstrate that DAR-Net achieves promising accuracy in recognizing six distinct diver activities, outperforming state-of-the-art models. While this dataset provides a crucial baseline, our work serves as a pioneering step, laying the groundwork for future research and facilitating the development of more intelligent, collaborative underwater robotic systems.
Diver Identification Using Anthropometric Data Ratios for Underwater Multi-Human-Robot Collaboration
Sep 29, 2023

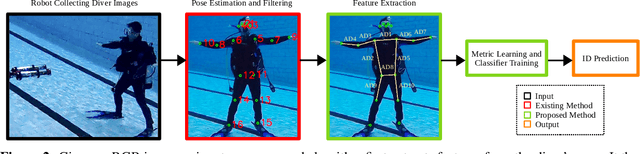
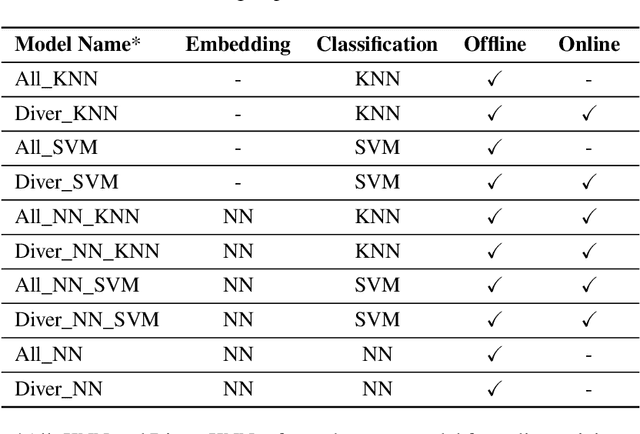
Recent advances in efficient design, perception algorithms, and computing hardware have made it possible to create improved human-robot interaction (HRI) capabilities for autonomous underwater vehicles (AUVs). To conduct secure missions as underwater human-robot teams, AUVs require the ability to accurately identify divers. However, this remains an open problem due to divers' challenging visual features, mainly caused by similar-looking scuba gear. In this paper, we present a novel algorithm that can perform diver identification using either pre-trained models or models trained during deployment. We exploit anthropometric data obtained from diver pose estimates to generate robust features that are invariant to changes in distance and photometric conditions. We also propose an embedding network that maximizes inter-class distances in the feature space and minimizes those for the intra-class features, which significantly improves classification performance. Furthermore, we present an end-to-end diver identification framework that operates on an AUV and evaluate the accuracy of the proposed algorithm. Quantitative results in controlled-water experiments show that our algorithm achieves a high level of accuracy in diver identification.
Visual Detection of Diver Attentiveness for Underwater Human-Robot Interaction
Sep 28, 2022
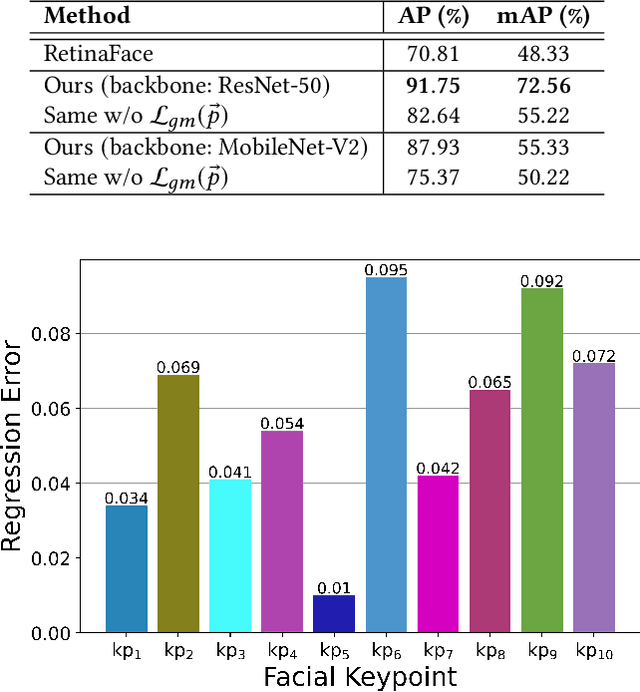


Many underwater tasks, such as cable-and-wreckage inspection, search-and-rescue, benefit from robust human-robot interaction (HRI) capabilities. With the recent advancements in vision-based underwater HRI methods, autonomous underwater vehicles (AUVs) can communicate with their human partners even during a mission. However, these interactions usually require active participation especially from humans (e.g., one must keep looking at the robot during an interaction). Therefore, an AUV must know when to start interacting with a human partner, i.e., if the human is paying attention to the AUV or not. In this paper, we present a diver attention estimation framework for AUVs to autonomously detect the attentiveness of a diver and then navigate and reorient itself, if required, with respect to the diver to initiate an interaction. The core element of the framework is a deep neural network (called DATT-Net) which exploits the geometric relation among 10 facial keypoints of the divers to determine their head orientation. Our on-the-bench experimental evaluations (using unseen data) demonstrate that the proposed DATT-Net architecture can determine the attentiveness of human divers with promising accuracy. Our real-world experiments also confirm the efficacy of DATT-Net which enables real-time inference and allows the AUV to position itself for an AUV-diver interaction.
Robotic Detection of a Human-Comprehensible Gestural Language for Underwater Multi-Human-Robot Collaboration
Jul 12, 2022
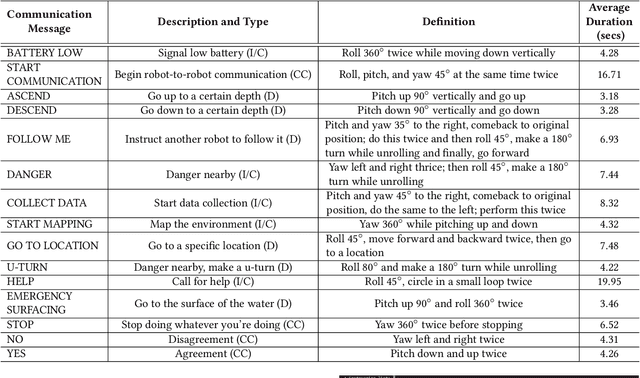

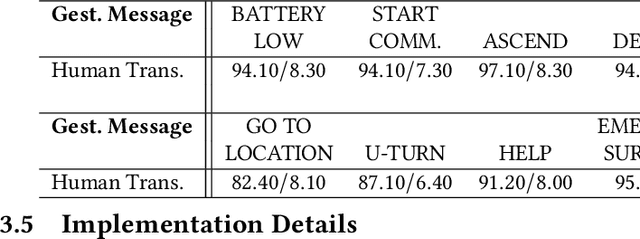
In this paper, we present a motion-based robotic communication framework that enables non-verbal communication among autonomous underwater vehicles (AUVs) and human divers. We design a gestural language for AUV-to-AUV communication which can be easily understood by divers observing the conversation unlike typical radio frequency, light, or audio based AUV communication. To allow AUVs to visually understand a gesture from another AUV, we propose a deep network (RRCommNet) which exploits a self-attention mechanism to learn to recognize each message by extracting maximally discriminative spatio-temporal features. We train this network on diverse simulated and real-world data. Our experimental evaluations, both in simulation and in closed-water robot trials, demonstrate that the proposed RRCommNet architecture is able to decipher gesture-based messages with an average accuracy of 88-94% on simulated data, 73-83% on real data (depending on the version of the model used). Further, by performing a message transcription study with human participants, we also show that the proposed language can be understood by humans, with an overall transcription accuracy of 88%. Finally, we discuss the inference runtime of RRCommNet on embedded GPU hardware, for real-time use on board AUVs in the field.
Visual Diver Face Recognition for Underwater Human-Robot Interaction
Nov 18, 2020

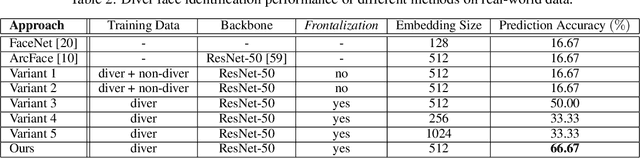
This paper presents a deep-learned facial recognition method for underwater robots to identify scuba divers. Specifically, the proposed method is able to recognize divers underwater with faces heavily obscured by scuba masks and breathing apparatus. Our contribution in this research is towards robust facial identification of individuals under significant occlusion of facial features and image degradation from underwater optical distortions. With the ability to correctly recognize divers, autonomous underwater vehicles (AUV) will be able to engage in collaborative tasks with the correct person in human-robot teams and ensure that instructions are accepted from only those authorized to command the robots. We demonstrate that our proposed framework is able to learn discriminative features from real-world diver faces through different data augmentation and generation techniques. Experimental evaluations show that this framework achieves a 3-fold increase in prediction accuracy compared to the state-of-the-art (SOTA) algorithms and is well-suited for embedded inference on robotic platforms.
Semantic Segmentation of Underwater Imagery: Dataset and Benchmark
Apr 02, 2020


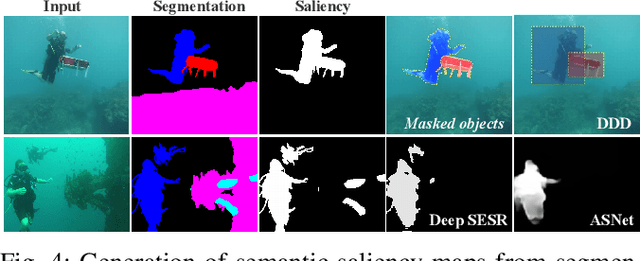
In this paper, we present the first large-scale dataset for semantic Segmentation of Underwater IMagery (SUIM). It contains over 1500 images with pixel annotations for eight object categories: fish (vertebrates), reefs (invertebrates), aquatic plants, wrecks/ruins, human divers, robots, and sea-floor. The images are rigorously collected during oceanic explorations and human-robot collaborative experiments, and annotated by human participants. We also present a comprehensive benchmark evaluation of several state-of-the-art semantic segmentation approaches based on standard performance metrics. Additionally, we present SUIM-Net, a fully-convolutional deep residual model that balances the trade-off between performance and computational efficiency. It offers competitive performance while ensuring fast end-to-end inference, which is essential for its use in the autonomy pipeline by visually-guided underwater robots. In particular, we demonstrate its usability benefits for visual servoing, saliency prediction, and detailed scene understanding. With a variety of use cases, the proposed model and benchmark dataset open up promising opportunities for future research on underwater robot vision.
Design and Experiments with LoCO AUV: A Low Cost Open-Source Autonomous Underwater Vehicle
Mar 19, 2020


In this paper we present LoCO AUV, a Low-Cost, Open Autonomous Underwater Vehicle. LoCO is a general-purpose, single-person-deployable, vision-guided AUV, rated to a depth of 100 meters. We discuss the open and expandable design of this underwater robot, as well as the design of a simulator in Gazebo. Additionally, we explore the platform's preliminary local motion control and state estimation abilities, which enable it to perform maneuvers autonomously. In order to demonstrate its usefulness for a variety of tasks, we implement a variety of our previously presented human-robot interaction capabilities on LoCO, including gestural control, diver following, and robot communication via motion. Finally, we discuss the practical concerns of deployment and our experiences in using this robot in pools, lakes, and the ocean. All design details, instructions on assembly, and code will be released under a permissive, open-source license.
Underwater Image Super-Resolution using Deep Residual Multipliers
Sep 20, 2019

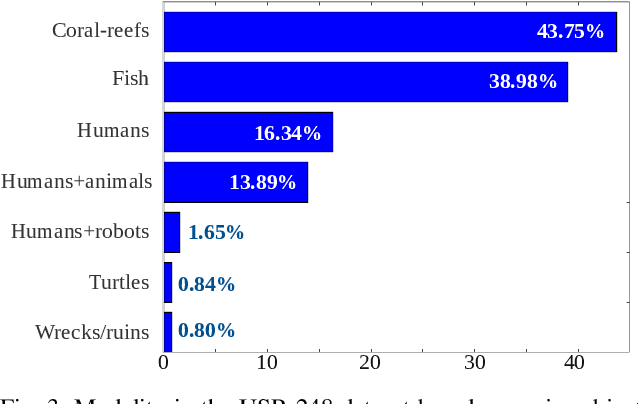
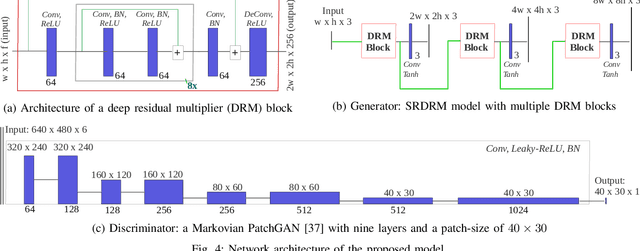
We present a deep residual network-based generative model for single image super-resolution (SISR) of underwater imagery for use by autonomous underwater robots. We also provide an adversarial training pipeline for learning SISR from paired data. In order to supervise the training, we formulate an objective function that evaluates the perceptual quality of an image based on its global content, color, and local style information. Additionally, we present USR-248, a large-scale dataset of three sets of underwater images of high (640x480) and low (80x60, 160x120, and 320x240) resolution. USR-248 contains over 7K paired instances in each set of data for supervised training of 2x, 4x, or 8x SISR models. Furthermore, we validate the effectiveness of our proposed model through qualitative and quantitative experiments and compare the results with several state-of-the-art models' performances. We also analyze its practical feasibility for applications such as scene understanding and attention modeling in noisy visual conditions.